




在企业开始使用数据的时候,就不得不面临如下的问题:
需要的数据在哪里?
关于数据的描述是什么?
数据的质量怎么样?
不同的数据集之间的关系是什么?
数据的收集和使用是否合规?
数据的访问是否能被控制,是否能保证安全不被泄露?
所有这些问题都与一个非常重要的领域-数据治理有关。而在数据治理中,数据目录则是解决发现和查找数据,以及维护数据集之间关系的一个重要的组成部分。今天我们就来看看现代数据技术栈中的数据目录相关的产品。
在一个企业中,数据目录(Data Catalog)是一个用于维护企业数据资产的元数据信息的一个系统。通过数据目录,企业的数据使用者或者数据系统可以方便发现数据、查找数据、理解数据以及使用数据。
通常来讲,企业开始使用数据的时候,首先想到的就是自己有哪些数据可以被使用。正是因为这个最基本的需求,促进了数据目录相关产品的产生。因此数据目录并不是一个新的概念,数据目录相关的产品在传统软件时代就已经有不少了,比如Informatica, Talend等等公司的产品。我们今天重点还是介绍在现代数据技术栈中的数据目录相关的产品。
在towards data science上,Atlan的联合创始人Prukalpa有一篇博客文章,把现代数据技术栈中的数据目录产品成为数据目录3.0。下面我们先来看看她如何定义数据目录1.0、2.0和3.0.
数据目录1.0 - 面向IT团队的元数据管理
时间阶段:1990年代-2000年代
代表产品:Informatic, Talend
在90年代,随着BI项目在一些大型企业开始落地,这些企业开始关心如何组织好自己在不同业务系统中产生的数据,从而方便数据的使用。在这个时期,由于数据都是不同IT系统产生,因此组织管理这些数据的职责就变成了IT团队的职责。IT团队希望有工具能帮助自己去维护和管理公司已有的数据表的清单,以及这些数据库表的元数据。Informatica就是在这种需求场景下产生的。这个时期的工具主要面向的团队就是企业的IT团队,而面向的数据则是企业内部不同业务系统的数据库中的数据库表。
数据目录2.0 - 数据管理员操作的数据清单产品
时间阶段:2010年代
代表产品:Collibra, Alation
我自己开始比较深入地了解数据目录产品就是在这个阶段。我在2013年开始尝试用公司的数据做一些数据应用产品。在使用数据越来越多的时候发现公司的数据需要有个数据集的列表,并且希望知道数据从采集进来,到加工到最终数据应用产品的时候的整个数据世系,以及每个阶段的每个数据集的数据分布。2016年我们团队开始做公司内部的元数据管理系统以及数据血缘系统,并且也对海外相关的数据目录产品做过一些调研。Collibra和Alation都是当时调研过的产品。从最新的估值看,Collibra估值已经超过50亿美金,Alation也已经是独角兽规模的公司。
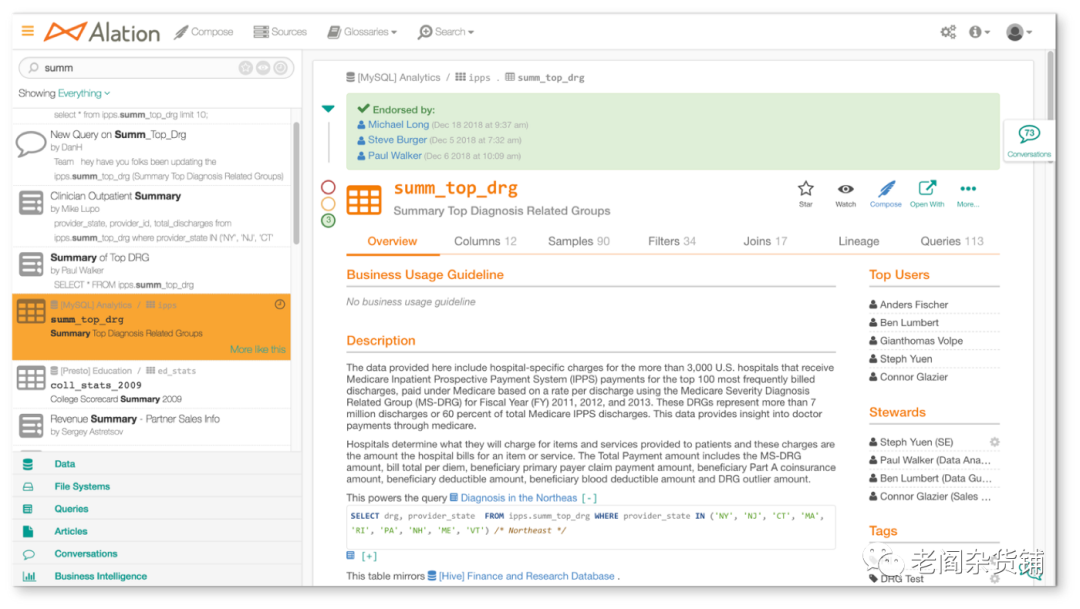
Alation的操作界面
在这个阶段,数据的主导权逐渐从IT团队向数据团队过渡。很多公司都开始有了自己的首席数据官(CDO)。在数据团队中,也开始有更细的分工。数据管理员、数据分析师、数据科学家、数据工程师、数据产品经理等等角色分别承担不同的职能。我当时带领的数据科学部基本上就包含了所有的这些角色的人员。
在这个阶段,企业使用的数据的种类也在发生变化。越来越多的不同类型的数据开始被企业收集和利用,比如用户行为数据,广告投放的媒体数据等等。对于这些数据进行元数据管理并且维护实际上是比较困难的,主要是数据不稳定,结构也会经常变化。数据目录中如何保证元数据的信息和真实的数据情况一致非常的挑战。由于很多数据加工过程都已经是采用Hadoop或者Spark等等计算平台来完成,当时已经有一些开源希望通过采集这些日志来自动形成数据目录以及数据世系。比如LinkedIn的DataHub(最初我开始调研的时候叫做Wherehows),Airbnb的Dataportal, Uber的Databook以及Lyft的Amundsen等等。
这些产品能解决企业的问题,但是要求企业具有非常强的数据团队才行,搭建和维护一个这种数据目录平台代价不低。
数据目录3.0 - 面向不同数据用户的支持协作的数据目录工具
时间阶段:现在
代表产品:Atlan, Stemma, Acryl Data, Secoda,Metahpor Data
随着企业使用数据的场景越来越丰富,另外数据技术栈也从私有化部署开始向公有云迁移。数据目录产品进入到了新的阶段,也就是3.0阶段。在这个阶段,数据目录产品的目标用户开始变成了企业使用数据的所有人。同时,因为是面向不同的角色,因此新的数据目录产品都需要支持不同角色的协同。就像设计领域的Figma,以及在线文档Notion一样。
数据目录3.0的产品一般具备如下的一些特点:
管理的对象从数据库表变为数据集
在1.0时代,所有的管理的对象都是数据库表。在2.0时代,虽然已经有数据集的概念,但是大部分的对象还是数据库表。但是3.0时代,数据的种类越来越丰富,因此数据集已经是管理的对象。数据集包括数据库表,也包括各种不同类型的半结构化、非结构化数据。
端到端的数据可见性
在数据目录3.0时代,数据目录树提供企业所有人一个唯一可以信任的中心数据目录。不同的角色可以通过不同的授权,访问数据目录。
数据目录本身就是一个大数据产品
在数据目录3.0时代,所有的数据都会被管理、被查看以及被搜索。比如搜索日志、数据处理日志也会被数据目录产品管理和使用。这意味着数据目录产品本身就是一个大数据的产品。而且数据目录从传统的列表查看逐渐变为了可以被搜索、分析。
天然支持协同
数据目录不再仅仅是一个单一角色来维护管理的企业的数据资产目录,而是不同的角色参与共同建设的公司的数据资产平台。通过支持协同,就类似于github一样,所有人都可以根据权限和角色去维护企业的数据目录。这样才能让企业的数据资产变成一个集体智慧的产物。
Atlan
公司官网:https://www.atlan.com
成立时间:2018年
公司所在地:印度
创始人:Prukalpa Sankar,Varun Banka
融资额:一共三轮融资,总额6900万美金
2019年7月 种子轮 250万美金 Waterbridge领投
2021年5月 A轮 1650万美金 Insight Partners领投
2022年2月 B轮 5000万美金 红杉印度领投
近几年,美国的高科技公司,印度裔的高管基本上处于绝对领先的地位。微软、谷歌的老大现在都是印度裔,而且公司运转都非常好。除了在硅谷作为成熟企业的高管,硅谷创业的印度裔也不少。另外,在印度本土,也有不少新的创业公司开始直接全球化,并取得了不错的结果。在数据领域里的Atlan就是其中的一个。
Atlan的创始人Prukalpa是一个女性创业者,也是一个明星创业者。多次入选福布斯的30under30以及40under40,并且在medium上有超过3600个关注者,是一个影响力达人。
虽然在印度成立,但是Atlan一开始就是积极融入到现代数据技术栈中。Atlan的产品目前已经与主流的现代数据技术栈产品做了对接,包括Snowflake, Databricks, Dbt, Redshift, BigQuery, Looker等等。
并且在Atlan的官网上,我们能看到Snowflake, Fivetran, Stitch, Datadog,Datarobot, Thoughspot等一众公司高管作为个人投资者投资了Atlan。
作为一个数据目录产品,如果能与这些主要的数据产品做无缝的对接,无疑能够利用这些已经比较成功产品的客户资源给自己带来更多高价值的客户。Atlan的整体思路还是非常值得称赞的。
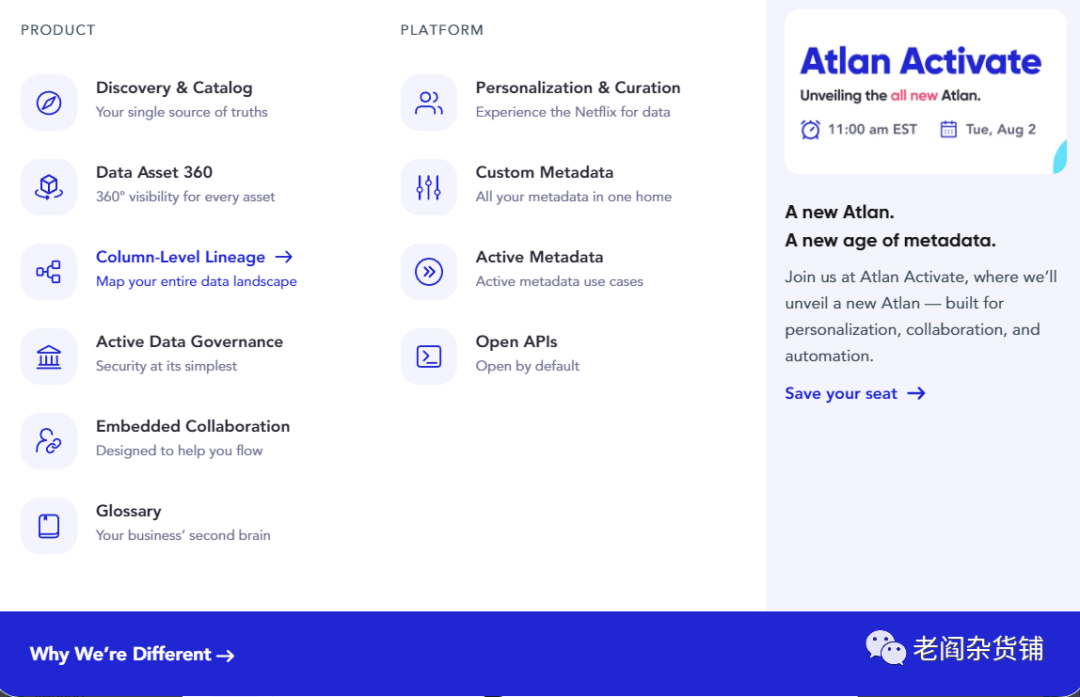
在产品方面,Atlan的整个产品族对于数据目录、数据资产管理已经比较完善了,并且内置支持协同。
Atlan的客户则包括联合利华,拉夫劳伦, Elastic, Postman, Monster等等。
Stemma
公司官网:https://www.stemma.ai
成立时间:2020年
公司所在地:西雅图
创始人:Mark Grover,Dorian Johnson
融资历史:种子轮融资480万美金,红杉资本
Stemma是Lyft开源的数据目录产品Amundsen的商业化公司。在2018年,Mark Grover开始在Lyft内部以开源的形式开发Amundsen,并且快速在开源社区以及Lyft公司内部获得了不错的反馈和用户使用。在2020年,Mark和Dorian决定把Amundsen商业化,并且获得了红杉的投资。Stemma也因此正式成立。
从产品的功能看,Stemma通过对不同平台的支持,来自动发现数据集相关的信息生成数据目录。并且通过与Slack等平台的集成来实现协同。
目前Stemma有包含iRobot, Flexport, Convoy等客户。在集成方面,Stemma已经和Snowflake, Redshift, BigQuery, Dbt, Looker等做了集成。但是由于起步晚,集成的产品还远远不如Atlan多。不过由于是以开源为基础,并且Amundsen已经有200多个贡献者,因此相信未来的集成对于Stemma应该不是大问题,最重要的还是如何在商业上获得更多的客户。
Acryl Data
公司官网:https://www.acryldata.io
成立时间:2020
公司所在地:旧金山
创始人:Shirshanka Das, Swaroop Jagadish, John Joyce
融资历史:种子轮融资 900万美金 8VC领投
Acryl Data也是基于开源进行商业化的数据目录公司。公司的创始人是曾经在Linkedin开发Datahub(Wherehows)的核心成员以及在Airbnb开发Dataportal的核心人员。Acryl Data主要是把LinkedIn开源的Datahub进行商业化的公司。
从开源产品看,Datahub在数据领域的知名度高于Amundsen,我在2016年就调研过Datahub的前身Wherehows。Linkedin在数据开源领域的影响力还是不错的。目前Datahub的贡献者和star数量也都稍微多于Amundsen。
在Acryl Data的官网看,产品对接集成到现代数据技术栈的产品页比Stemma要多。基本上主流的数据仓库、数据湖、数据调度以及BI工具都做了对接。从功能上看,数据目录、数据血缘、协同等等能力也都具备。
在Acryl Data的官网中,没有看到相关客户用例的信息,现在应该还是一些种子客户的引入和测试阶段。
在新的这个时代,基于公有云、面向最终用户、协同已经变成了基本上所有新的产品都要具备的特性。更新换代也正是由于这个原因而产生。数据目录相关的产品也不例外。在现代数据技术栈这个生态环境中,一批新的数据目录产品正在发展,相信这些产品随着时代的进一步发展,会逐渐替换曾经的软件时代的数据目录产品,并且最终获得市场的认可。
