




上周我们聊到了Databricks宣布开源了自己的Delta Lake 2.0Delta Lake 2.0 正式开源。今天我们聊一下Databricks最近宣布GA的数据建模和转换产品Delta Live Tables-DLT。
不得不说,Databricks发展到今天,从推出的产品来看,越来越像一个传统的软件公司。围绕一个核心的产品,然后在周边推出各种配套的产品。只不过Databricks走的是开源加上云商业化的路线。虽然我很喜欢Databricks这家公司,不过历史上走这种路线走成功的公司并不多。我老东家Oracle曾经有那么具备垄断级别的数据库,结果自研的周边产品大多数不成功,最终还是通过各种并购来解决了生态周边的问题。另外一个老东家IBM更是,技术优秀,自研能力不能说不强,但是最终也都是通过收购来做补充。而且无论Oracle还是IBM,一个非常牛的产品被他们收购之后大多都不如被收购之前的表现好。关于具体的原因,本文最后可以探讨一下。接下来我们先介绍一下DLT这个产品是啥,以及为啥Databricks要做这个产品。
01
DLT是啥?
Delta Live Tables是Databricks最新正式发布的一个ETL框架。通过DLT,工程师可以非常方便地采用声明式的方式构建数据加工的数据流。如下图的例子:

可以看到,利用SQL加上python的代码方式,可以比较方便地构建一个数据加工流程。
另外,从DLT的官方文档描述看,DLT支持CI/CD以及代码的测试,以及支持文档和数据质量相关的指标。同时,DLT也算是流批一体,支持流式数据处理和批式数据处理两种数据处理方式。
02
DLT和Dbt的对比?
实际上看到DLT发布的消息的时候,我第一时间想到的就是Databricks准备干dbt干的活了。从前面简单的DLT的功能和定位描述看,DLT与Dbt基本上做的是同样的工作,而且面向的是同样的用户群体-分析工程师。那么,DLT和Dbt之间有哪些相同和不同呢?
相同点
面向用户相同,都是分析工程师,需要用户具备分析和工程的能力
自动生成文档,都能够自动生成文档以及数据流程DAG图
CI/CD能力,都具备代码的版本管理以及部署和测试能力
不同点
对分析工程师技能要求不同,Dbt要求的技能以SQL为主,对python要求不高。DLT支持SQL,但是更偏向于python
与Databricks产品的集成度不同,Dbt虽然支持Databricks,但是仅仅把Databricks当作普通数据仓库来看。数据流的编排则或者自己的流程引擎,或者第三方其他的引擎。DLT由于是Databricks出品,因此天然地集成了Databricks的数据流。
开放程度不同,Dbt是独立的数据建模和转换工具,因此开放兼容了几乎所有的数据仓库,并且能支持不同的数据流编排工具。但是DLT则完全绑定在了Databricks的产品中。
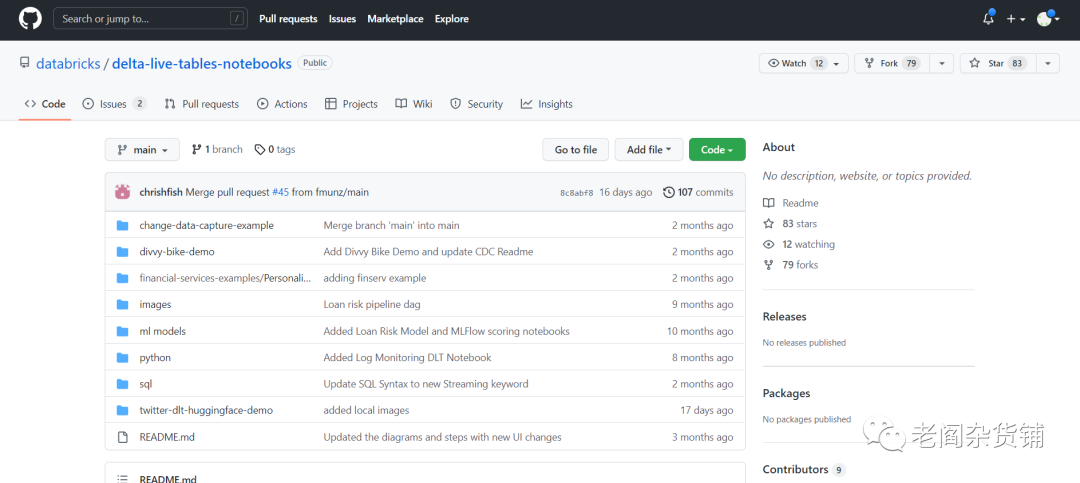
说完了功能和技术上的对照,咱们再看看这两个产品的开源社区情况。如下是DLT的社区情况:
接下来我们再看看dbt的开源社区情况:
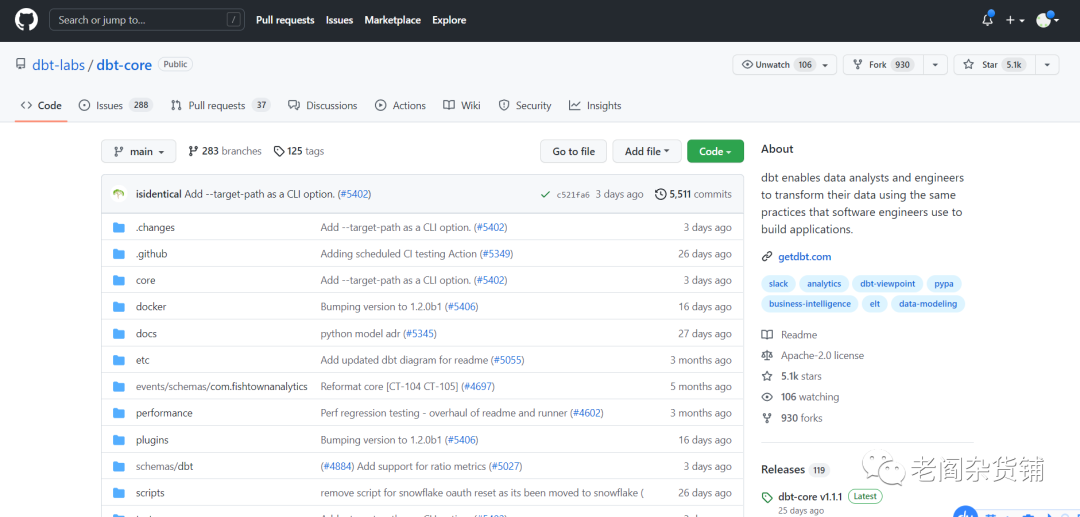
我们可以看到,无论是开源社区的start的数量,fork数量还是贡献者的数量,dbt都远远地高过DLT。从目前看,DLT还远远称不上一个重要的开源产品。在数据建模和转换这个方向上,与Dbt还算不上竞争对手。
03
DLT的未来?
这里,我们首先需要看一下Databricks为什么会做DLT?这不得不从Databricks的发展来去解释。Databricks最早的产品是开源的Spark,Spark实际上是一个可编程的计算框架。因此从技术本身来讲,相对于Snowflake等数据仓库系统,Spark不是一个数据库类型的系统,而是一个并行计算框架。在Databricks进入到lakehouse这个领域后,他的技术特点决定了他自己天然就是具备数据流程编排的能力。因此,Databricks推出DLT属于把自己本来就具备的能力单独独立出来形成了一个产品。
从Dbt的发展历史看,Dbt最早支持的底层的数据仓库平台是Snowflake, Redshfit, BigQuery等典型的数据仓库类型的平台。一直到2020年底,dbt才宣布支持Spark。这主要的原因也是最初Spark并不属于典型的面向懂SQL的分析工程师的产品,而是更多的是一个面向大数据工程师的编程的产品。
但是随着Databricks进入了lakehouse这个领域,并且能够更好的进行SQL的支持,Dbt才开始实现对Databricks的支持。在2020年11月底,dbt在自己的官网的博客上宣布支持spark并给出了比较具体的原因。原来不支持的原因就是Spark是面向编程的数据工程师的,而后边支持的原因是Spark有了更好的SQL的支持。
那么在已经有了Dbt的情况下,DLT有没有未来呢?这个事情也要辩证的去看。
首先,DLT不会成为一个主流的数据建模和转换的产品。其核心原因还是DLT强依赖和绑定Databricks自己的其他产品。如果一个客户不使用Databricks的湖仓产品,那么DLT对这个客户就没什么用。从这个前提看,DLT的客户群体就远远小于一个数仓中立的独立的数据建模和转换产品。
其次,如果一个客户采用了Databricks的湖仓产品,那么就要从客户的心理去分析。如果这个客户是个中小客户,并且不在意被一个厂商锁定,那么它可能会因为方便,采用Databricks的全家桶,因为这样会降低自己的工程们看看。毕竟采用一家的产品,出了问题都这一家来搞定,而且不需要了解额外的产品知识。如果这个客户具备一定的规模,从安全的角度考虑,客户通常会选择多家的不同的产品来构建自己的技术栈。因为这样能够保证自己不会被一家厂商。
因此,我们可以判断DLT会在Databricks的即有客户中获得一定的市场份额,能够帮助Databricks在单客户获得更多收入。但是DLT很难变为一个在数据建模和转换市场中的主流产品,而仅仅是一个Databricks工具包中的一个补充。
04
ToB市场的竞争和特点
现在我们回到一个经常会被讨论的问题,也是创业者经常会被问到的问题。就是你正在做的东西,如果有一个上游或者下游的厂商抄袭,会发生什么?
由于我自己这20年一直在ToB企业服务领域工作,对于ToB企业服务领域来讲,上下游乃至巨头的抄袭从来就不是阻碍一个创新型的公司发展的关键问题。
这种情况在企业服务领域一直在被证明。曾经信息化的第一个时代,无疑是蓝色巨人IBM的时代。在70年代,IBM发表了关系数据库的论文,拉里埃里森看到了这篇论文,创业成立了数据库公司Oracle。IBM当时如火中天,论文又是发表自IBM,无论人力还是财力,IBM都远远强过Oracle。但是,最终最成功的数据库公司是Oracle,IBM推出的数据库一直属于不温不火,最终还不得不收购Infomix来扩大自己在数据库市场的份额。而整个数据库市场,除了Oracle,还成长出来了Sybase, Infomix, SQL Server等等产品。
Oracle逐渐变成了数据库的老大,从斗龙少年变成了恶龙,开始基于数据库为核心做了数据仓库,ERP,中间件,与企业级市场的其他创业公司进行竞争。但是企业级应用和中间件市场还是成长起来了Sieble, Peoplesoft, BEA等等公司。并且在云时代来临的时候,出现了Salesforce这个在企业应用方面挑战Oralce的公司。当然,Oracle后来在二级市场通过资金的力量并购了Sieble, Peoplesoft, BEA等公司。但是每次并购,都会给竞争对手从被收购的公司获取客户创造了机会。而被收购的公司也在被收购后逐渐从优秀变得平庸。
究其原因,主要是企业服务市场从来就是一个非常复杂的生态系统。在这个生态中,系统集成商、软件服务提供商、硬件基础设施服务提供商各自都有自己的生态位置。一个企业如果想上下通吃,就会发现自己周边没有了朋友,自己能够服务的市场立刻就缩小了很多。而通吃的结果往往是自己精力分散,在每个细分战场都在于不同的敌人进行竞争,自然就会落下风。另外,目标客户出于自身安全的考虑,也不希望被一家厂商锁死,因此也不会从一家选购所有的产品。这也是为什么在企业服务领域会经常存在并购、拆分等分分合合的原因。
到了云的时代,这个特征就更明显。传统软件时代集成相对困难,每个产品都是相对封闭的产品,当时为了集成和兼容,才有了各种协议规范,比如SQL规范,Java规范,J2EE规范等等。但是到了云时代,开放对接成为了主流,因此所有的成功的产品都是API优先。在这种开放的环境中,竞争无疑变得更加激烈和开放,这就要求每个产品都要做到极致才能获得客户的青睐。每个厂商无论是否已经成功,都需要在自己的核心领域保证足够的领先。具体到上下游周边,通过与其他厂商更好的对接协同带来的收益,可能比自己直接切入上下游获得的收益更大。因此上下游去贸然进入一个市场就会变得更加谨慎。所以我相信云时代相对传统软件时代,ToB服务市场的产品会变得更加多样化,整个生态系统也更丰富,很难出现一个寡头全吃的场景。
