




点击上方"数据与人", 右上角选择“设为星标”
分享干货,共同成长!


本文讲述如何查找数据库里重复的行。这是初学者十分普遍遇到的问题。方法也很简单。这个问题还可以有其他演变,例如,如何查找“两字段重复的行”(#mysql IRC 频道问到的问题)
insert into test(id, day) values(1, '2006-10-08');
insert into test(id, day) values(2, '2006-10-08');
insert into test(id, day) values(3, '2006-10-09');
select * from test;
+----+------------+
| id | day |
+----+------------+
| 1 | 2006-10-08 |
| 2 | 2006-10-08 |
| 3 | 2006-10-09 |
+----+------------+
+------------+----------+
| day | count(*) |
+------------+----------+
| 2006-10-08 | 2 |
| 2006-10-09 | 1 |
+------------+----------+
+------------+----------+
| day | count(*) |
+------------+----------+
| 2006-10-08 | 2 |
+------------+----------+
insert into to_delete(day, min_id)
select day, MIN(id) from test group by day having count(*) > 1;
select * from to_delete;
+------------+--------+
| day | min_id |
+------------+--------+
| 2006-10-08 | 1 |
+------------+--------+
where exists(
select * from to_delete
where to_delete.day = test.day and to_delete.min_id <> test.id
)
a int not null primary key auto_increment,
b int,
c int
);
insert into a_b_c(b,c) values (1, 1);
insert into a_b_c(b,c) values (1, 2);
insert into a_b_c(b,c) values (1, 3);
insert into a_b_c(b,c) values (2, 1);
insert into a_b_c(b,c) values (2, 2);
insert into a_b_c(b,c) values (2, 3);
insert into a_b_c(b,c) values (3, 1);
insert into a_b_c(b,c) values (3, 2);
insert into a_b_c(b,c) values (3, 3);
group by b, c
having count(distinct b > 1)
or count(distinct c > 1);
group by b, c
having count(1)
or count(1);
group by b, c
having count(distinct b) > 1
or count(distinct c) > 1;
+------+----------+
| b | count(*) |
+------+----------+
| 1 | 3 |
| 2 | 3 |
| 3 | 3 |
+------+----------+
from a_b_c group by b having count(*) > 1
union
select c as value, count(*) as cnt, 'c' as what_col
from a_b_c group by c having count(*) > 1;
+-------+-----+----------+
| value | cnt | what_col |
+-------+-----+----------+
| 1 | 3 | b |
| 2 | 3 | b |
| 3 | 3 | b |
| 1 | 3 | c |
| 2 | 3 | c |
| 3 | 3 | c |
+-------+-----+----------+
where b in (select b from a_b_c group by b having count(*) > 1)
or c in (select c from a_b_c group by c having count(*) > 1);
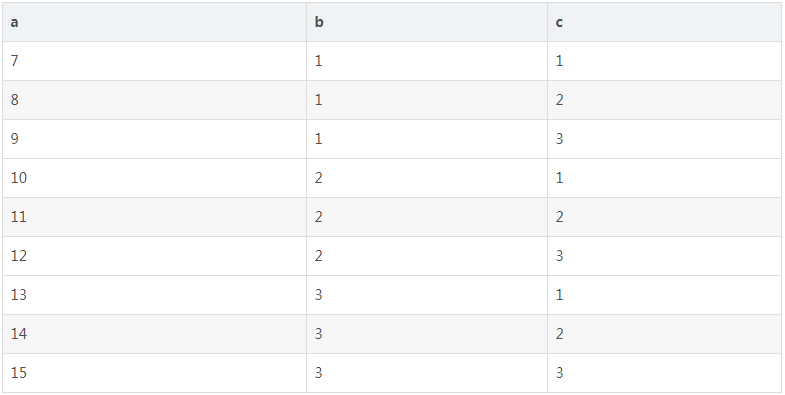
+----+------+------+
| a | b | c |
+----+------+------+
| 7 | 1 | 1 |
| 8 | 1 | 2 |
| 9 | 1 | 3 |
| 10 | 2 | 1 |
| 11 | 2 | 2 |
| 12 | 2 | 3 |
| 13 | 3 | 1 |
| 14 | 3 | 2 |
| 15 | 3 | 3 |
+----+------+------+
from a_b_c
left outer join (
select b from a_b_c group by b having count(*) > 1
) as b on a_b_c.b = b.b
left outer join (
select c from a_b_c group by c having count(*) > 1
) as c on a_b_c.c = c.c
where b.b is not null or c.c is not null
https://blog.csdn.net/zhengzhb/article/details/8590390

文章转载自数据与人,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
