




介绍
大多数最新的语音识别模型通常依赖于大型监督数据集,这对于许多低资源语言来说是不可用的;这对创建包含所有语言的语音识别模型提出了挑战。为了解决这个问题,卡内基梅隆大学的研究人员提出了一种创建语音识别系统的方法,该系统不需要任何目标语言的音频数据集或发音词典。唯一的先决条件是可以访问原始文本数据集或目标语言的一组 n-gram 统计信息。
在本文中,我们将更详细地了解这个提议的方法。让我们开始吧!
强调
ASR2K 是一个语音识别管道,不需要目标语言的音频。唯一的假设是可以访问原始文本数据集或一组 n-gram 统计信息。
ASR2K 中的语音管道包括三个组件,即声学、发音和语言模型。
与传统管道相比,声学和发音模型采用多语言模型,无需监督。语言模型是使用原始文本数据集或 n-gram 统计数据创建的。
这种方法用于 1909 种使用 Crubadán 的语言,这是一个大型濒危语言 n-gram 数据库。然后它随后在 129 种语言上进行了测试(来自 Common Voice 数据集的 34 种语言 + 来自 CMU Wilderness 数据集的 95 种语言)。
在测试中,使用 Crubadán 统计数据在 Wilderness 数据集上仅实现了 50% CER(字符错误率)和 74% WER(字错误率)。当使用 10,000 个原始文本话语时,这些结果随后提高到 45% CER 和 69% WER。
现有方法
现代架构通常需要数千小时的训练数据才能使目标语言表现良好。然而,全世界大约有 8000 种语言,其中大多数缺乏音频或文本数据集。
一些尝试通过利用来自自我监督学习模型的预训练特征来减小训练集的大小。然而,这些模型继续依赖少量成对的监督数据进行单词识别。
最近,考虑到无监督机器翻译的成功,一些工作一直在应用无监督方法来改进语音识别。这些模型应用对抗学习来自动学习音频表示和音素单元之间的映射。尽管这些最近的方法取得了成功,但所有这些模型都依赖于目标语言的一些音频数据集(标记或未标记),这严重限制了目标语言的范围。
为 ASR2K 提出的方法论
语音管道包括声学、发音和语言模型。
即使在训练集中看不到语言,声学模型仍应识别目标语言的音素。
发音模型是一个 G2P(grapheme-to- ph oneme)模型,可以在给定一个字素序列的情况下预测音素发音。
声学和发音模型都可以使用来自高资源语言的监督数据集进行训练,然后在一些语言知识的帮助下应用于目标语言。与标准管道相比,声学和发音模型采用多语言模型,并且可以在没有监督的情况下用于零样本学习设置。
通过使用发音模型对每个单词的近似发音进行编码来创建词汇图。最后,使用原始文本或 n-gram 统计数据创建语言模型,并结合发音模型创建(加权有限状态换能器)WFST 解码器。
语音音频 (X) 和语音文本 (Y) 的联合概率定义如下:
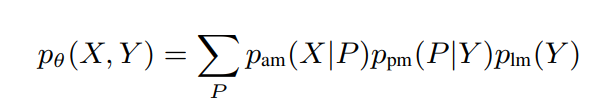
, 其中 P 是文本 (Y) 对应的音素序列。通常,发音模型 p pm被建模为确定性函数 δ pm。此外,只能从文本中估计语言模型,而声学模型和发音模型是使用零样本学习或其他高资源语言的迁移学习来近似的;因此 p ^ am , ^ δ pm对应于近似的声学模型和发音模型。先验分解可以粗略表示为:
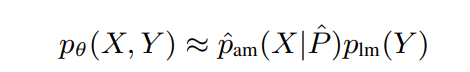
, 其中 P^ = ^δ pm (Y ) 是近似的音素。
为了使用小型测试集更有效地分析管道,使用一种方法将观察到的错误分解为声学/发音模型错误和语言模型错误。
评估结果
这种方法用于 1909 种使用 Crubadán 的语言,这是一个大型濒危语言 n-gram 数据库。然后它在 129 种语言上进行了测试(来自 Common Voice 数据集的 34 种语言 + 来自 CMU Wilderness 数据集的 95 种语言)。
1) 使用 PER 评估声学模型:使用音素错误率 (PER) 度量评估声学模型。它提供了许多关于声学模型的有用见解。
表 1 说明了 4 个声学模型的性能。基线声学模型的 PER 大约为 50%,其中一半的错误是删除错误。事实证明,域和语言不匹配是删除错误的主要原因。基于 SSL 的模型用于提高鲁棒性,从而将错误率降低了 5%。从删除减少中获得了显着的改进。此外,发现 XLSR 模型表现最好,因此将其用作管道中的主要模型。
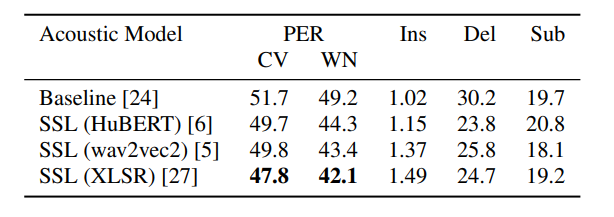
表 1:所有测试语言中声学模型的平均结果 (PER)。
2)评估语言模型: 表2说明了语言模型的性能。首先,在不使用任何文本数据集的情况下尝试来自 Crúbadán 的 n-gram 统计
数据,结果表明即使没有任何文本数据集,Crúbadán 也能捕获一些字符级信息
:它在两个数据集上实现了 65% 和 50% 的 CER。接下来,使用训练集 1k、5k 和 10k 文本话语来训练没有 Crubadán 的模型。考虑到训练文本数据集与测试数据集在同一域中,这显着提高了性能。一个 10k 文本数据集实现了 51% 和 45% 的 CER。
此外,还评估了结合使用 Crubadán 和文本语言模型的效果。但是,这种方法并没有提高性能,因为两个模型之间存在域不匹配。
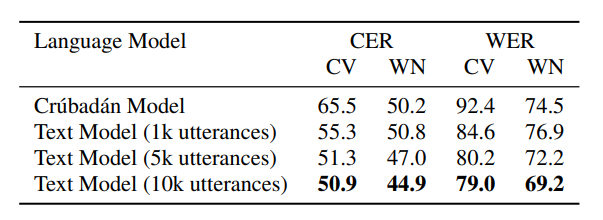
表 2:在不同资源条件下,语言模型在 CER 和 WER 方面的所有测试语言的平均性能。
考虑到这是为大约 2000 种语言构建无音频语音识别管道的首次尝试,这些结果是一个里程碑。
结论
在本文中,我们探索了一种无音频语音识别管道 (ASR2K),它不需要目标语言的任何音频数据集或发音词典。这篇文章的主要内容如下:
- ASR2K 是 1909 种语言的语音识别管道,不需要目标语言的音频。唯一的先决条件是可以访问原始文本数据集或一组 n-gram 统计信息。
- 语音管道包括声学、发音和语言模型。
- 只有 ASR2K 语言模型可以从提议的管道中的文本中估计出来。相比之下,声学和发音模型是使用来自其他高资源语言的迁移学习或零样本学习来近似的。
- 原始文本或 n-gram 统计信息用于构建语言模型,结合发音模型构建 WFST 解码器。
- 在跨两个数据集的 129 种语言上测试这种方法,即。仅使用 Crubadán 统计数据在 Wilderness 数据集上实现了 Common Voice 和 CMU Wilderness 数据集、50% CER 和 74% WER。当使用 10,000 个原始文本话语时,这些结果随后提高到 45% CER 和 69% WER。
原文标题:ASR2K: Speech Recognition Pipeline to Recognize Languages
原文作者:Drishti Sharma
原文链接:https://www.analyticsvidhya.com/blog/2022/10/asr2k-speech-recognition-pipeline-to-recognize-languages/
