




MongoDB
一、什么是MongoDB?
MongoDB是一个面向文档的分布式Nosql数据库。MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 的BSON格式,所以可以存储比较复杂的数据结构。它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引
二、MongoDB的基本概念
下面介绍一些MongoDB的基本概念
1. 文档
文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这是与关系数据库最不同的点。
如:
{"where":"公众号", "name":"lanternteam"}
★BSON是一种计算机数据交换格式,它是一种二进制的表示形式,能用来表示简单数据结构、关联数组(MongoDB中称为“对象”或“文档”)以及MongoDB中的各种数据类型。
”
2. 集合
集合是一组文档,无固定结构,也就是说可以对集合插入不同格式和类型的数据,类似与RDBMS中的表格,存在与数据库中。

3. 数据库
一组集合可以组成一个数据库。一个MongoDB实例可以承载多个数据库。
4. 数据类型
MongoDB中的文档本质是一种类似JSON的BSON格式的数据。
BSON是一种类似JSON的二进制格式数据,它可理解为在JSON基础上添加了一些新的数据类型。
(1)基本数据类型
null:表示空值或不存在的字段
{'x' : null}布尔
boolean
:true
和false{'x' : true}数字:MongoDB支持的数字类型比较广泛,包括32位整数、64位整数、64位浮点数。
{'x' : 3.14}字符串:UTF-8字符串都可以表示为字符串类型数据
{'x' : 'HelloWorld!'}数组:值的集合或列表可以表示成数组
{'x' : ['a', 'b', 'c']}对象:对象
Object{'x' : Object()}
(2)_id和Objectid
MongoDB中存储的文档必须有一个_id
键值,这个值可以是任何类型的,若插入文档的时候无指定"_id"
值,系统会自动帮你创建一个,每个文档都由唯一的"_id"
值,默认是个ObjectId
对象。
_id:在创建文档的时候,可以手动定义
_id
值,但它必须是唯一不重复的,一个_id值
就要对应唯一的一个文档。Objectid:Objectid是一个
"_id"
的默认类型,可以很快的去生成和排序,包含12bytes,含义是:前4个字节表示 unix
时间戳,格林尼治时间UTC
时间,比北京时间晚了8小时;接下来的3个字节是机器标识码; 紧接的两个字节由进程 id
组成PID
;最后三个字节是随机数

(3)日期
MongoDB中支持Date
作为键的一个值。
{'name' : 'jack', 'date' : new Date()}
文档中,date属性值为new Date()
,new Date()
创建了一个Date对象,返回日期的字符串表示。
(4)内嵌文档
把整个MongoDB文档当做另一个文档中的一个键的一个值。
{
'name' : 'jack',
'address' : {
'street' : 'Zoo Park Street',
'city' : 'Landon',
}
}
二、MongoDB集群架构
MongoDB三大核心优势:灵活模式(json文档,不限制个数和种类)、高可用(副本集)、可扩展(分片,集群)。
1. 核心组件
(1)Mongod
它会处理所有的数据请求、管理数据格式并且执行用于后台管理的操作。
(2) mongo
为研发人员提供的一个交互式的JS API,方便在数据库上直接做测试查询和操作,并且也可用于系统管理员对数据库进行有效管理。
(3)mongos(路由服务器)
数据库集群请求的入口,所有请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求转发到对应的shard服务器上。
(4)Config server(配置服务器)
存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。
注意点:
mongos第一次启动或因故障重启都需要加载配置信息。若配置信息有变化会通知所有mongos更新自己的状态; 配置信息不能丢失,否则mongos会挂掉。
(5)Replica Set(复制集或副本集)
这是MongoDB的核心高可用特性之一,它基于主节点的oplog日志持续传送到副主节点,并重放得以实现主从节点一致,再结合心跳机制,当感知到主节点不可访问或宕机的情形下,辅助节点通过选举机制来从剩余的辅助节点中推选一个新的主节点从而实现自动切换。
(6)Shard(分片)
一台普通的机器做不了的工作,由多台机器来共同完成。
2.集群架构
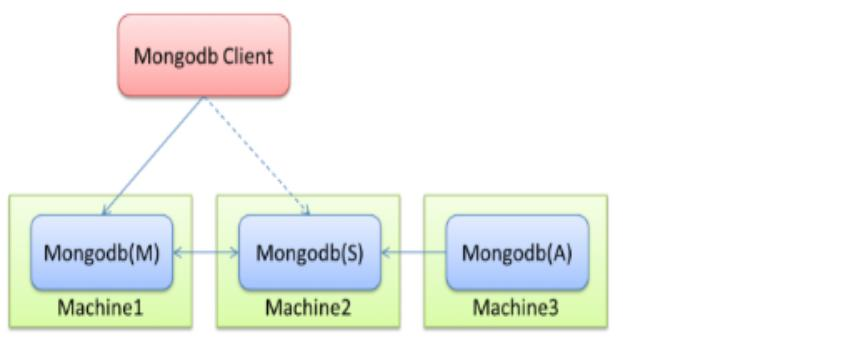
(1) 主从复制(Master-Slaver)
建立一个主节点和一个或多个从节点,可用于备份、故障恢复、读扩展等。
它的缺点:当主节点出现故障时,只能人工介入,指定新的主节点,从节点不会自动升级为主节点。
与副本集的区别:副本集能自动故障恢复。
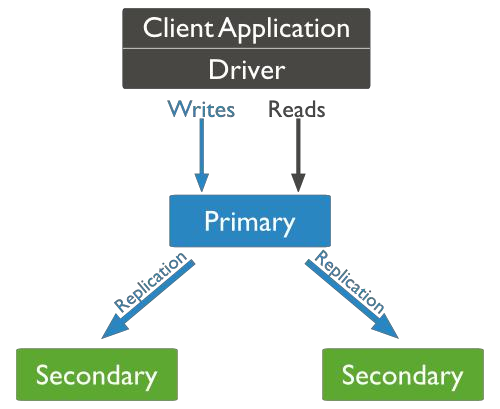
(2)副本集(Replica Set)
副本集的集群拥有一个主节点和多个从节点。当集群中主节点发生故障时,副本集可以自动投票,选举出新的主节点,并引导其余的从节点连接新的主节点,这个过程是透明的。
它的优点:自带故障转移功能的主从复制。
MongoDB副本集使用的是**N个Mongod节点构建的具备自动容错功能、自动恢复功能的高可用方案。在副本集中,任何一个节点都可作为主节点,但为维持数据一致性,只能有一个主节点。**一个副本集集群中各个服务器的几种状态:
主节点 Primary
:一个副本集有且仅有一台服务器处于Primary,它负责数据的写入和更新,还负责指定其它节点为从节点。备用节点 Secondary
:副本集允许有多台Secondary,每个备用节点数据与主节点的数据是完全同步的。仲裁节点 Arbiter
(可无需单独存在):负责在主节点发生故障时,参与选举新节点作为主节点。它不存数据,监控其它节点,无仲裁节点就全部节点投票选举。无效节点 Down
:当服务器挂掉或掉线时就会处于该状态。
心跳检测:
副本集中的各节点会通过心跳信息来检测各自的健康状况,当主节点发生故障时,多个从节点会触发一次新的选举操作,并选举其中一个作为新的主节点。
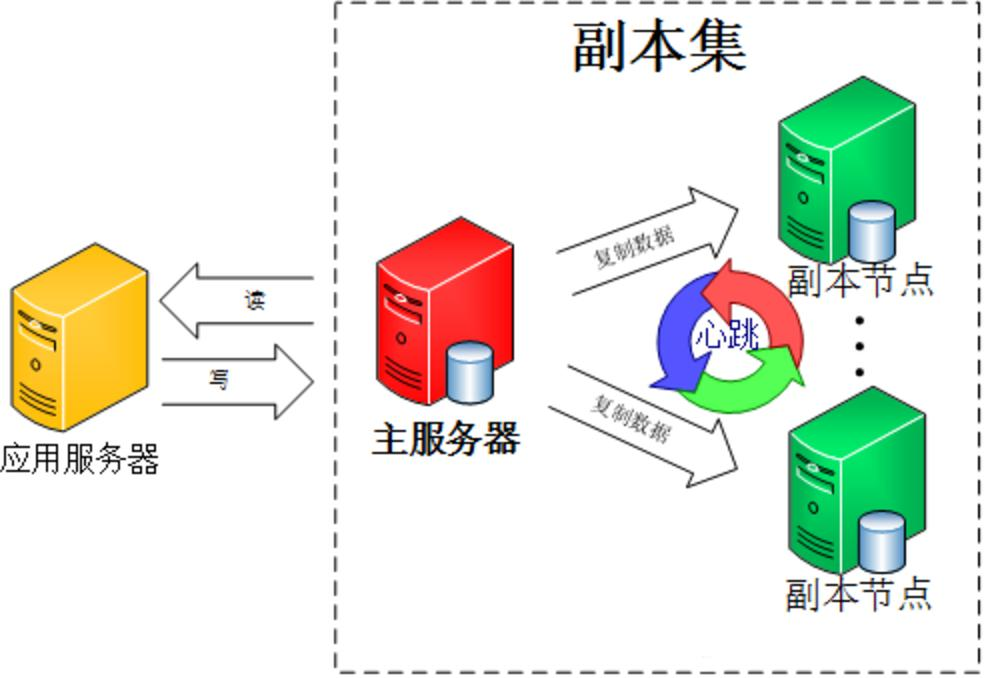
选举:
MongoDB的主节点选举由心跳触发。
副本集选举采用的是Bully
算法:主要思想是集群的每个成员都可以声明它是主节点并通知其它节点。
为了保证选举票数不同,副本集的节点数保持为奇数。最少3个副本节点,最多12个,最多7个节点参与选举。
部署副本集(replicattion set):
多台服务器维护相同的数据副本,提高服务器的可用性,即高可用性。
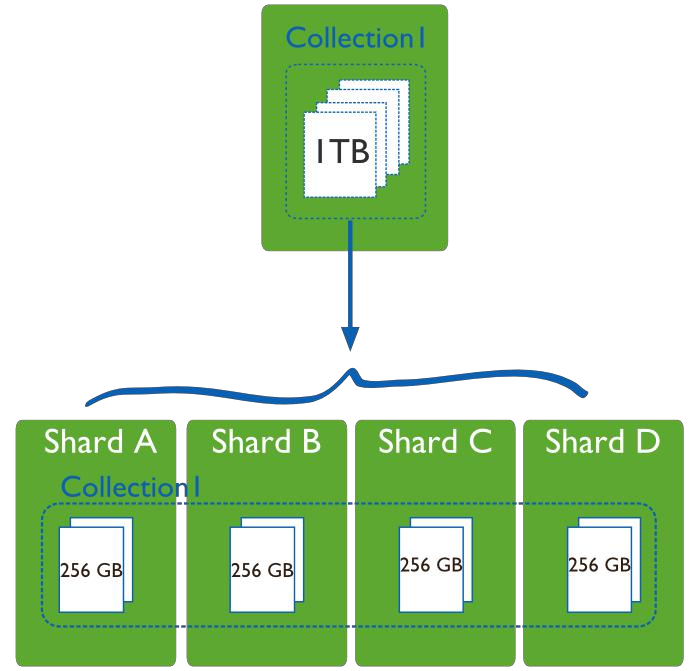
(3) 分片(sharding)(分区)
分片是指将数据拆分,将其分散存放在不同机器上的过程。
构建一个MongoDB的分片集群,需要三个重要的组件:分片服务器(Shard Server)、配置服务器(Config Server)、路由服务器(Route Server)
分区服务器Shard Server
每个Shard Server都是一个mongod数据库实例,用于存储实际的数据块。整个数据库集合分成多个块存储在不同的Shard Server中。一个Shard Server可由几台机器组成一个副本集来承担,防止因主节点单点故障导致整个系统崩溃。
配置服务器Config Server
这是独立的一个mongod进程,保存集群和分片的元数据(配置信息),在集群启动最开始时建立(启动日志),保存各个分片包含数据的信息。
路由服务器Route Server
这是独立的一个mongos进程,Route Server在集群中可作为路由使用,客户端由此接入,让整个集群看起来像一个单一的数据库,提供客户端应用程序和分片集群之间的接口。Route Server本身不保存数据,启动时从Config Server加载集群信息到缓存中。
三、应用场景
(1)主要场景:
网站实时数据处理。它非常适合实时的插入、更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。 缓存。由于性能很高,它适合作为信息基础设施的缓存层。在系统重启之后,由它搭建的持久化缓存层可以避免下层的数据源过载。 高伸缩性的场景。非常适合由数十或数百台服务器组成的数据库,它的路线图中已经包含对MapReduce引擎的内置支持。
不适用的场景:
要求高度事务性的系统。 传统的商业智能应用。 复杂的跨文档(表)级联查询。
(2)使用场景:
网站数据:Mongo 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。 缓存:由于性能很高,Mongo 也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo 搭建的持久化缓存层可以避免下层的数据源过载。 大尺寸、低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。 高伸缩性的场景:Mongo 非常适合由数十或数百台服务器组成的数据库,Mongo 的路线图中已经包含对MapReduce 引擎的内置支持。 用于对象及JSON 数据的存储:Mongo 的BSON 数据格式非常适合文档化格式的存储及查询。
不适场景:
高度事务性的系统:例如,银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。 传统的商业智能应用:针对特定问题的BI 数据库会产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。 需要SQL 的问题。
(3)应用案例:
游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储,方便查询、更新
物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以 MongoDB 内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能
物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析
视频直播,使用 MongoDB 存储用户信息、礼物信息等
参考文献
[1]《NoSQL数据库原理与应用》 ——王爱国、许桂秋主编
[2] MongoDB教程https://www.runoob.com/mongodb/mongodb-tutorial.html
[3] BSON-百度百科https://baike.baidu.com/item/BSON/10981745?fr=aladdin
[4] MongoDB应用场景?https://www.zhihu.com/question/32071167/answer/1370900597
[5] 什么场景应该用MongoDB?https://developer.aliyun.com/article/64352
