




sql_id:5s1wx1pppquax:
select count(1) count from t_vou_XXXX voucher
where batch_no = :1 and customer_no is not null;
执行计划:
执行信息:
表信息:
SQL> select NUM_ROWS from dba_tables where table_name='T_VOU_XXXX';
NUM_ROWS
----------
184266247
大小 42.4G
索引信息:
batch_no,customer_no列上 各自有单独的索引
列统计信息:

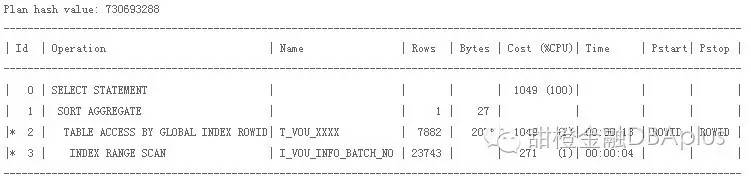
执行计划分析:
该sql 首先走的是batch_no列上的索引(id=3),然后再通过rowid回表(id=2),再聚合(id=1)
从上面的信息我们可以发现 此sql使用730693288的执行计划,平均单次执行需要333s,执行效率较差。
优化思路:
从执行计划的步骤和sql内容上,我们可以发现该sql 是统计满足这2个条件的数据量,并且执行计划中有回表的操作,
至此我们就有了优化的思路,建立组合索引,避免执行计划中的回表操作。
怎么建组合索引?
该表这2个列都有独自的索引。因此需要改造下。 列的统计信息如上, 通常我们建组合索引,选择性好的放在前面(可以避免index skip scan),因此按照常规的我们的索引列顺序为 ('CUSTOMER_NO','BATCH_NO'),但是如果这样建索引,对于我们的这个sql优化,没有用。从sql的where条件可以发现,若是走这个索引,则是(index full scan),因此这样是行不通的。故我们建索引的顺序为('BATCH_NO','CUSTOMER_NO'),并且删掉原来的batch_no上的冗余索引,因CUSTOMER_NO有单独的索引,因此index skip scan的情景就不必担心会发生。
实施步骤:
1、--估算索引大小:
4.6G 现有空间12G, 估算建完后还剩余7G 使用率(85-7)/85*100%=91.7%,会触发告警因此需要加空间
set serverout on
variable used_bytes number
variable alloc_bytes number
exec dbms_space.create_index_cost('create index i_vou_info_batch_cust_no on t_vou_XXXX( batch_no ,customer_no ) tablespace TBS_VOUCHER_IDX local online parallel 16',:used_bytes,:alloc_bytes);
print :used_bytes
print :alloc_bytes
2、建立索引:
create index i_vou_info_batch_cust_no on t_vou_XXXX( batch_no ,customer_no ) tablespace TBS_VOUCHER_IDX local online parallel 8;
alter index i_vou_info_batch_cust_no noparallel;
3、invisible原有的索引:
alter index I_VOU_INFO_BATCH_NO invisible;
4、观察是否使用新建的索引,及前后的性能变化:

Peeked Binds (identified by position):
--------------------------------------
1 - :1 (VARCHAR2(30), CSID=871): 'B20160512112812105'
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("BATCH_NO"=:1)
filter("CUSTOMER_NO" IS NOT NULL)
优化后的sql,执行时间由原来的平均每次332s,到优化有的平均每次不超过2s,优化后的sql执行性能有明显的提高。
5、删除原有的索引:
drop index I_VOU_INFO_BATCH_NO;
---gt
