




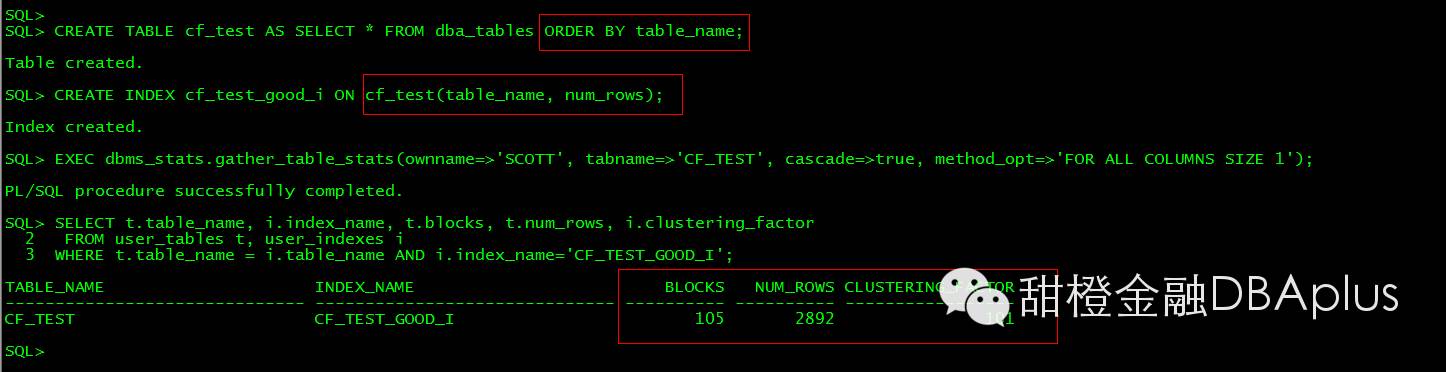
索引聚簇因子:是指按照索引列值进行了排序的索引条目顺序和其对应表中数据行顺序的相似程度。聚簇因子大小对数据读取效率有着直接的影响,聚簇因子越小,则说明相似程度越大,索引使用越趋于高效
Clustering Factor最小时,其无限接近于表的数据块数,该表是按照索引字段顺序排序存储的。Clustering Factor 最大时,其无限接近于表的行数,该表是完全不按照索引字段顺序存储的Clustering Factor 反映的是通过索引扫一张表,需要访问表的数据块数量,即反映I/O 的次数。
也就是说聚簇因子和选择度,基本上决定了索引扫描的COST 开销。所以说 CBO 会严重考虑 (Clustering Factor) CF的大小。
一个完美CF的索引结构应该是如下图:
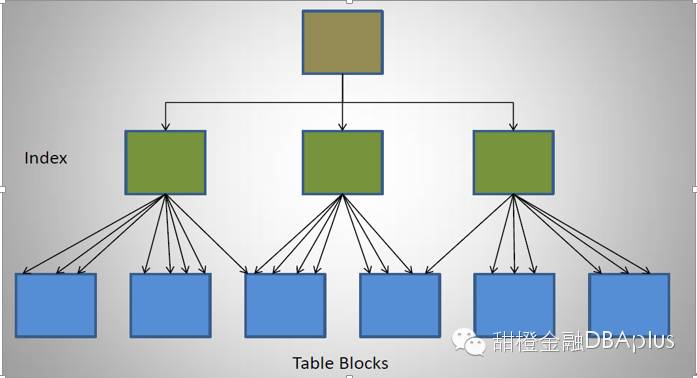
一个比较糟糕CF的索引结构是这样子:
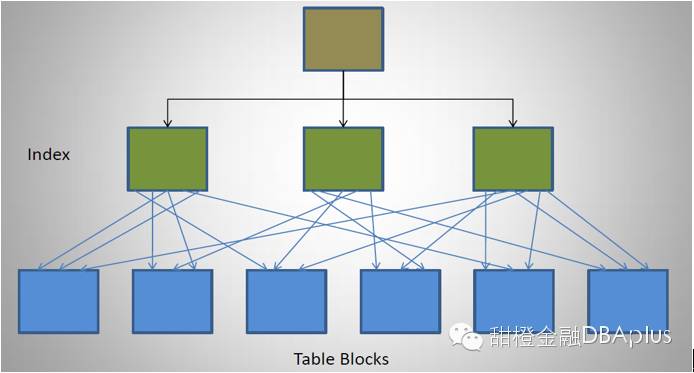
不难得知索引较好的CF情况是当数据按顺序插入的时候.但是在实际的生产环境或复杂的业务状况下。为了性能基本上不太可能会按顺序插入记录.所以任何影响数据顺序的都会影响索引的CF.
接下来看个实验.
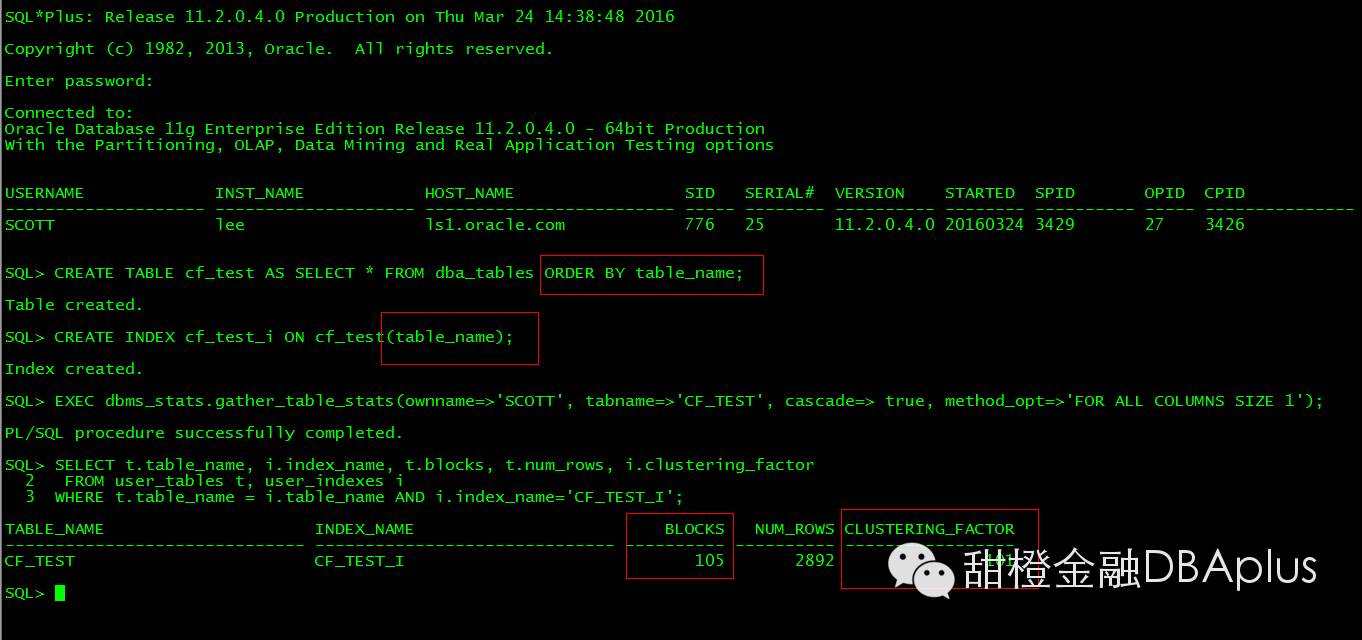
比较好的CF 索引例子:可以看到 CF 大小接近于block数.
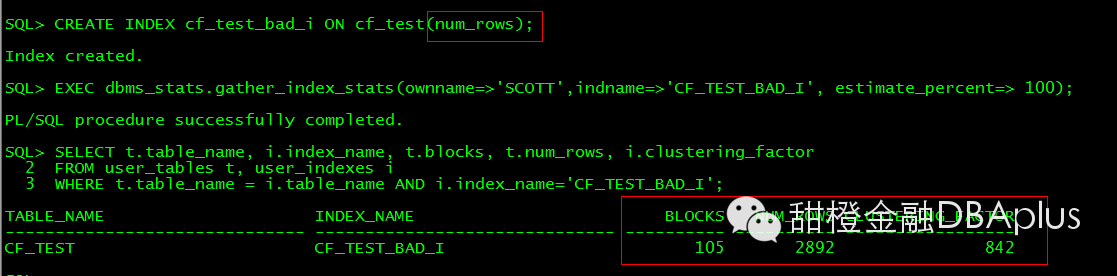
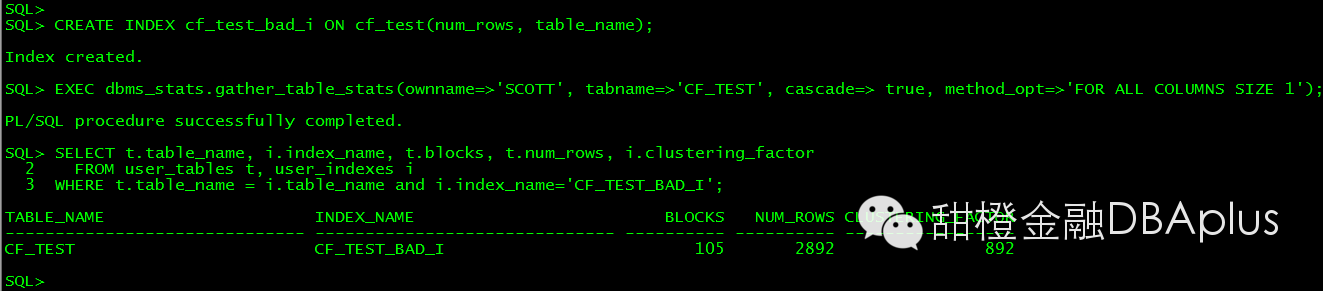
因为一张表有多个字段,一般只有会按一个字段排序.我们在另外一个无序的字段上创建索引,这个时候CF也是比较糟糕的。
对于联合索引情况也是一样的:
下面可以看到和前导列的dk值多少没什么关系,主要是insert 时候的顺序决定了:
Reduild index 并不能改变索引的CF。 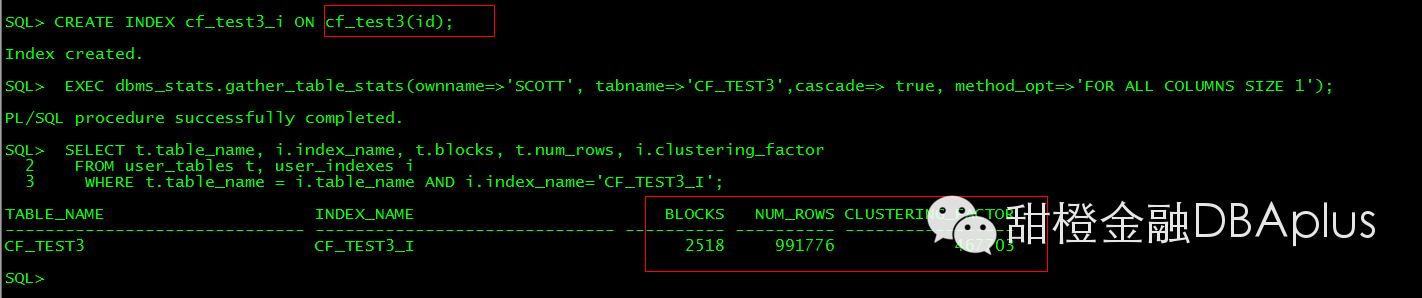
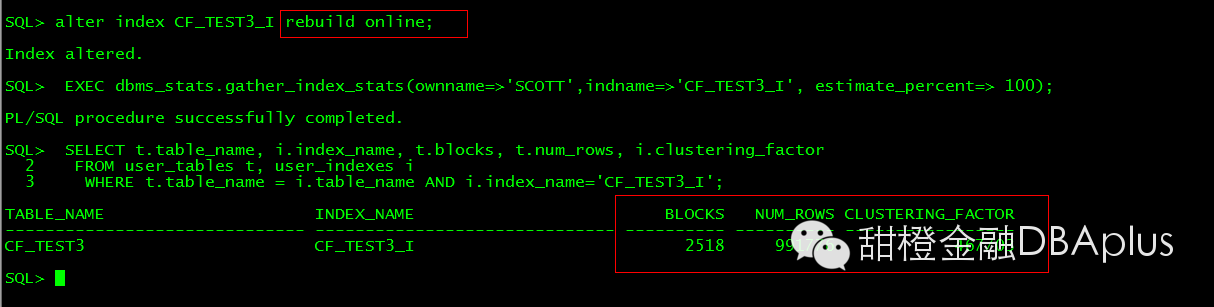
所以为了改善CF,这个表需要重建并且排序。但是一张表按A 字段去排序了,那么B 字段可能就会无序。也就是说这是个综合考虑的事情。
下面看一下 索引的 CF 对CBO 的影响:
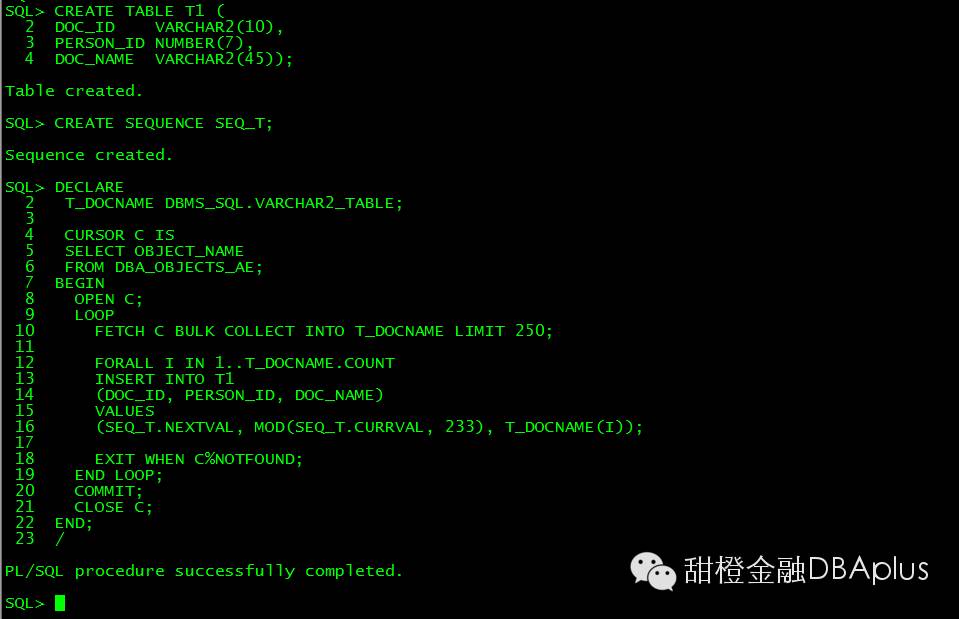
数据分布均匀

直接查询,无索引走全表: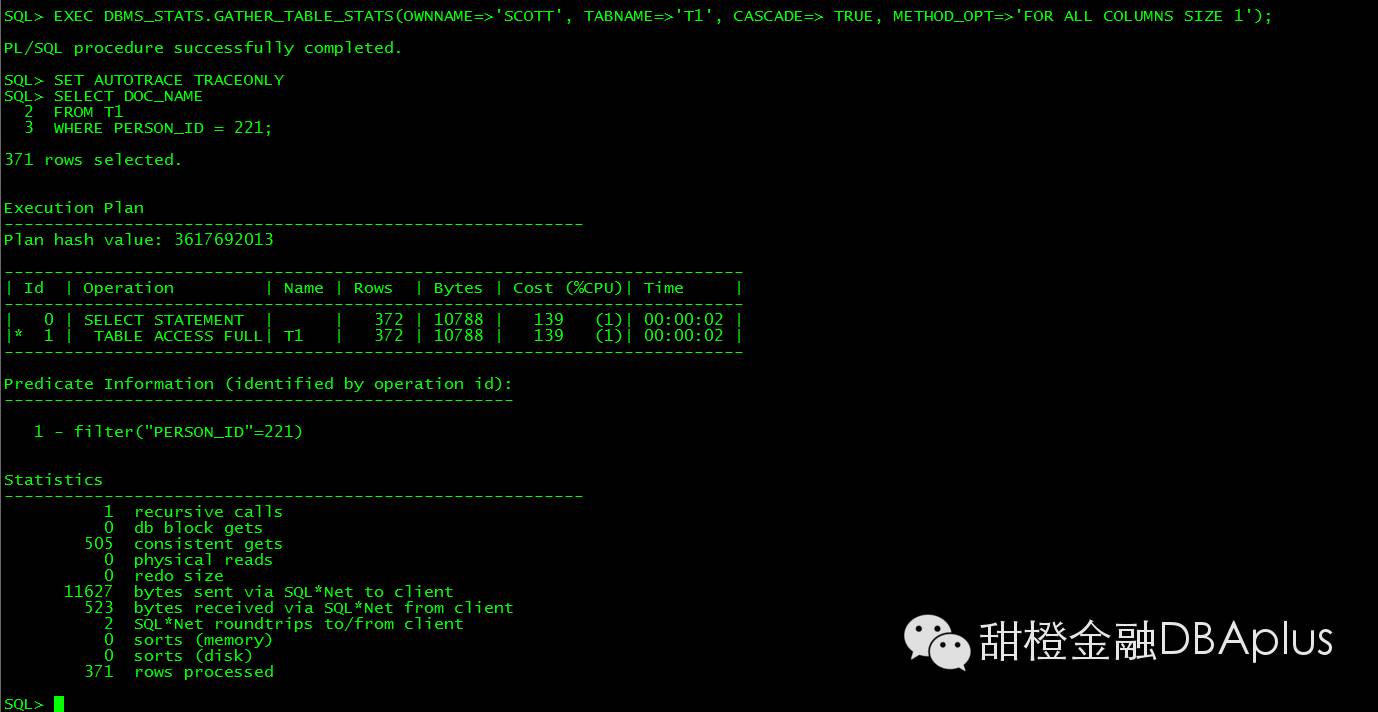
创建索引居然还走全表: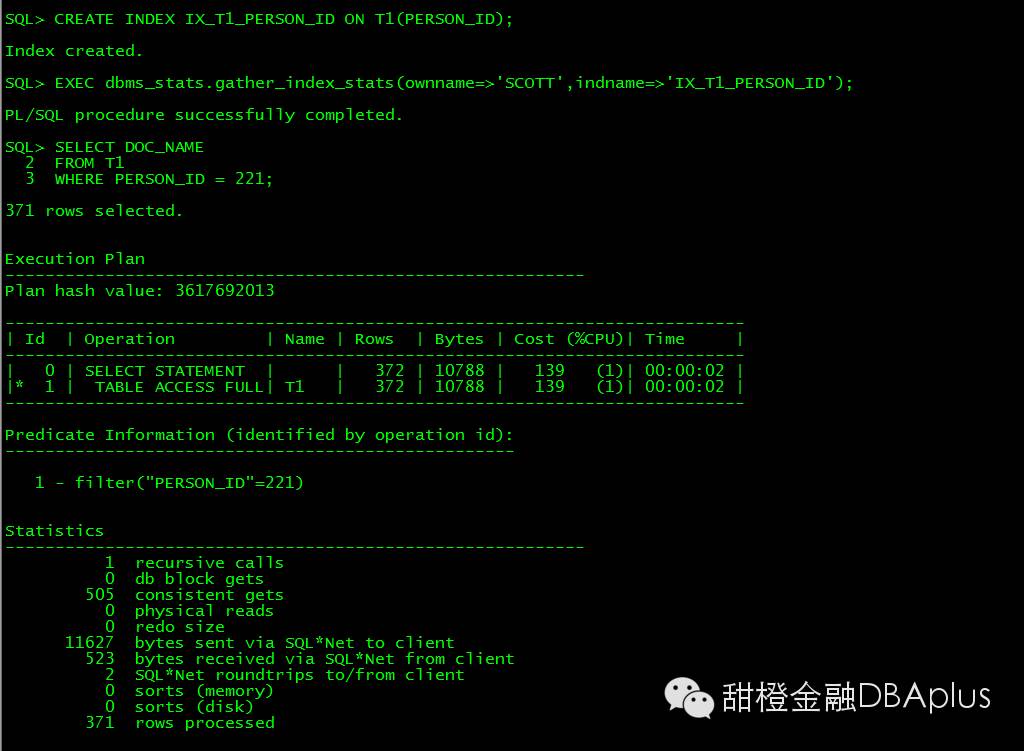
查看索引CF 情况比较糟糕,几乎和行数一样:
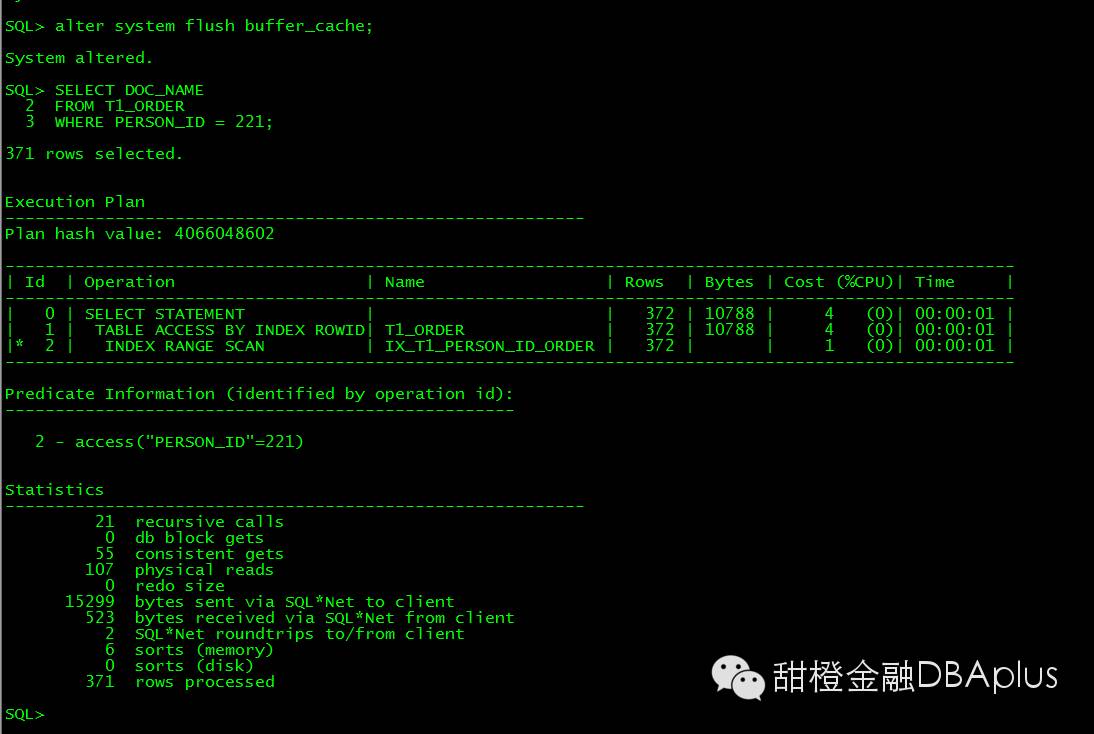
创建新表order by PERSON_ID,CF 情况很好:
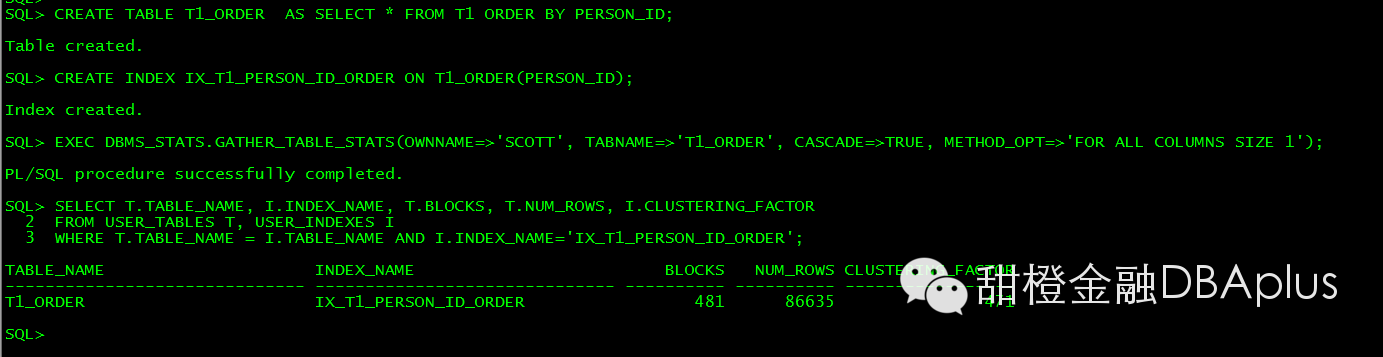
执行同样的语句:走了索引。
总结:
优秀的索引设计应该具备以下的特征:
1.具有较好的选择度.
2.索引列的数据分布足够趋于均匀化.
3.具有较小的CF.
