




Memcached是一个高性能的分布式的内存对象缓存系统,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。Memcached是danga.com的一个项目,最早是为 LiveJournal 服务的,最初为了加速 LiveJournal 访问速度而开发的,后来被很多大型的网站采用。目前全世界不少人使用这个缓存项目来构建自己大负载的网站,来分担数据库的压力。
Memcached存取的对象都是以key-value的形式存储在服务器端内存中,全内存数据保存,每个被存取的对象都有一个唯一的标志key。
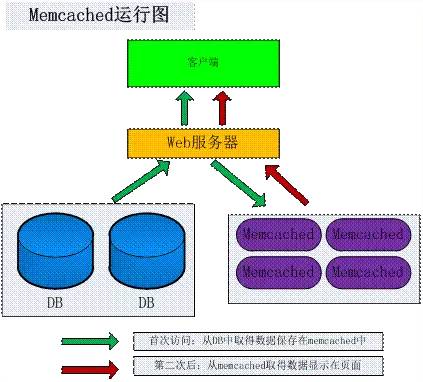
图1
内存分布式算法(Slab Allocator):
memcached的内存分配默认是采用了Slab Allocator的机制分配、管理内,在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。 但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢,Slab Allocator就是为解决该问题而诞生的。
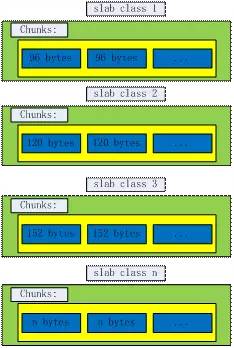
图2
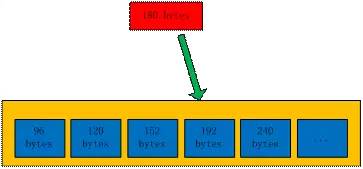
图3
SlabAllocation的名词解释:
Page:分配给Slab的内存空间,默认是1MB。分配给Slab之后根据slab的大小切分成chunk。
Chunk:实际使用的内存空间大小。
Slab Class:特定大小的chunk组。
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,以完全解决内存碎片问题。如图2,Slab Allocation原理相当简单,将分配的内存分割成各种尺寸的块(chunk), 并把尺寸相同的块分成组(chunk的集合)。

图4
如图3,Memcached根据应用端数据大小选择最合适的slab,应用端需要180 bytes字节的内存,会选择192 bytes 的slab。如图4,Memcached中存储着空闲chunk列表,并根据该列表选择chunk,应用端需要180 bytes 的内存,却选择了192 bytes的slab class,这样做的后果是chunk中剩余的12 bytes内存会被浪费掉。对于内存被闲置的处理,如果预先知道客户端发送的数据的使用内存的大小,或者仅缓存大小相同的数据的情况下,只要使用适合数据大小的组的列表,就可以减少浪费。但是想要做到预知客户端发送数据的内存大小比较困难,只能期待以后的版本来解决上述问题了,但是,我们可以根据业务需要来调节slab class的大小,进而减少这种内存闲置造成的内存浪费。
使用GrowthFactor进行内存调优:
Memcached在启动时指定 Growth Factor因子(通过-f选项), 可以控制slab的大小,进而让应用在选择使用slab时,不致更多内存浪费。默认值为1.25。 但是,在该选项出现之前,这个因子曾经固定为2,称为“powers of2”策略。让我们用以前的设置,以verbose模式启动Memcached:
$ memcached -f 2 -vv
下面是启动后的verbose输出:
slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
由上述例子可以看出,从slabclass 1开始,组的内存大小依次增大为原来的2倍。 这样设置导致的问题就是slab之间的差别比较大,有些情况下就会造成内存的浪费。 因此,memcache新版本为尽量减少内存浪费,追加了growth factor这个参数。
来看看现在的默认设置(f=1.25)时的输出:
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
slab class 4: chunk size 184 perslab 5698
slab class 5: chunk size 232 perslab 4519
slab class 6: chunk size 296 perslab 3542
slab class 7: chunk size 376 perslab 2788
slab class 8: chunk size 472 perslab 2221
slab class 9: chunk size 592 perslab 1771
slab class 10: chunk size 744 perslab 1409
可见,组间差距比因子为2时小得多,更适合缓存几百字节的记录。 从上面的输出结果来看,可能会觉得有些计算误差,这些误差是为了保持字节数的对齐而故意设置的。
将Memcached引入产品,或是直接使用默认值进行部署时,最好是重新计算一下数据的预期平均长度,调整growth factor, 以获得最恰当的设置。
Memcached数据过期方式:
Memcached数据过期方式为Lazy Expiration, Memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期,这种技术称为lazy expiration。因此,Memcached不会在过期监视上耗费CPU时间。Memcache的默认最大数据过期时间是30天。
Memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间。顾名思义,这是删除“最近最少使用”的记录的机制。因此,当Memcached的内存空间不足时(无法从slab class 获取到新的空间时),就从最近未被使用的记录中搜索,并将其空间分配给新的记录。
Memcached分布式算法:
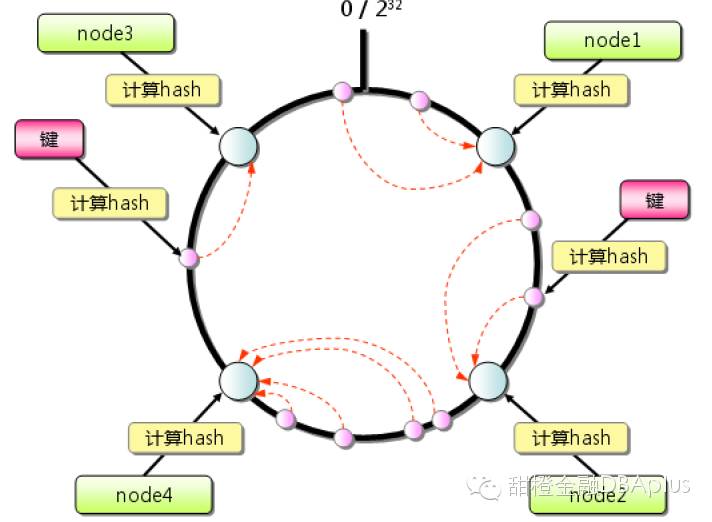
图5
选择服务器算法有两种,一种是根据余数来计算分布,另一种是根据散列算法来计算分布。
余数算法:
先求得键的整数散列值,再除以服务器台数,根据余数确定存取服务器,这种方法计算简单,高效,但在memcached服务器增加或减少时,几乎所有的缓存都会失效。
散列算法:
如图5,先算出memcached服务器的散列值,并将其分布到0到2的32次方的圆上,然后用同样的方法算出存储数据的键的散列值并映射至圆上,最后从数据映射到的位置开始顺时针查找,将数据保存到查找到的第一个服务器上,如果超过2的32次方,依然找不到服务器,就将数据保存到第一台memcached服务器上。如果添加了一台memcached服务器,只在圆上增加服务器的逆时针方向的第一台服务器上的键会受到影响。
