





Kubernetes 的复杂性挑战
Aliware
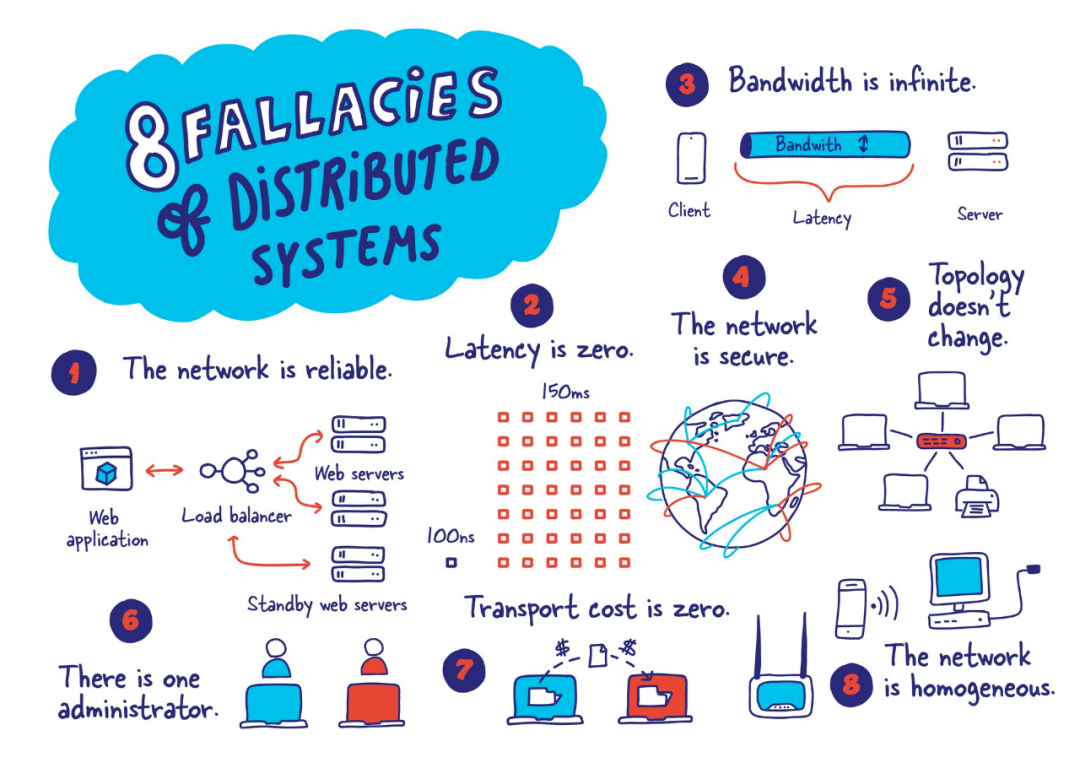
在上世纪 90 年代,Sun 的几位工程师提出了分布式计算的八个谬误[2],这也解释了为什么构建可靠的分布式系统是一项艰巨的工程挑战。
资源调度的复杂性
如何高效地利用计算资源,降低计算成本是资源调度的重要目标。
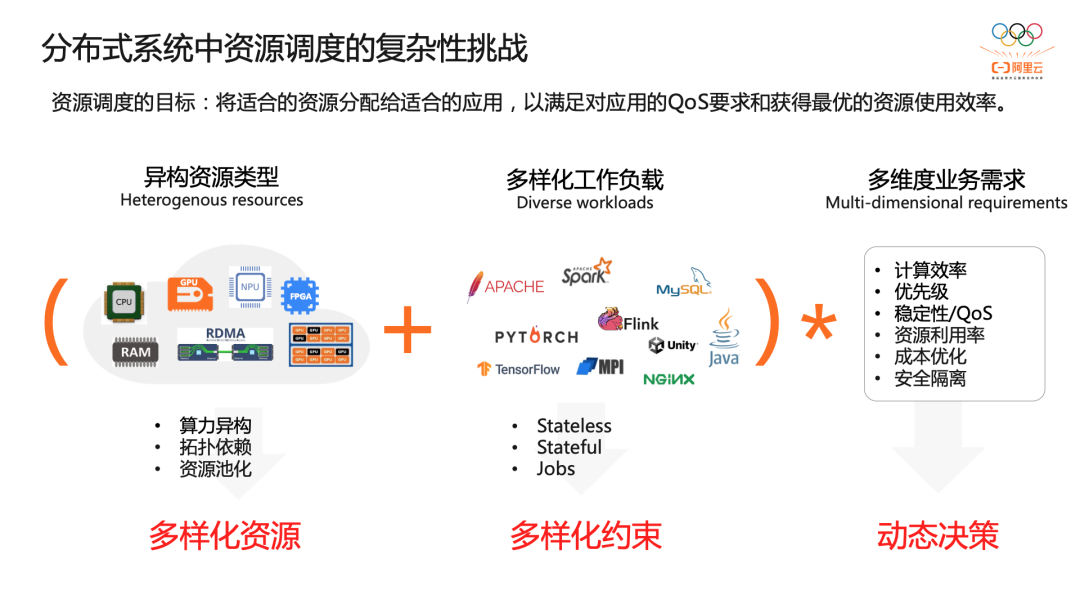
对多形态异构资源的支持,今天应用所需的计算资源不只是简单的 CPU,内存,存储等,而且包括多样化的加速设备,比如 GPU、RDMA 等。而且,为了考虑到计算效率的最优化,要考虑到计算资源之间的拓扑,比如 CPU core 在 numa 节点间的布局,GPU 设备间 NVLink 拓扑等。此外随着高性能网络的的发展,GPU 池化、内存池化等相继出现,给资源调度带来更多的动态性和复杂性。 对多样化的工作负载的支持。从 Stateless 的 Web 应用、微服务应用,到有状态的中间件和数据应用,再到 AI、大数据、HPC 等计算任务类应用。他们对资源申请和使用的方式有不同的需求。 对多维度的业务需求的支持。调度系统在满足应用对资源的需求的同时,也要满足不同的业务需求,比如计算效率,优先级,稳定性,利用率等等。
基础设施环境的多样性
Kubernetes 的解决之道
Aliware
控制循环(Control loops)
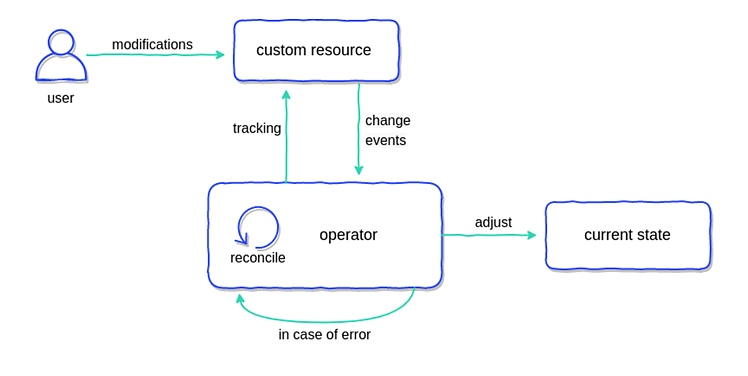
声明式(Declarative)API
基础设施抽象
Kubernetes 遗留的运维复杂性
Aliware
日常维护集群,进行版本升级 平均每个月要进行一次小版本升级 平均每年要进行一到两次大版本升级 日常更新操作系统安全补丁 平均每个月要进行一次 解决容器集群中各种问题应急 每天 n 次 对集群进行容量评估,手动扩缩容 按需
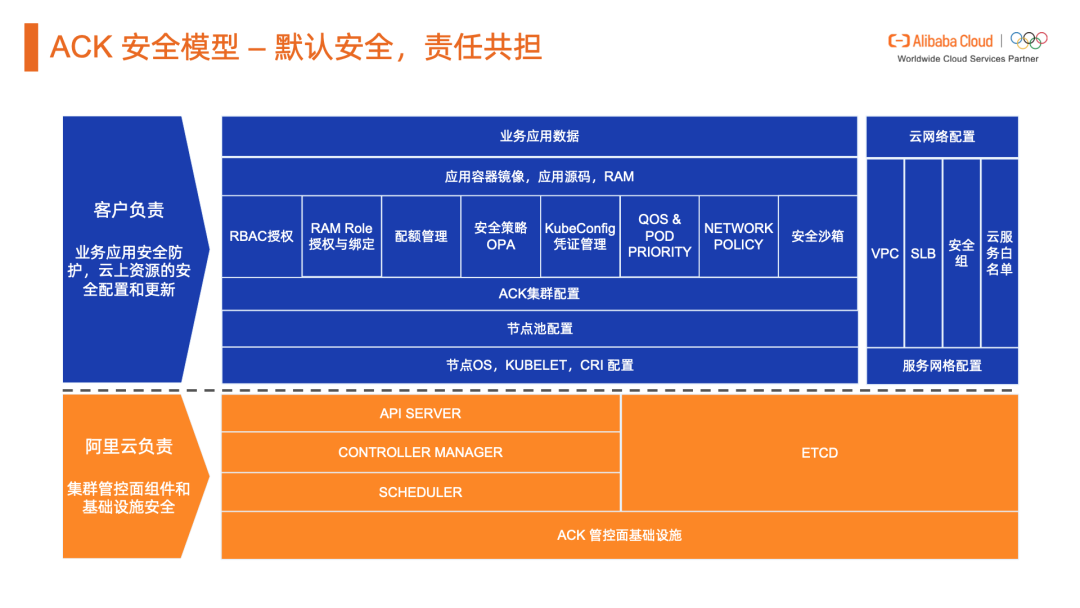
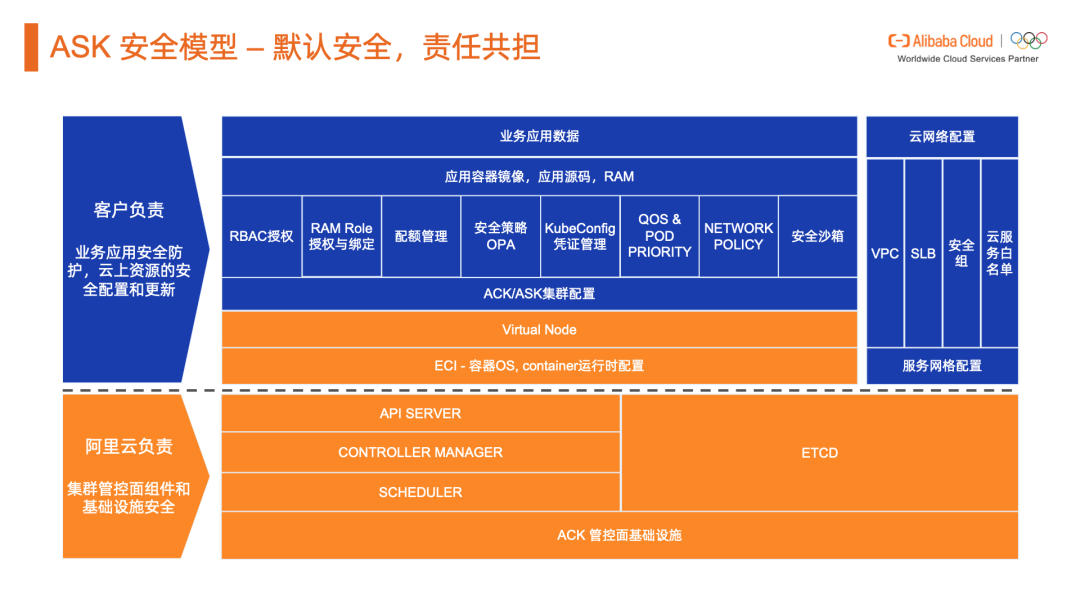
托管 Kubernetes 服务与责任共担模型
Aliware
Kubernetes 节点遗留的复杂性
Aliware
Pod 与节点生命周期不同步 节点就绪后,才能进行 Pod 调度,降低了弹性的效率 节点维护/下线/缩容,需要迁移所有节点上的 Pod,极大增加了弹性的复杂性。 同节点内部 Pod 共享资源 共享内核,扩大了攻击面。用 OS 提供的 namespace,seccomp 等机制无法实现很好的安全隔离。 共享资源,产生相互影响。CPU,内存,I/O,临时存储容量等,有些无法通过 cgroup 进行很好的资源隔离。 容器网络与节点网络独立管理 要为节点,容器、Service 独立配置 CIDR 在跨多个可用区、混合云、或者企业网络拓扑编排等较复杂场景下,大多数客户缺乏足够的能力实现合理的网络规划。 容量规划与弹性配置复杂 需要用户管理节点池,选择合适的节点规格进行扩容,优化整体资源利用率,增加了复杂性。
Serverless Kubernetes 的理想
Aliware
免运维 - 用户无需对 K8s 控制面和数据面进行运维。让用户聚焦业务应用而非底层基础设施管理 按需付费 - 无需预留资源,按应用实际资源使用量费。 简化容量管理 - 让应用可以弹性伸缩,无需关注集群资源的调整。
Serverless Kubernetes 的流派
Aliware
Nodeless Kubernetes
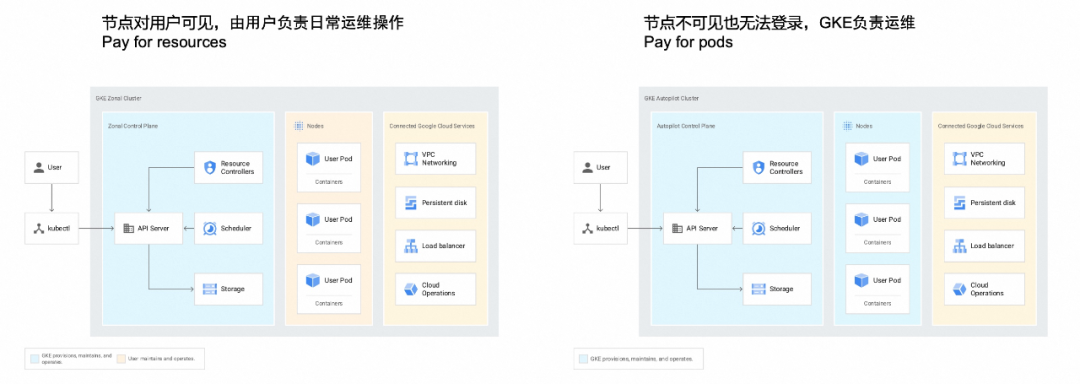
GKE Autopilot 集群节点池/节点对用户不可见,也无法登录进行运维。 用户为应用申请的资源付费,而不是为底层资源进行付费。 用户无需进行容量管理。GKE Autopilot 的调度和计费单位是 Pod,但是扩容的单位仍然是节点实例。当用户部署/扩容应用时,GKE 会先尝试调度到已有节点中;如果资源不足,GKE 服务根据 Pending Pod 来动态创建相应节点池/节点来适配应用;同理当应用删除/缩容时,GKE 服务也会根据情况缩容节点池来释放实际使用资源。
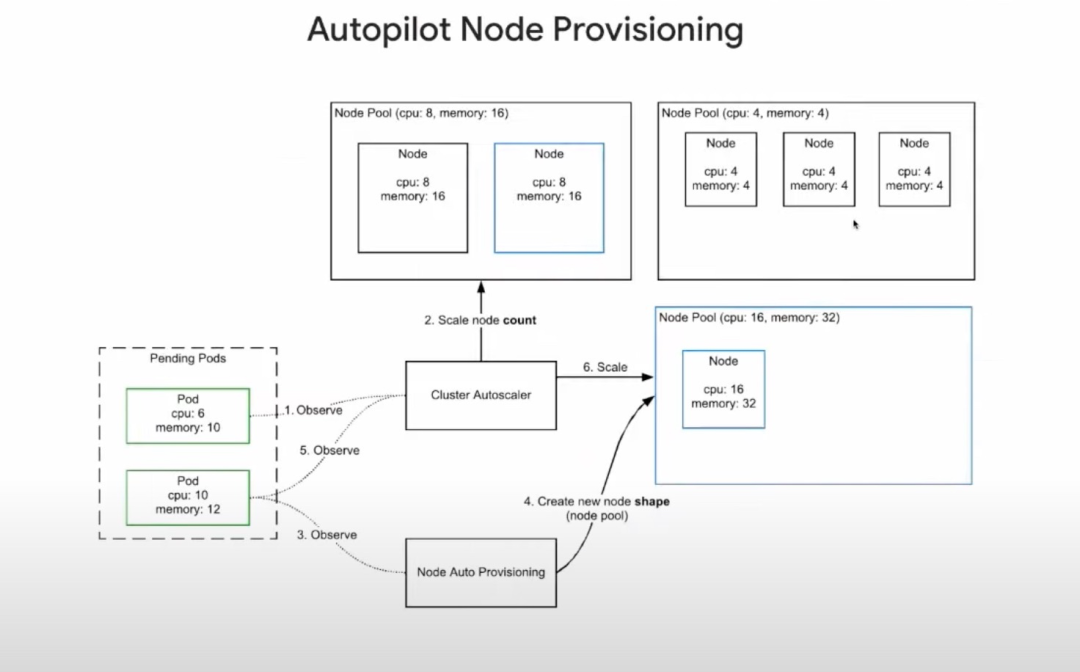
注:GKE Autopilot 基于节点池进行伸缩,每个节点池中实例规格保持一致,整个节点创建流程如下图所示。
网络规划没有简化:依然需要对 K8s 的节点网络 CIDR 进行规划 节点爆炸半径大:如果节点 OS 需要进行更新替换,需要对整个节点上的所有 Pod 进行迁移。 存在资源争抢:一个节点上会运行多个应用,应用间可能存在相互干扰问题, 弹性效率低:集群扩容是需要创建新的虚拟机实例,需要启动一个完整的操作系统,一般而言整个过程需要数分钟。为了降低启动耗时,可以通过气球任务[4] - 一个低优先级、可抢占的占位应用,来提前预留集群资源。(呵呵,感觉和 Serverless 又发生了冲突啊) 存在资源碎片:节点以 VM 作为资源扩容的最小单位,可能会造成一定的资源浪费。如果应用缩容,也会导致节点上存在碎片,需要重新调度实现资源整理。 尚未支持超售:在资源调度上,由于用户无法选择节点规格以及资源超售比例,GKE autopilot 只支持 Guaranteed QoS,也就是 Pod 的 requests 资源和 limits 相等,不支持资源超售,不支持突发的资源需求。技术上存在支持资源超售的可能性,但是 K8s 的超售建立在对节点上应用的合理排布的基础上。由于目前产品形态节点规格和数量对用户不可见,较难实现。
不支持对节点 SSH 访问,因为节点的所有权属于 GKE 而非用户 默认不支持特权容器,防止入侵者通过容器提前发动攻击。 面向 Pod 的云资源授权使用 Workload Identity[5]
注:社区 Cluster Autoscaler 框架存在着一些先天问题。Karpenter 等新的弹性实现升了灵活性、降低了节点管理的复杂性。容器服务相关的工作也在进展中,结合托管节点池可以给用户更加简单的管理体验。
Serverless Container
用户无需关注节点运维和安全修复,降低运维成本; 用户只为 Pod 资源付费; 无需复杂的集群容量规划,按需创建应用 Pod;

无资源争抢:每个 Pod 运行在一个独立的安全沙箱,也就意味着没有多个应用的相互资源干扰; 更高安全性:每个安全沙箱只需安装/开启应用所需的软件包,比如应用没有使用 NAS 存储,其沙箱中无需加载相应的 nfsd 内核模块,这大大减少了安全攻击面;每个应用运行在独立的安全沙箱中,独占 OS 内核,默认强隔离,Serverless Container 相比传统 OS 容器,大大提升了安全性。 无资源碎片:每个沙箱按照 Pod 实际申请资源进行分配,减少了资源碎片的产生,也无需进行频繁的资源重整。 更高的冷启动扩容效率:安全沙箱相比较创建一个完整的虚拟机有更多的优化手段。 更简单高效的网络:每个 Pod 有独立的 IP,无需对节点进行网络规划,进一步简化了容器网络规划的复杂度。而且减少了容器网络在虚拟化网络上的损耗。
不支持与节点相关的 K8s 概念:比如 DaemonSet,Node Port 等。(后面会介绍一些解决之道) 规模化较小:K8s 中 Kubelet,Kube Proxy 这样的节点组件会通过控制循环持续轮询 API Server 状态,实现节点状态与 Pod 真实运行状态、网络、配置的同步。这样的访问操作在 Serverless Container 环境下会大大膨胀。EKS 每个集群最多只支持 1000 个 Fargate,阿里云容器服务通过优化,每集群支持 20000 个任务型实例。但是仍然远小于 ACK 集群中支持的 Pod 数量。 额外的资源开销:每个 Serverless Container 由于拥有独立的内核,相比传统的 OS 容器会有额外的资源开销,此外 Serverless Container 是自治的还有一定的管理资源开销。这些都是每个云厂商希望削减的地方。
Nodeless Kubernetes vs. Serverless Container 对比
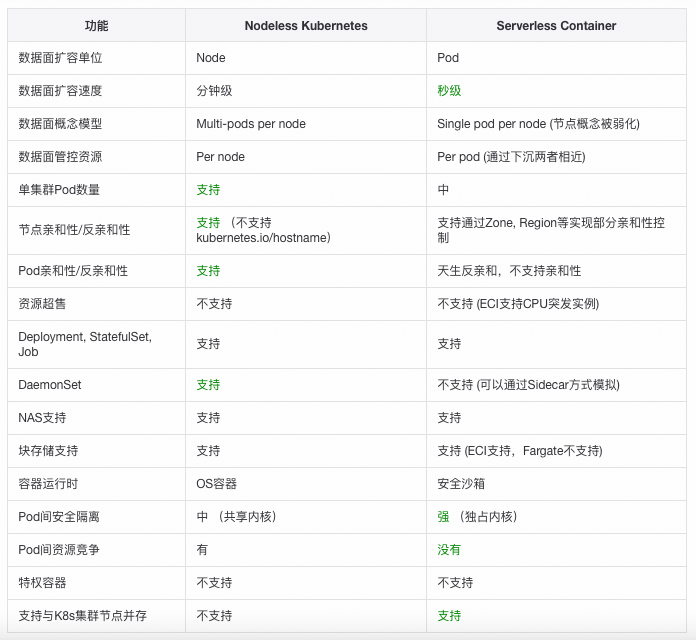
Nodeless 更加注重对兼容性的支持,保留了节点的概念。 Serverless Container 适当绝大部分保障兼容的前提下,更侧重弹性和简化。
未完待续
Aliware
向你发出邀请
扫码即刻参会!

文章转载自阿里巴巴中间件,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
