




介绍
在这个数字时代,我们实际上是在数据的海洋中遨游。但是我们是如何走到这件事的最前沿的呢?MapReduce 和 Hadoop 等技术在一定程度上满足了我们的数据需求;让我们回顾一些想法和事实,在创建我们目前居住的世界的整体视图时要考虑一个事实,即每个人都直接或间接地依赖于我们今天所做的大部分事情的数据?
让我来帮助你; 你手中的那个小设备,你的智能手机,只是你从不同来源消费数据的另一个例子。这不是重点,但问题是如何处理数据以对我们有价值和有意义。
当前的数据格局
物联网和其他一些最新技术的进步增加了对数据的担忧。数据增长速度超过了传统计算机的能力。许多来源预测到 2020 年及以后的数据呈指数级增长。然而,每个人都同意,这个数字海洋的规模将每两年翻一番,从 2010 年到 2020 年增长 50 倍。人类和机器生成的数据共同经历了比传统业务数据快 10 倍的增长速度。机器数据以 50 倍的增长率增长得更快。
资料来源:大数据中的 Mapper 和 Reducer
我们如何利用这些庞大的数据源并将它们转化为可操作的信息?捕获和分析数据并将其转化为有意义的见解是一个复杂的工作流程,它通过无缝混合环境从数据中心转移到云。此外,随着数据的性质从结构化转变为非结构化,“大数据”的概念已经演变并获得了广泛的认可。找到有价值的见解——可以帮助企业、研究、工业和人类的趋势和模式。许多技术已经成为解决方案的一部分。一些获得了接受,而另一些则被抛弃了。因此,接受当前的事态非常重要,因为对于物质化的现实来说,完善我们的处境变得至关重要。
大数据图像:MapReduce 的由来
大数据已经作为一个具体的概念出现并且正在蓬勃发展,但它的起源是不确定的。Diebold (2012) 认为,“大数据”一词可能起源于 Silicon Graphics Inc. 的午餐谈话。然而,从技术上讲,大数据在真空中毫无意义。它的真正潜力只有在用于决策时才能知道。组织需要高效的流程来实现这种基于证据的决策,从而将大量快速变化的多样化数据转化为有意义的洞察力。
毫无疑问,RDBMS、网格计算等技术对大数据的处理做出了不可估量的贡献,但它们并不适合作为解决方案。因此,处理大数据的新技术催生了各种其他技术。最流行的技术是 MapReduce,它使用 MapReduce 编程实现 Map 和 Reduce 的概念。让我们来看看。看看是什么导致了 MapReduce 编程的发展。
MapReduce:进化
那是 1990 年代初,当时互联网正盛。随着大数据的出现,MapReduce 被证明是最有效的解决方案。让我们来看看。查看 MapReduce 技术发展的内容和方式的时间表。
进化时间表:
1997 年:道格切割,雅虎!一名员工开始编写 Lucene 的第一个版本(用于索引网页)。
2001 : Lucene 开源;华盛顿大学毕业生 Mike Cafarella 与 Dough Cutting 合作为整个网络编制索引;他们的努力催生了一个名为 Apache Nutch 的新 Lucene 子项目。
在 indexing、Cutting 和 Cafarella 的现有文件系统中遇到以下问题:
- 在模式可用性中(没有行和列的概念)
- Missing Endurance(一旦写好就永远不会丢失)
- 无法承受故障(CPU、内存、网络)
- 非自动重新平衡(使用磁盘空间)
2003 : 以谷歌文件系统(GFS)和Java的概念,创建了一个新的文件系统,称为NDFS(Nutch分布式文件系统)。
它修复了几个问题,但以下问题仍未解决:
- 毅力
- 容错
为了解决这些问题,出现了分布式处理的想法。在实现这一点时,需要一种用于 NDFS 的算法,该算法将集成同时在多个节点上运行的并行处理。
2004 : google 发表论文 MapReduce;大型集群上的简单数据处理。文章中提到的算法解决了以下问题:
- 并行化
- 分配
- 容错
MapReduce 技术已经发展成为编写处理大量结构化和非结构化数据的应用程序的框架。MapReduce 一词由两个不同的词组成,“Map”和“Re”。
在下一部分中,我们将揭开它是什么的神秘面纱。它是干什么用的?
什么是 MapReduce?
MapReduce 技术是一种使用 MapReduce 编程实现的线性可扩展编程模型。为简化上述陈述,MapReduce 是一个框架,用于编写应用程序,以可靠和故障安全的方式在大型商用硬件集群(数千个节点及更多)上并行处理大量数据(多 TB 数据集等)。——宽容的方式。
编程基于以下功能:
- 地图功能
- 一个归约函数。
每个函数都定义了从一组键值对到另一个的映射。键值对 (KVP) 是一组两个链接的数据项:
- Key:它是一些数据项的唯一标识符,并且
- 值:这可以是以下之一,找到的数据和指向该数据位置的指针。
这些函数不知道数据大小或运行的集群。函数适用于两种类型的数据集,无论是小型还是大型。如果输入数据的大小增加,作业的运行速度会慢一倍。但是,如果将集群大小加倍,则作业的运行速度将与原始作业一样快。
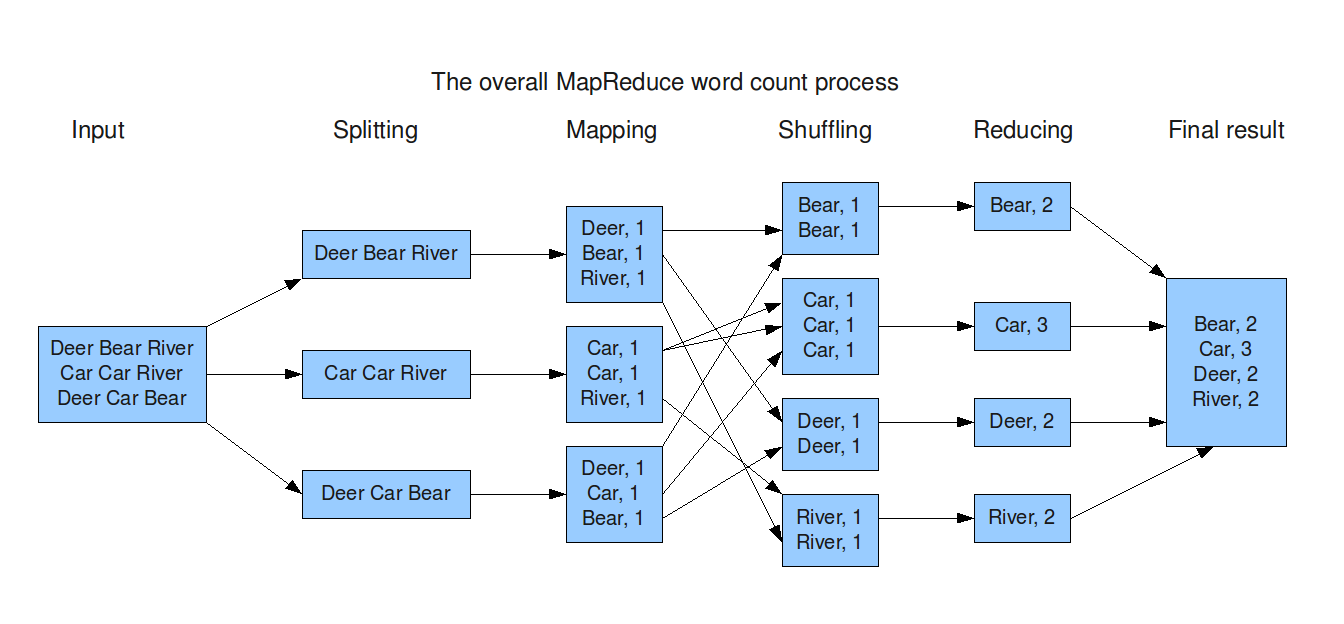
MapReduce:工作流程
总的来说,MapReduce 程序包括两个阶段:
地图阶段:
- 主节点接受输入。
- 将输入分解为更小的子问题。
- 主节点将这些较小的子问题分发给工作节点。
- 工作节点可以再次执行此操作,从而形成多级树结构。
- 工作节点处理较小的问题。
- 它将响应转发回其主节点。
减少阶段:
1. 主节点收集工作节点给出的所有子问题的答案。
2. 结合所有答案,形成原题的输出
MapReduce技术的详细步骤如下:
1. 映射输入准备:系统选择映射处理器,分配输入键值对 K1 进行处理,并为该处理器提供与该键值关联的所有输入数据。
2.运行用户提供的地图代码()。
3. 对每个 K1 键值只执行一次 Map() 代码,并生成由 K2 键值组织的输出。
4. Shuffle map output() 进入Reduce处理器;MapReduce 系统选择 Reduce 处理器,分配一个 K2 键值以使用,并为该处理器提供与该键值关联的任何 Map() 生成的数据。
5. 运行用户提供的 Reduce() 代码——Reduce() 对 Map 步骤中创建的每个 K2 键值只执行一次。
6、为了产生最终的输出,MapReduce系统收集reduce()产生的所有输出,并按照K2的键值排序,产生最终的结果。
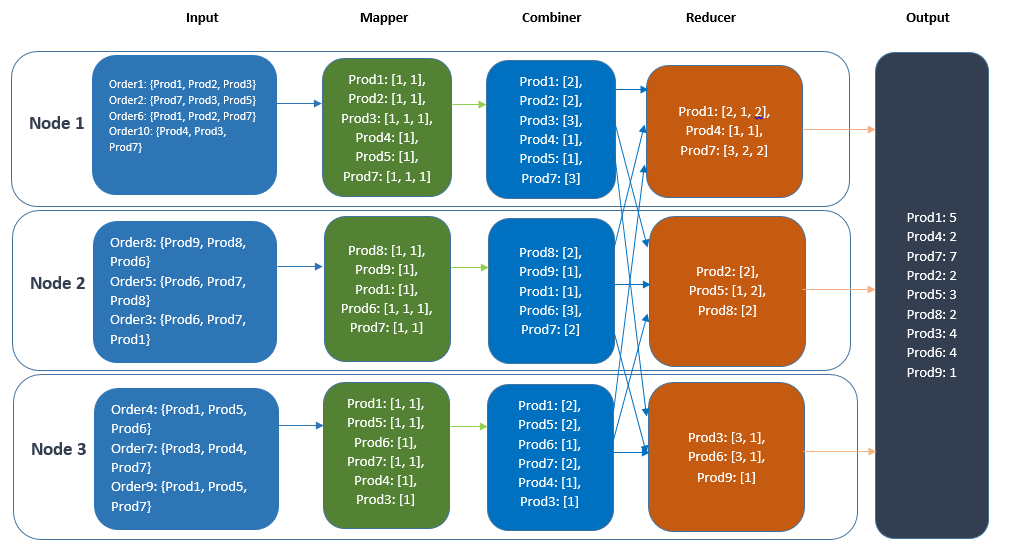
MapReduce 是如何工作的?
商店出售的笔记本电脑示例:
1. 苹果、惠普、联想、富士通、索尼、三星、华硕
具有不同笔记本电脑组合的两个数据集是:
1.数据集1:华硕、索尼、联想、联想、富士通、惠普、索尼、苹果、三星
2.数据集2:华硕、富士通、联想、华硕、惠普、索尼、惠普、苹果、华硕
地图步骤
对数据集中的每条记录,创建一个map(字符串key,字符串值),即map(k1,v1)->list(k2,v2),如下:
1.华硕索尼Lenov”{(“”s”s”,”1””,(””o”y”,”1””,(”Le”o”o”,”1”)}
2.联想富士通Hp{(“Lenovo”,”1”),(“Fujitsu”,”1”),(“Hp”,”1”)}
3.索尼苹果Samsun”{(“”o”y”,”1””,(”A”p”e”,”1””,(”Sam”u”g”,”1”)}
4.华硕富士通Lenov”{(“”s”s”,”1””,(“Fuj”t”u”,”1””,(“Le”o”o”,”1”)}
5.华硕惠普索尼{(“华硕”,“1”),(“惠普”,“1”),(“索尼”,“1”)}
6. HP Apple Asu”{““”p”,”1””,(“A”p”e”,”1””,(“”s”s”,”1”)}
Nelet'set 看看 reduce 步骤中做了什么:
减少步长
对于上面的每一个map结果,得到的reduce(string key, iterator values),即reduce(k2, list(v2))-->list(v2),如下:
1.减少(“苹果”,)-> 2
2. 降低 (“Hp”, )–>3
3.减少(“诺基亚”,)-> 4
4.减少(“富士通”,)->2
5.减少(“索尼”,)->3
6.减少(“三星”,)->1
7.减少(“华硕”,)-> 4
使用 MapReduce 编程可以轻松解决基本的计算机销售问题。MapReduce 编程是许多应用程序中分布式编程模型的核心,用于解决各种实际行业中的大数据问题。有许多具有挑战性的问题,例如数据分析、日志分析、推荐引擎、欺诈检测和用户行为分析,MapReduce 适合作为一种实用的解决方案。
MapReduce 的应用
并行处理海量数据的功能导致 MapReduce 在各种数据密集型环境中的实施并用于各个行业。
1.基于分布式模式的搜索:使用MapReduce提供的分布式grep命令在网络上分布的给定文本中搜索模式。
2. 地理空间查询处理:随着基于位置的服务技术的进步,MapReduce 有助于在谷歌地图中找到给定位置的最短路线。
3、分布式排序:在MapReduce中使用分布式排序,将数据以有序的方式排列,分布在多个位置。
4. Web Link Graph Traversal:求解一个大图,也称为web graph,使用MapReduce编程。
5. 机器学习应用:MapReduce 有助于机器学习,因为它有助于构建从数据中学习的系统,而无需针对所有条件进行显式编程。
6. 数据聚类:在数据聚类中使用 MapReduce 来解决由于处理中使用的大量数据而产生的计算复杂性,方法是根据某些标准和许多其他应用将完整的数据集划分为小的数据子集。
未来范围
1. 框架 MapReduce 与其他技术将带来新的和更易于访问的编程技术,用于处理具有结构化和非结构化数据的海量数据存储。
2. 许多组织都在发明过程中,因此预计未来几年会有不同的 MapReduce 框架具有附加功能。
3. 许多研究正在进行以扩展 MapReduce 的新特性和机制,以针对一组新问题对其进行改进。
4. 随着日常数据问题的复杂解决方案,MapReduce 似乎越来越多。
5. 每一种并行技术都有对可扩展性的需求。自上一个版本以来,带有附加实现的 MapReduce 具有真正的可扩展性,将节点限制扩展到 4,000 以上。
结论
一段时间以来,具有良好并行编程模型的高度可扩展数据存储一直是业界面临的挑战。同时,可以说 MapReduce 编程模型并不能解决所有问题。然而,它是许多数据和相关任务的强大解决方案。最后,随着我们的世界迅速接近数字化的极端,未来的数据需求会随着时间而变化。
- 大数据已经作为一个具体的概念出现并且正在蓬勃发展,但它的起源是不确定的。Diebold (2012) 认为,“rm”大数据可能起源于 Silicon Graphics Inc. 的午餐对话。然而,从技术上讲,大数据在真空中毫无意义。
- 物联网和其他一些最新技术的进步增加了对数据的担忧。数据增长速度超过了传统计算机的能力。许多来源预测到 2020 年及以后的数据呈指数级增长。
- 在数据聚类中使用 MapReduce 通过根据某些标准和许多其他应用程序将完整的数据集划分为小的数据子集来解决由于处理中使用的大量数据而产生的计算复杂性。
原文标题:The Origin and Future Scope of MapReduce in Big Data
原文作者:Gitesh Dhore
原文链接:https://www.analyticsvidhya.com/blog/2022/10/the-origin-and-future-scope-of-mapreduce-in-big-data/
