




前言
此案例介绍因为MySQL索引下探参数eq_range_index_dive_limit设置问题,导致包含in表达式的SQL执行计划不稳定。
1 环境信息
RDS MySQL:5.7
2 错误描述
业务反馈,线上某个云RDS数据库,查询语句里面,where过滤条件有in表达式(in里面有多个值),当值的的数量超过100个后,查询不走索引(全表扫描);如果小于100个,就可以走该字段的索引。
select col1, col2, ....., colN from t1 where code1 in ( 'S100809280' , 'S100601788' , 'S100204388' , 'S100198706' , 'S100202941' , 'S100829425' , 'S100722717' , 'S100200238' , 'S100103341' , 'S100103224' , 'S100103478' , 'S100170079' , 'S100559854' , 'S100601936' , 'S100160005' , 'S100103223' , 'S100201577' , 'S100602024' , 'S101073651' , 'S100602104' , 'S101015799' , 'S100081466' , 'S100204897' , 'S100642083' , 'S101770606' , 'S100559164' , 'S100103242' , 'S100191428' , 'S100161978' , 'S100103533' , 'S100103241' , 'S100212199' , 'S100103234' , 'S100103233' , 'S100211435' , 'S100103470' , 'S100642143' , 'S100559227' , 'S100103471' , 'S100103383' , 'S100170475' , 'S100559241' , 'S100840238' , 'S100212356' , 'S100212350' , 'S100359991' , 'S100201421' , 'S100103439' , 'S100192508' , 'S100225372' , 'S100821468' , 'S100192566' , 'S100205406' , 'S100420398' , 'S100169168' , 'S100555710' , 'S100205438' , 'S100186856' , 'S100533307' , 'S100471335' , 'S100192976' , 'S100513283' , 'S100114066' , 'S100103490' , 'S100824251' , 'S100800010' , 'S100195066' , 'S100103420' , 'S100655582' , 'S100523113' , 'S100203199' , 'S100161990' , 'S100205694' , 'S100203240' , 'S100211457' , 'S100595087' , 'S100211805' , 'S101077103' , 'S100203159' , 'S100731134' , 'S101161307' , 'S100754053' , 'S100103436' , 'S100208961' , 'S101213023' , 'S101016396' , 'S100217812' , 'S100192159' , 'S100373711' , 'S100770037' , 'S100204361' , 'S100206111' , 'S100829338' , 'S100163599' , 'S100204748' , 'S100950944' , 'S100950888' , 'S101106892' , 'S100103229' , 'S100204717' ) and activity_type = 1;后台验证了一下执行计划,确实如上面描述描述。
3 排查
3.1 查看建表语句
CREATE TABLE `t1` (
`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`col1` varchar(32) DEFAULT NULL,
..........
`activity_type` tinyint(4) DEFAULT '0',
`code1` varchar(32) DEFAULT '',
`repeat` tinyint(4) DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_code1` (`code1`),
KEY `idx_activity_type` (`activity_type`)
) ENGINE=InnoDB AUTO_INCREMENT=13406057 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;开始以为是优化器代价选择的原因。当in里面多了一个值后,优化器认为走全表扫描的代价比走索引代价低。
进一步测试后发现,去掉上面SQL语句in里面任何一个或多个值,均会走索引,并且删除的值并没有明显的数据倾斜。
3.2 eq_range_index_dive_limit参数
后来想到可能是索引下探参数(eq_range_index_dive_limit)问题。
- 大部分人喜欢叫索引潜水;
- 个人觉得oracle的绑定变量窥探和这个类似;
- 索引下探使用会有一些限制,参考3.6;
这个参数对应特性叫索引下探,主要是数据倾斜的时候比较有用。当数据存在倾斜时,索引统计信息可能不准,会导致执行计划不准或者不稳定。
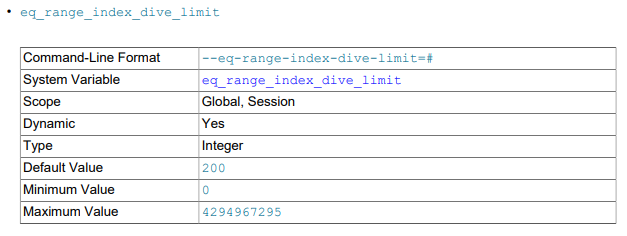
MySQL 5.7和8.0,该参数默认为200;5.6,该参数默认为10。
3.3 官方文档该参数介绍
This variable indicates the number of equality ranges in an equality comparison condition when
the optimizer should switch from using index dives to index statistics in estimating the number of
qualifying rows. It applies to evaluation of expressions that have either of these equivalent forms,
where the optimizer uses a nonunique index to look up col_name values:
当优化器估计满足条件的行数时,该参数控制优化器从使用索引下探评估,切换到使用索引统计信息评估。
该参数值表示相等比较条件中相等范围的数量。
它适用于具有下面这些等效形式的表达式的评估,其中优化器使用非唯一索引来查找 col_name 值:
col_name IN(val1, ..., valN)
col_name = val1 OR ... OR col_name = valNIn both cases, the expression contains N equality ranges. The optimizer can make row
estimates using index dives or index statistics. 对于上面两种语句,表达式都包含 N 个相等范围。优化器可以使用索引下探或索引统计信息进行行估计。
If eq_range_index_dive_limit is
greater than 0, the optimizer uses existing index statistics instead of index dives if there are
eq_range_index_dive_limit or more equality ranges. Thus, to permit use of index dives for up
to N equality ranges, set eq_range_index_dive_limit to N + 1. To disable use of index statistics
and always use index dives regardless of N, set eq_range_index_dive_limit to 0.如果 0 < eq_range_index_dive_limit <= N - 1,优化器对这N - 1 个相等范围进行索引下探,得到准确的行评估,产生相对准确的执行计划;
如果 eq_range_index_dive_limit > N - 1,优化器使用现有的索引统计信息进行行评估;
如果 eq_range_index_dive_limit = 0,则会禁用索引统计信息,始终使用索引下探进行行评估。
无论 N 多少,始终使用索引下探,将 eq_range_index_dive_limit 设置为 0。
To update table index statistics for best estimates, use ANALYZE TABLE.可以通过使用 ANALYZE TABLE 更新表的索引统计信息,以获得最佳行估计。
For more information, see Equality Range Optimization of Many-Valued Comparisons有关详细信息,请参阅多值比较的等式范围优化。
3.4 多值比较的相等范围优化
Consider these expressions, where col_name is an indexed column:
下面的表达式,检索字段 col_name 上有索引:
col_name IN(val1, ..., valN)
col_name = val1 OR ... OR col_name = valNEach expression is true if col_name is equal to any of several values. These comparisons are equality
range comparisons (where the “range” is a single value). The optimizer estimates the cost of reading
qualifying rows for equality range comparisons as follows:
如果 col_name 等于多个值中的任何一个,则每个表达式都为真。这些比较是相等范围比较(其中“范围”是单个值)。
对应相等范围比较,优化器估计读取符合条件的行的成本如下:
• If there is a unique index on col_name, the row estimate for each range is 1 because at most one row can have the given value.
• Otherwise, any index on col_name is nonunique and the optimizer can estimate the row count for each range using dives into the index or index statistics.
如果 col_name 上存在唯一索引,则每个范围的行估计值为 1,因为最多一行可以具有给定值。
否则,col_name 上的任何索引都是非唯一的,优化器可以通过索引下探或索引统计信息来估计每个范围的行数,进行行评估。
With index dives, the optimizer makes a dive at each end of a range and uses the number of rows in
the range as the estimate. For example, the expression col_name IN (10, 20, 30) has three
equality ranges and the optimizer makes two dives per range to generate a row estimate. Each pair of
dives yields an estimate of the number of rows that have the given value.
使用索引下探,优化器在范围的每一端进行下探,并使用在此范围内的行数作为估计值。
例如,表达式 col_name IN (10, 20, 30) 有三个相等范围,优化器会对每个范围进行两次下探,来生成行估计。每个范围的两次下探,都会产生满足给定值的行数的估计值。
开启 optimizer_trace 追踪执行计划可以验证
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_col_name",
"ranges": [
"10 <= coln_name <= 10",
"20 <= coln_name <= 20",
"30 <= coln_name <= 30"
],
"index_dives_for_eq_ranges": true, --此处说明使用了索引下探
3.5 比较
Index dives provide accurate row estimates, but as the number of comparison values in the expression increases, the optimizer takes longer to generate a row estimate.
Use of index statistics is less accurate than index dives but permits faster row estimation for large value lists.
索引下探虽然可以提供准确的行估计,但随着表达式中比较值数量的增加,优化器需要更长的时间来生成行估计;
使用索引统计信息的到的行估计不如索引下探准确,但当表达式中有超多比较值的时候,使用索引统计信息更快的行估计。
3.6 跳过使用索引下探进行行估计
Even under conditions when index dives would otherwise be used, they are skipped for queries that satisfy all these conditions:即使满足使用索引下探的条件,但是如果查询满足下面所有条件,该查询也不会使用索引下探进行行估计。
• A single-index FORCE INDEX index hint is present. The idea is that if index use is forced, there is nothing to be gained from the additional overhead of performing dives into the index.
• The index is nonunique and not a FULLTEXT index.
• No subquery is present.
• No DISTINCT, GROUP BY, or ORDER BY clause is present.
Those dive-skipping conditions apply only for single-table queries. Index dives are not skipped for multiple-table queries (joins).
- 查询在单列索引上使用了hint,来强制使用索引;
- 该列上索引为非唯一索引,并且不是全文索引;
- 该查询不存在子查询;
- 不存在 DISTINCT、GROUP BY 或 ORDER BY 子句;
- 该查询只是针对单个表,不是多表通过join关联查询;
上面查询满足5个条件,可以跳过使用索引下探进行行评估的描述,MySQL 5.7 和MySQL 8.0 官方文档描述是一致的。但是 8.0 多出如下描述:
Prior to MySQL 8.0, there is no way of skipping the use of index dives to estimate index usefulness,
except by using the eq_range_index_dive_limit system variable. In MySQL 8.0, index dive
skipping is possible for queries that satisfy all these conditions:MySQL 8.0版本之前,除了使用 eq_range_index_dive_limit 系统变量外,没有办法跳过索引下探;在MySQL 8.0版本中,如果满足上面五个条件,是可能跳过索引下探的。
For EXPLAIN FOR CONNECTION, the output changes as follows if index dives are skipped:
• For traditional output, the rows and filtered values are NULL.
• For JSON output, rows_examined_per_scan and rows_produced_per_join do not appear,skip_index_dive_due_to_force is true, and cost calculations are not accurate.
Without FOR CONNECTION, EXPLAIN output does not change when index dives are skipped.
After execution of a query for which index dives are skipped, the corresponding row in the
INFORMATION_SCHEMA.OPTIMIZER_TRACE table contains an index_dives_for_range_access
value of skipped_due_to_force_index.5.7 版本上,虽然官方文档也描述了跳过索引下探的条件,但是经过测试,查询即使满足上面5个条件,也不会跳过索引下探;具体测试过程参见6.2
8.0 版本则可以。具体测试过程参见6.3
For EXPLAIN FOR CONNECTION, the output changes as follows if index dives are skipped:
• For traditional output, the rows and filtered values are NULL.
• For JSON output, rows_examined_per_scan and rows_produced_per_join do not appear,skip_index_dive_due_to_force is true, and cost calculations are not accurate.
如果使用EXPLAIN FOR CONNECTION查看正在执行语句的执行计划,该语句如果跳过索引下探,输出会有如下变化。
Without FOR CONNECTION, EXPLAIN output does not change when index dives are skipped.
只使用EXPLAIN生成的执行计划,即使跳过索引下探,执行计划输出也看不出变化。
After execution of a query for which index dives are skipped, the corresponding row in the
INFORMATION_SCHEMA.OPTIMIZER_TRACE table contains an index_dives_for_range_access
value of skipped_due_to_force_index.如果开启了optimezer_trace查看执行计划,如果跳过了索引下探,输出信息里可以看到"index_dives_for_range_access": "skipped_due_to_force_index",而不是"index_dives_for_range_access": "true"
3.5 线上库参数值
[root@test][test]> show variables like '%eq_range_index_dive_limit%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| eq_range_index_dive_limit | 100 |
+---------------------------+-------+
1 row in set (0.00 sec)开启 optimizer_trace 追踪执行计划,in表达式里面值超过100后
select * from information_schema.optimizer_trace\G;可以看到
"index_dives_for_eq_ranges": false确实没有使用索引下探。
4 原因
线上设置的100,可能是rds当时版本的默认值。当IN表达式里有100个值,也就是N=100时,eq_range_index_dive_limit > N - 1,优化器使用现有的索引统计信息进行行评估,而优化器认为,使用全表扫描的代价比索引的代价低。
后面业务也反馈过类似问题,比如并发执行的同一个SQL语句,IN表达式里面值个数一样,只是值不一样,会出现有的SQL全表扫描,有的SQL索引查询情况,也是一样问题导致。
5 解决方案
该SQL业务频繁用到,考虑调大该参数。调大到多少业务评估,最终调大到200。
6 补充
6.1 造数据
CREATE TABLE `t1` (
`id` bigint(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL,
`phone` int(11) DEFAULT NULL,
`stu` int(11) DEFAULT NULL,
`stu2` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_stu` (`stu`)
) ENGINE = InnoDB AUTO_INCREMENT = 201 DEFAULT CHARSET = utf8mb4;INSERT INTO
`t1`
VALUES
(2, '2', NULL, 2, NULL),(3, '3', NULL, 3, NULL),(4, 'b', NULL, 4, NULL),(5, 'c', NULL, 5, NULL),(8, 'c', NULL, 8, NULL),(10, 'c', NULL, 10, NULL),(11, 'd', NULL, 11, NULL),(13, 'c', NULL, 13, NULL),(200, 'cccccccccccccccccccc', NULL, 200, NULL),(300, 'a', NULL, 300, NULL);[root@localhost] {14:28:26} (d2) [17]> select * from t1;
+-----+----------------------+-------+------+------+
| id | name | phone | stu | stu2 |
+-----+----------------------+-------+------+------+
| 2 | 2 | NULL | 2 | NULL |
| 3 | 3 | NULL | 3 | NULL |
| 4 | b | NULL | 4 | NULL |
| 5 | c | NULL | 5 | NULL |
| 8 | c | NULL | 8 | NULL |
| 10 | c | NULL | 10 | NULL |
| 11 | d | NULL | 11 | NULL |
| 13 | c | NULL | 13 | NULL |
| 200 | cccccccccccccccccccc | NULL | 200 | NULL |
| 300 | a | NULL | 300 | NULL |
+-----+----------------------+-------+------+------+
10 rows in set (0.00 sec)
[root@localhost] {14:28:30} (d2) [18]> show variables like '%dive%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| eq_range_index_dive_limit | 200 |
+---------------------------+-------+
1 row in set (0.04 sec)
开启optimizer_trace:
SET optimizer_trace="enabled=on"; 6.2 5.7 版本测试
[root@localhost] {14:33:02} (d2) [6]>select version();
+------------+
| version() |
+------------+
| 5.7.22-log |
+------------+
1 row in set (0.00 sec)
[root@localhost] {14:33:06} (d2) [7]> select * from t1 where stu in(3,5,100);
+----+------+-------+------+------+
| id | name | phone | stu | stu2 |
+----+------+-------+------+------+
| 3 | 3 | NULL | 3 | NULL |
| 5 | c | NULL | 5 | NULL |
+----+------+-------+------+------+
2 rows in set (0.00 sec)
[root@localhost] {14:33:09} (d2) [8]>select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: select * from t1 where stu in(3,5,100)
TRACE: {
"steps": [
........省略.............
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_stu",
"ranges": [
"3 <= stu <= 3",
"5 <= stu <= 5",
"100 <= stu <= 100"
],
"index_dives_for_eq_ranges": true, --确实使用索引下探
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 3,
"cost": 6.61,
"chosen": false,
"cause": "cost"
}
],
查询加上force index的hint,使该查询满足跳过索引下探的5个条件,再次测试,执行计划上没看出区别
[root@localhost] {14:33:39} (d2) [9]>select * from t1 force index(idx_stu) where stu in(3,5,100);
+----+------+-------+------+------+
| id | name | phone | stu | stu2 |
+----+------+-------+------+------+
| 3 | 3 | NULL | 3 | NULL |
| 5 | c | NULL | 5 | NULL |
+----+------+-------+------+------+
2 rows in set (0.00 sec)
[root@localhost] {14:37:03} (d2) [10]>select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: select * from t1 force index(idx_stu) where stu in(3,5,100)
TRACE: {
"steps": [
........省略.............
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_stu",
"ranges": [
"3 <= stu <= 3",
"5 <= stu <= 5",
"100 <= stu <= 100"
],
"index_dives_for_eq_ranges": true, --依旧使用了索引下探
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 3,
"cost": 6.61,
"chosen": true
}
6.3 8.0 版本测试
[root@localhost] {14:39:20} (d2) [24]> select version();
+-----------+
| version() |
+-----------+
| 8.0.16 |
+-----------+
1 row in set (0.00 sec)
[root@localhost] {14:39:23} (d2) [25]> select * from t1 where stu in(3,5,100);;
+----+------+-------+------+------+
| id | name | phone | stu | stu2 |
+----+------+-------+------+------+
| 3 | 3 | NULL | 3 | NULL |
| 5 | c | NULL | 5 | NULL |
+----+------+-------+------+------+
2 rows in set (0.01 sec)
ERROR:
No query specified
[root@localhost] {14:39:26} (d2) [26]> select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: select * from t1 where stu in(3,5,100)
TRACE: {
"steps": [
........省略.............
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_stu",
"ranges": [
"3 <= stu <= 3",
"5 <= stu <= 5",
"100 <= stu <= 100"
],
"index_dives_for_eq_ranges": true, --使用了索引下探
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": 3,
"cost": 1.81,
"chosen": true
}
],
查询加上force index的hint,使该查询满足跳过索引下探的5个条件,再次测试,执行计划上看到跳过了索引下探
[root@localhost] {14:41:31} (d2) [28]> select * from t1 force index(idx_stu) where stu in(3,5,100);
+----+------+-------+------+------+
| id | name | phone | stu | stu2 |
+----+------+-------+------+------+
| 3 | 3 | NULL | 3 | NULL |
| 5 | c | NULL | 5 | NULL |
+----+------+-------+------+------+
2 rows in set (0.00 sec)
[root@localhost] {14:41:36} (d2) [29]> select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: select * from t1 force index(idx_stu) where stu in(3,5,100)
TRACE: {
"steps": [
........省略.............
"analyzing_range_alternatives": {
"range_scan_alternatives": [
{
"index": "idx_stu",
"ranges": [
"3 <= stu <= 3",
"5 <= stu <= 5",
"100 <= stu <= 100"
],
"index_dives_for_range_access": "skipped_due_to_force_index", --跳过了索引下探
"rowid_ordered": false,
"using_mrr": false,
"index_only": false,
"rows": "not applicable",
"cost": "not applicable",
"chosen": true
}
],
