





(CSDN博主:写代码也要符合基本法)
长久以来,关于 Oracle 中 COUNT 函数的使用可谓众说纷纭,江湖门派林立,直叫人摸不着头(tou)脑(fa)。

SQL> SELECT COUNT(NULL) FROM cux_count_test;COUNT(NULL)-----------0
十万行数据直接给你整没
SQL> SELECT COUNT(*) FROM (SELECT NULL, NULL FROM dual);COUNT(*)----------1
由此我们可知,COUNT(*) 和 COUNT(COL) 的区别:同上。
SQL> SELECT COUNT(*) FROM cux_count_test;----------------------------------------------------------| Id | Operation | Name | Cost (%CPU)|----------------------------------------------------------| 0 | SELECT STATEMENT | | 759 (100)|| 1 | SORT AGGREGATE | | || 2 | TABLE ACCESS FULL| CUX_COUNT_TEST | 759 (1)|----------------------------------------------------------
执行计划中甚至没有 BYTES 信息。
DECLAREl_begin_time NUMBER;l_end_time NUMBER;l_count NUMBER;BEGINFOR j IN 1 .. 50 LOOPl_begin_time := dbms_utility.get_time;FOR k IN 1 .. 100 LOOPEXECUTE IMMEDIATE 'select count(col' || j || ') from cux_count_test'INTO l_count;END LOOP;l_end_time := dbms_utility.get_time;dbms_output.put_line((l_end_time - l_begin_time) 100);END LOOP;END;
将运行结果复制到 Excel,使用生涩的手法制作一张折线图:
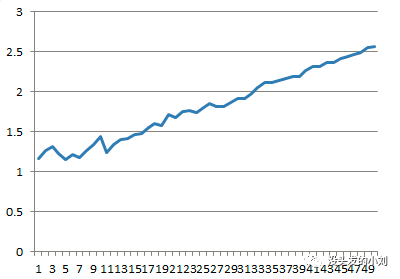
可见,列在表中的位置越靠后,对其做聚合统计所需时间就越多。
SQL> SELECT COUNT(col1) FROM cux_count_test;----------------------------------------------------------| Id | Operation | Name | Cost (%CPU)|----------------------------------------------------------| 0 | SELECT STATEMENT | | 759 (100)|| 1 | SORT AGGREGATE | | || 2 | TABLE ACCESS FULL| CUX_COUNT_TEST | 759 (1)|----------------------------------------------------------SQL> SELECT COUNT(col50) FROM cux_count_test;----------------------------------------------------------| Id | Operation | Name | Cost (%CPU)|----------------------------------------------------------| 0 | SELECT STATEMENT | | 759 (100)|| 1 | SORT AGGREGATE | | || 2 | TABLE ACCESS FULL| CUX_COUNT_TEST | 759 (1)|----------------------------------------------------------
原理至少有两个,单列的B树索引不会存储列中的空值,如此在只计算索引列的行数时,访问索引结构完全无需回表。
例如我们在实验表第一列增加索引后再观察执行计划的变化:
SQL> SELECT COUNT(col1) FROM cux_count_test;-----------------------------------------------------------| Id | Operation | Name | Cost (%CPU)|-----------------------------------------------------------| 0 | SELECT STATEMENT | | 224 (100)|| 1 | SORT AGGREGATE | | || 2 | INDEX FULL SCAN| CUX_COUNT_TEST_N1 | 224 (2)|-----------------------------------------------------------
不仅完全忽略了字节信息,而且执行成本大大降低,这是因为语句仅访问了体积更小的索引块,而不需再访问表数据块。
最后,回归到 COUNT 执行的工作本质上,无非就是数数,此刻我们关注编码需求本身,如果可以让 COUNT 去数更少行数的结果集就能满足我们的需要,岂不美哉?
比如,我们只想知道表中是否存在符合某些条件的记录,不会真的有人会实在到把这些记录每一行都去数一遍吧,不会吧,不会吧?
SQL> SELECT COUNT(1) FROM cux_count_test WHERE col2 = 1;------------------------------------------------------------------| Id | Operation | Name | Bytes | Cost (%CPU)|------------------------------------------------------------------| 0 | SELECT STATEMENT | | | 760 (100)|| 1 | SORT AGGREGATE | | 13 | ||* 2 | TABLE ACCESS FULL| CUX_COUNT_TEST | 1144 | 760 (1)|------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - filter("COL2"=1)SQL> SELECT COUNT(1)2 FROM cux_count_test3 WHERE col2 = 14 AND rownum = 1;-------------------------------------------------------------------| Id | Operation | Name | Bytes | Cost (%CPU)|-------------------------------------------------------------------| 0 | SELECT STATEMENT | | | 760 (100)|| 1 | SORT AGGREGATE | | 13 | ||* 2 | COUNT STOPKEY | | | ||* 3 | TABLE ACCESS FULL| CUX_COUNT_TEST | 1144 | 760 (1)|-------------------------------------------------------------------Predicate Information (identified by operation id):---------------------------------------------------2 - filter(ROWNUM=1)3 - filter("COL2"=1)


文章转载自SQL干货分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
