






CREATE TABLE demo_checkin_history ASSELECT user_id, MAX(checkin_date) checkin_dateFROM (SELECT ceil(LEVEL 31) user_id,to_date('20200701', 'yyyymmdd') + 31 * dbms_random.value checkin_dateFROM dualCONNECT BY LEVEL <= 31 * 5)GROUP BY user_id, trunc(checkin_date);

SELECT t.user_id,t.checkin_date checkin_date_from,connect_by_root t.checkin_date checkin_date_to,LEVEL daysFROM demo_checkin_history tWHERE connect_by_isleaf = 1START WITH t.checkin_date =(SELECT MAX(u.checkin_date)FROM demo_checkin_history uWHERE u.user_id = t.user_id)CONNECT BY PRIOR trunc(t.checkin_date) = trunc(t.checkin_date) + 1AND PRIOR t.user_id = t.user_idORDER BY days DESC, checkin_date_from DESC;
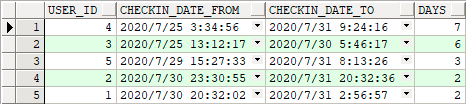

前面是找出每个用户上月最后一次连续签到的数据,现在比方说老(diao)板(mao)改主意了,他想看看每个用户上月的最大连续签到天数对比
新需求对于我们上例程序的最大挑战在于,根结点定位规则变化了,而且是由相对固定变成了相对不定
当然,简单粗暴的办法是去掉 START WITH 子句,任由数据库从每一行分别去递归,最后找到每个客户的最大的 LEVEL 值就完事儿
但考虑到实际业务场景中,如果只有五个用户,那公司也就倒闭了,需要这么大费周章去计算报表的,用户量没准儿是上万的,百万行量级的表去放飞自我的反复递归,带来的必定是老板的怒火性能的浪费
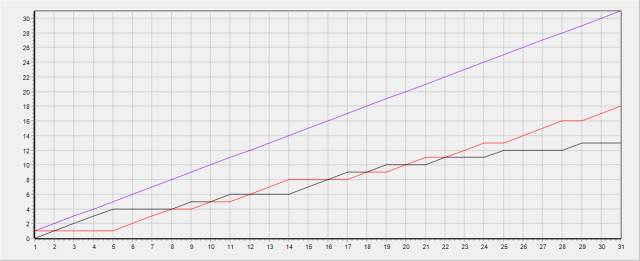
所以,延续上例的思路,我们这里应当调整根结点定位规则,想办法去找到每一个断签点,从这些点开始往前捯
此时,跨行引用有了用武之地
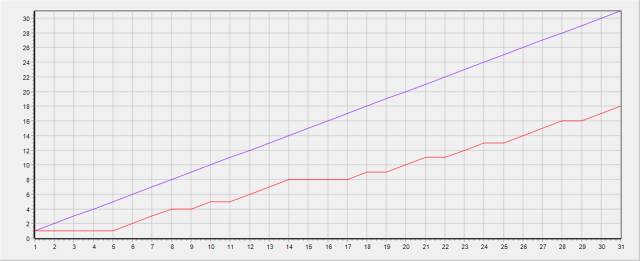
在每一个用户的分区内,按日期排序后,排在某行前一位的日期不与本行日期连续,则为断签点
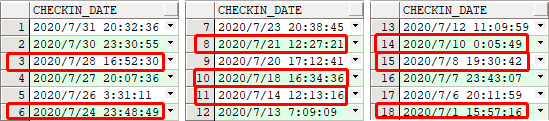
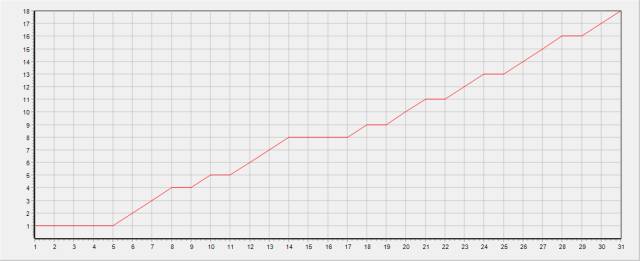
例如我们观察一下用户 2 的签到日期,断签点已被圈出
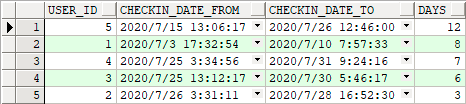
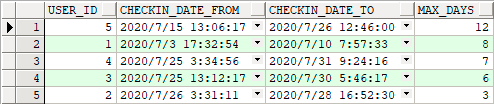
WITH checkin_his AS(SELECT t.user_id,t.checkin_date,lag(t.checkin_date) over(PARTITION BY t.user_id ORDER BY t.checkin_date DESC) next_checkin_dateFROM demo_checkin_history t),conn_rst AS(SELECT h.user_id,h.checkin_date checkin_date_from,connect_by_root h.checkin_date checkin_date_to,LEVEL days,MAX(LEVEL) over(PARTITION BY h.user_id) max_days,MAX(h.checkin_date) keep(dense_rank FIRST ORDER BY LEVEL DESC) over(PARTITION BY h.user_id) last_checkin_date_fromFROM checkin_his hWHERE connect_by_isleaf = 1START WITH h.next_checkin_date IS NULLOR trunc(h.next_checkin_date) - trunc(h.checkin_date) > 1CONNECT BY PRIOR h.user_id = h.user_idAND PRIOR trunc(h.checkin_date) = trunc(h.checkin_date) + 1)SELECT c.user_id, c.checkin_date_from, c.checkin_date_to, c.daysFROM conn_rst cWHERE c.days = c.max_daysAND c.checkin_date_from = c.last_checkin_date_fromORDER BY days DESC, checkin_date_from DESC;

COUNT(1) OVER(PARTITION BY user_id ORDER BY checkin_date)
因为聚合函数在分析模式下默认的窗口正好是第一行到当前行,所以无需考虑窗口问题
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY checkin_date)
第二步,实现构造函数 f1,由于其表达式为 f1(x)=x,换成人话就是日期
EXTRACT(DAY FROM checkin_date)
第三步,得到初代版本
WITH history AS(SELECT h.user_id,h.checkin_date,extract(DAY FROM h.checkin_date) f1,row_number() over(PARTITION BY h.user_id ORDER BY h.checkin_date) f2FROM demo_checkin_history h),group_rst AS(SELECT h.user_id,MIN(h.checkin_date) checkin_date_from,MAX(h.checkin_date) checkin_date_to,COUNT(1) daysFROM history hGROUP BY h.user_id, h.f1 - h.f2)SELECT g.user_id,MAX(g.checkin_date_from) keep(dense_rank FIRST ORDER BY days DESC) checkin_date_from,MAX(g.checkin_date_to) keep(dense_rank FIRST ORDER BY days DESC) checkin_date_to,MAX(g.days) max_daysFROM group_rst gGROUP BY g.user_idORDER BY max_days DESC, checkin_date_from DESC;
第四步,上例是基于仅统计一个月份内的前提,如果时间范围放大就会出问题,所以需要把构造函数 f1 再还原到签到日期本身
WITH history AS(SELECT h.user_id,h.checkin_date,row_number() over(PARTITION BY h.user_id ORDER BY h.checkin_date) deltaFROM demo_checkin_history h),group_rst AS(SELECT h.user_id,MIN(h.checkin_date) checkin_date_from,MAX(h.checkin_date) checkin_date_to,COUNT(1) daysFROM history hGROUP BY h.user_id, trunc(h.checkin_date) - h.delta)SELECT g.user_id,MAX(g.checkin_date_from) keep(dense_rank FIRST ORDER BY days DESC) checkin_date_from,MAX(g.checkin_date_to) keep(dense_rank FIRST ORDER BY days DESC) checkin_date_to,MAX(g.days) max_daysFROM group_rst gGROUP BY g.user_idORDER BY max_days DESC, checkin_date_from DESC;



文章转载自SQL干货分享,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
