





一、方法
图数据库采用属性图模型。图数据是由节点(也称为顶点)组成的数据以及它们之间的连接,称为边缘。边有标签,每个节点或边都有一组属性或属性,即一组名称-值对。

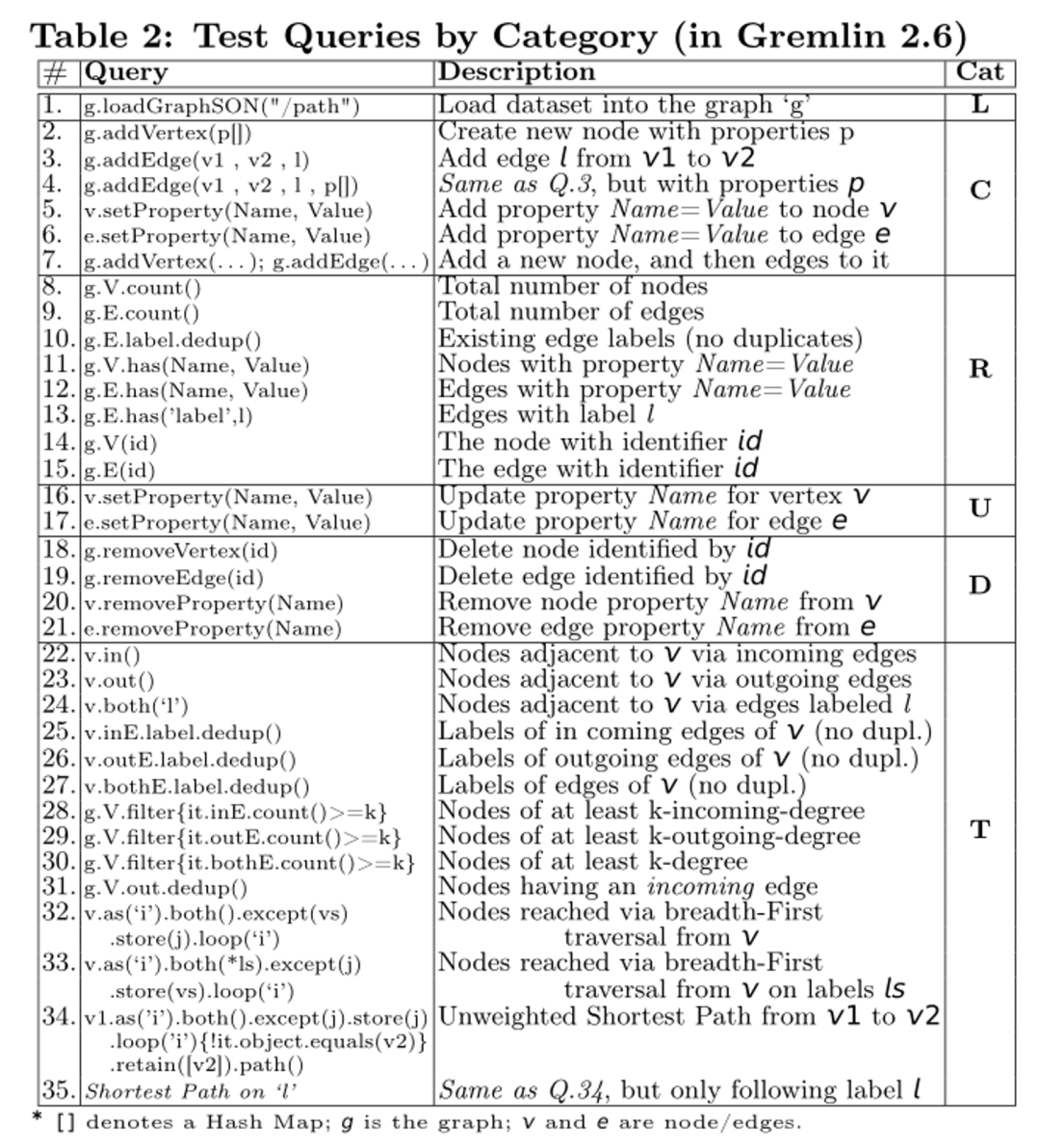
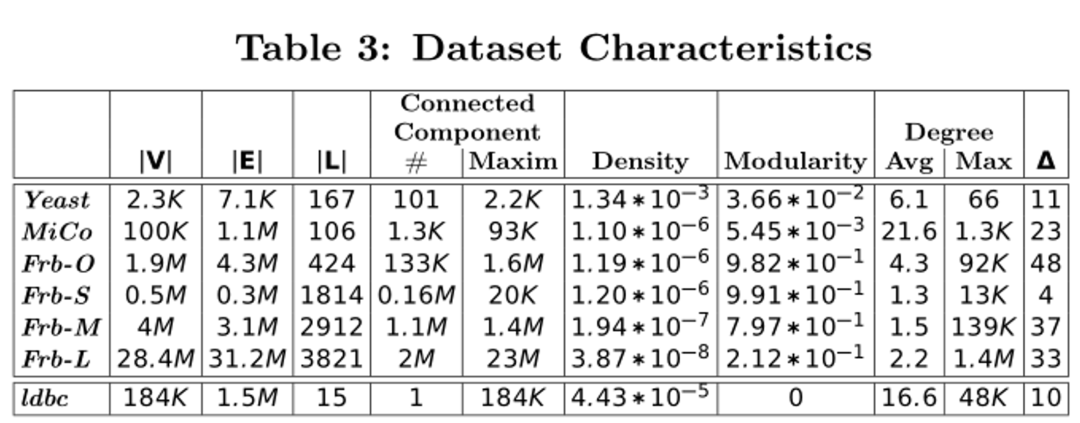
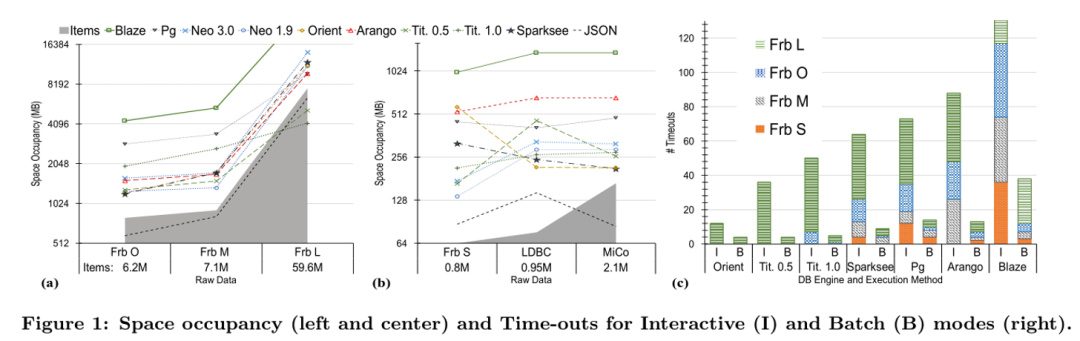
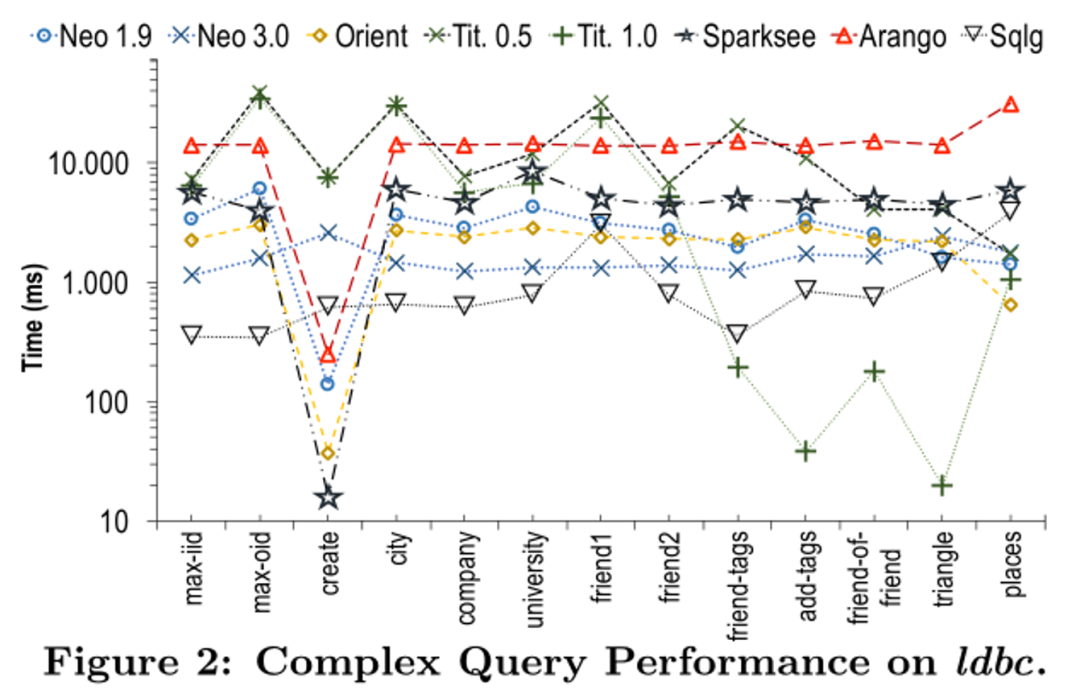
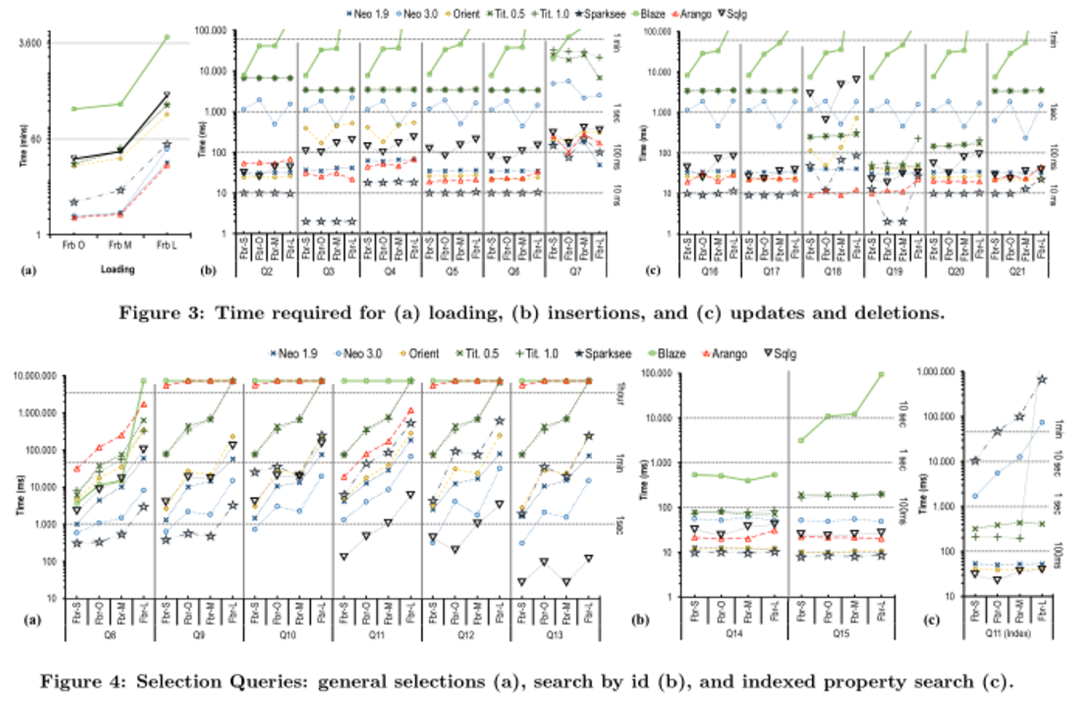
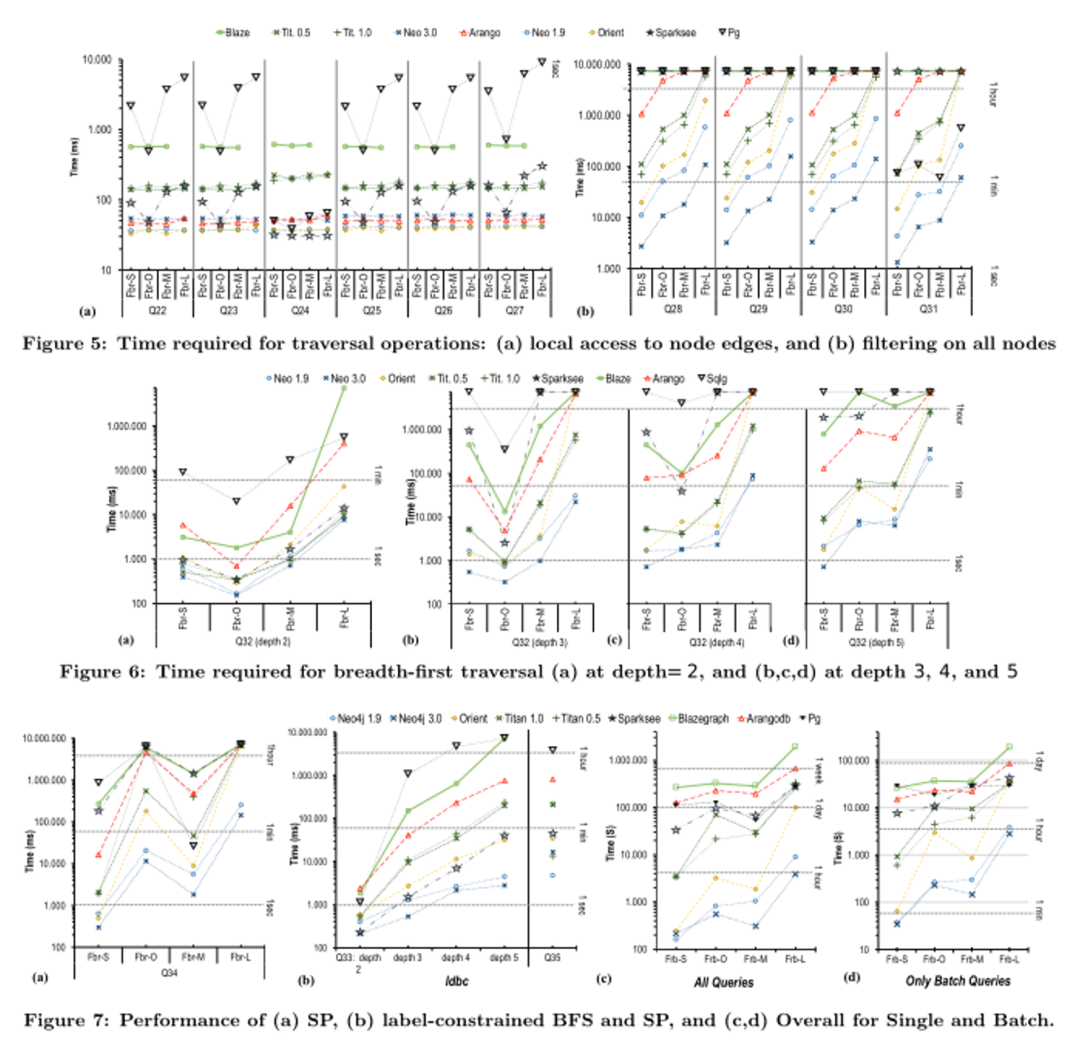
 表示系统达到或接近最佳性能。警告符号
表示系统达到或接近最佳性能。警告符号 表示系统性能接近低端或指示执行问题。通过该表,从业者可以为特定的工作负载或场景确定最佳系统。例如,我们可以看到本地图数据库Neo4J、OrientDB和部分Sparksee是图遍历操作符(T)的更好候选。
表示系统性能接近低端或指示执行问题。通过该表,从业者可以为特定的工作负载或场景确定最佳系统。例如,我们可以看到本地图数据库Neo4J、OrientDB和部分Sparksee是图遍历操作符(T)的更好候选。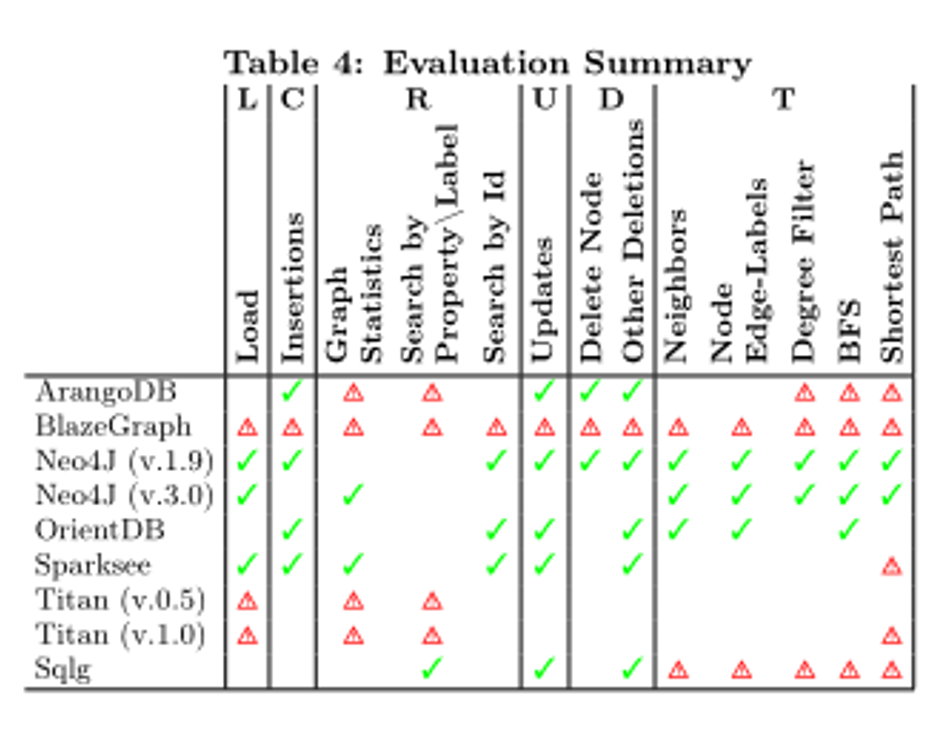


文章转载自图谱学苑,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
