






巨杉数据库受邀参加第三届“2022 长沙·中国 1024 程序员节”,围绕巨杉数据库最新基于「湖仓一体」架构的SequoiaDB v5.2,深度解析了全量数据价值从「内部离线」向「实时对客」进一步释放的思考与实施方式,及对「释放全量数据价值」的进一步诠释。


从「交易核心」到「数据核心」
作为有着35年数据库内核研发经验的数据库老兵,程祺是国内最早一批集中式和分布式数据库研究项目的核心成员,早在1986年就参与东南大学NITDB集中式数据库和SUNDDB分布式数据库的研究,拥有8项国际专利,在VLDB、ACM SIGMOD等会议及杂志发表多篇学术论文,曾任 IBM DB2 高级技术专家,拥有25年DB2内核研发经验,主要负责SQL编译器、查询优化器等核心模块。
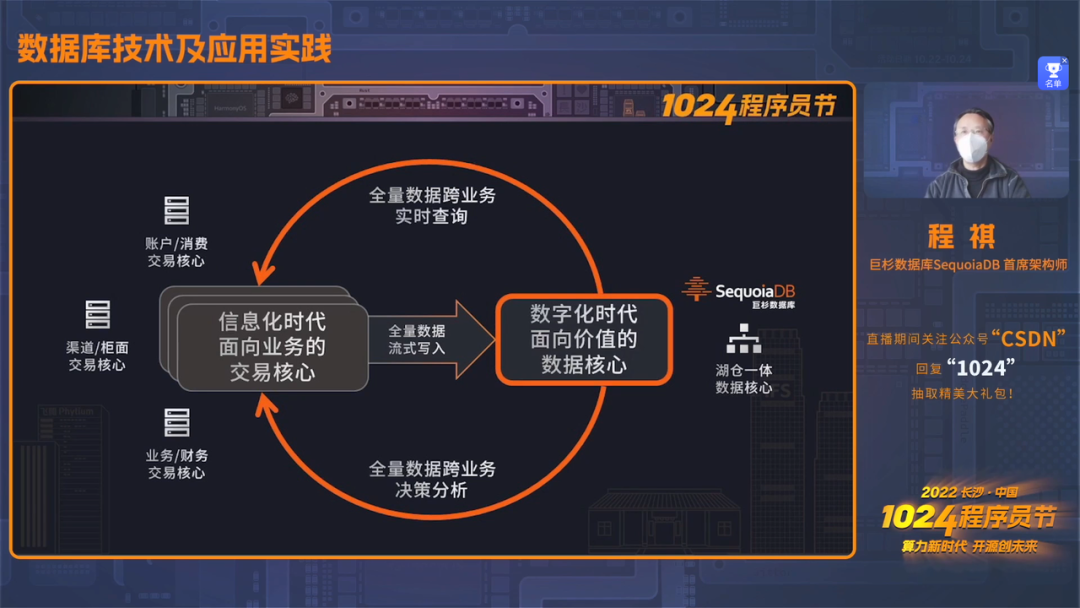
在数据类型方面:「交易核心」数据库往往只要处理单一的,结构化的交易结果数据,例如:余额、交易账单等信息; 而在「数据核心」中,我们需要保存的则是在每次余额变化、交易账单生成的背后,所伴随的大量结构化、半结构化流水记录等。整体来看,数据类型呈现更加多样化。 在时效性方面:「交易核心」数据库,更注重的是单个账务、交易系统中低延迟的在线事务并发性能; 而在「数据核心」中,我们更注重的是在复杂的、跨业务的场景中,对灵活可变的数据类型进行处理,并为前后端业务提供高并发的全量数据实时查询能力。 在业务范围方面:「交易核心」数据库,往往仅为某个业务系统单独建设; 而面向全量数据价值的「数据核心」系统,由于存放了企业的全量数据,将成为数十甚至数百个业务的数据基础设施,而不再是烟囱式的独立建设。
「双核时代」应协同创新而非替代
巨杉数据库始终认为,面向全量数据价值的「数据核心」并不是为了与传统「交易核心」数据库形成替换的竞争。
而是通过基于原生分布式数据库的「湖仓一体」技术架构,解决传统交易核心数据库所无法管理的海量数据及多模数据处理的综合需求,从而与传统「交易核心」数据库形成有效协同。
众所周知,金融银行业对于数据库的要求是十分严格的。在过去的10年间,客户接入到巨杉数据库的各类生产业务系统超过100个之多。巨杉数据库在过往已获得的行业大型企业规模化应用中,不少客户的部署规模达到200台,甚至400台物理服务器,数据容量达PB级别,数据记录数更突破万亿。
这充分说明,巨杉数据库并不是替代原有生产系统的「交易核心」数据库,而是通过成为客户的数据底座,为交易系统提供全企业跨业务视角的多模、实时全量数据,逐步成为客户全新的「数据核心」。
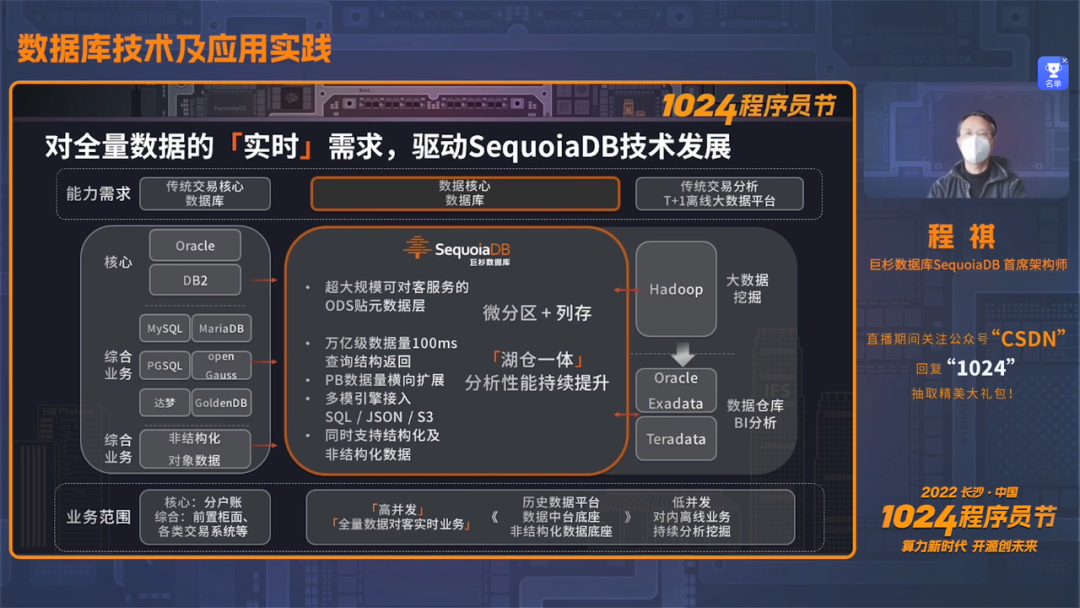
「湖仓一体」释放全量数据价值
中国众多的人口及领先的移动互联网业务发展,也让中国成为数字化创新最快的国家,金融银行业的科技发展更是催生出领先于全球的行业需求。与此同时,在数字化经济的发展下,全量数据的实时对客查询及分析能力,是提升客户满意度的关键因素。
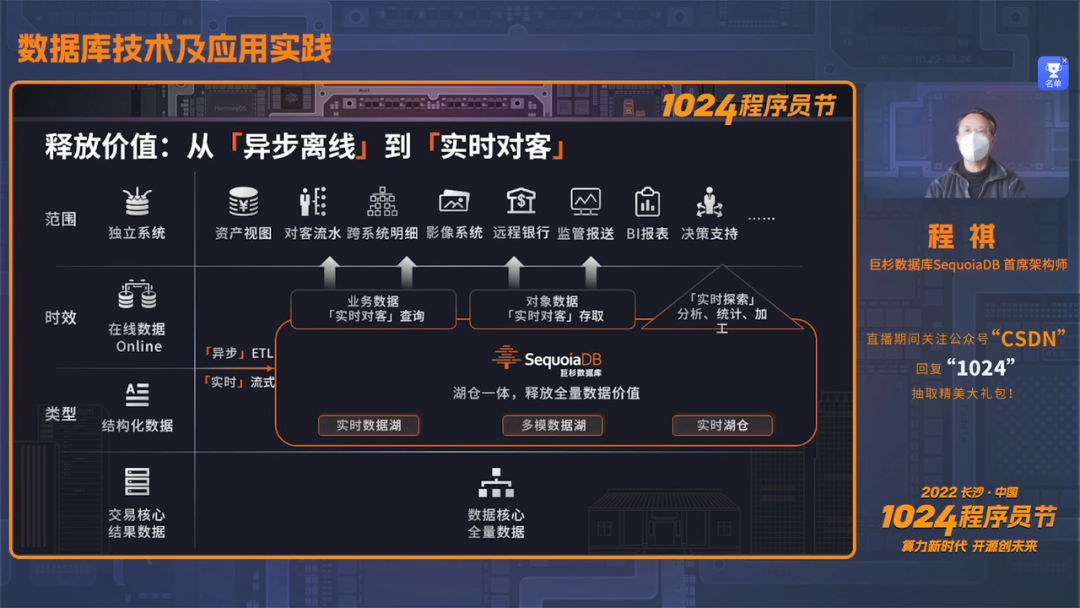
首先,面向结构化数据,巨杉提供深度的Join优化及列存微分区技术,在多个查询场景下,性能达到了ms级实时返回;分析场景中,性能更获得了10倍以上性能提升,让查询分析更实时。 其次,面向非结构化数据,巨杉通过「分片并发」及「可变分片大小」技术,相比原有版本吞吐量显著提升30%,让非结构化数据存取更实时。 再次,巨杉数据库的“实时数据湖”能够提供高并发全量数据查询能力,为实现各类综合业务运行更实时,帮助提升用户的满意度。
 相关阅读
相关阅读

