




01
从 Docker 镜像安装使用 Kylin
Jdk 1.8
Hadoop 2.7.0
Hive 1.2.1
Hbase 1.1.2
Spark 2.3.1
Zookeeper 3.4.6
Kafka 1.1.1
Mysql
Maven 3.6.1
首先执行以下命令从 Docker 仓库 pull 镜像:
docker pull apachekylin/apache-kylin-standalone:3.0.1
docker run -d \-m 8G \-p 7070:7070 \-p 8088:8088 \-p 50070:50070 \-p 8032:8032 \-p 8042:8042 \-p 16010:16010 \apachekylin/apache-kylin-standalone:3.0.1
Kylin 页面:http://127.0.0.1:7070/kylin/
Hdfs NameNode 页面:http://127.0.0.1:50070
Yarn ResourceManager 页面:http://127.0.0.1:8088
HBase 页面:http://127.0.0.1:60010
NameNode, DataNode
ResourceManager, NodeManager
HBase
Kafka
Kylin
JAVA_HOME=/home/admin/jdk1.8.0_141
HADOOP_HOME=/home/admin/hadoop-2.7.0
KAFKA_HOME=/home/admin/kafka_2.11-1.1.1
SPARK_HOME=/home/admin/spark-2.3.1-bin-hadoop2.6
HBASE_HOME=/home/admin/hbase-1.1.2
HIVE_HOME=/home/admin/apache-hive-1.2.1-bin
KYLIN_HOME=/home/admin/apache-kylin-3.0.0-alpha2-bin-hbase1x
02
基于 Hadoop 环境安装使用 Kylin
Kylin 可以在 Hadoop 集群的任意节点上启动。方便起见,你可以在 master 节点上运行 Kylin。但为了更好的稳定性,我们建议你将 Kylin 部署在一个干净的 Hadoop client 节点上,该节点上 Hive,HBase,HDFS 等命令行已安装好且 client 配置(如 core-site.xml,hive-site.xml,hbase-site.xml及其他)也已经合理的配置且其可以自动和其它节点同步。
当你的环境满足上述前置条件时 ,你可以开始安装使用 Kylin。
Step 1. 下载 Kylin 压缩包
从 https://kylin.apache.org/download/ 下载一个适用于你的 Hadoop 版本的二进制文件。目前最新版本是 Kylin 3.0.1和 Kylin 2.6.5,其中 3.0 版本支持实时摄入数据进行预计算的功能。如果你的 Hadoop 环境是 CDH 5.7,可以使用如下命令行下载 Kylin 3.0.0:
cd usr/local/wget http://apache.website-solution.net/kylin/apache-kylin-3.0.0/apache-kylin-3.0.0-bin-cdh57.tar.gz
tar -zxvf apache-kylin-3.0.0-bin-cdh57.tar.gzcd apache-kylin-3.0.0-bin-cdh57export KYLIN_HOME=`pwd`
export SPARK_HOME=/path/to/spark
$KYLIN_HOME/bin/download-spark.sh
A new Kylin instance is started by root. To stop it, run 'kylin.sh stop'Check the log at usr/local/apache-kylin-3.0.0-bin-cdh57/logs/kylin.logWeb UI is at http://<hostname>:7070/kylin
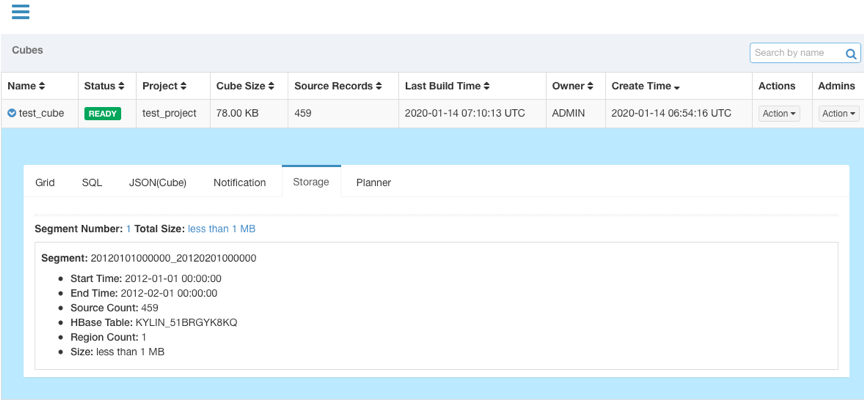
$KYLIN_HOME/bin/sample.sh

5000 字带你快速入门 Apache Kylin
Kylin 初入门系列课程
Kylin 新定位:分析型数据仓库
Apache Kylin 云原生架构的思考及规划
使用 DolphinScheduler 调度 Kylin 构建

