




作者:StarRocks PMC Chair 赵纯(本文为作者在 StarRocks Summit Asia 2022 上的分享)
为了能够给用户提供更快、更灵活、更实时的分析体验,StarRocks 过去一年在产品的功能、性能、稳定性上不断打磨。一年里,StarRocks 一共修改了 80 多万行代码,发布了近 50 个版本。其中我们支持了物化视图 2.0、资源隔离、极速数据湖分析等重要功能。
去年这个时候 StarRocks 发布了 Primary Key,进入了极速统一 2.0 时代,用户能够利用 StarRocks 同时进行实时数据和历史数据的分析。今年我们正式发布 StarRocks 数据湖分析,让用户能够在 StarRocks 上同时进行极速 OLAP 分析与极速数据湖分析,我们将它定义成极速统一 3.0。
#01
极速 OLAP
物化视图包含了两个维度的内容,一个维度是物化,一个维度是视图。物化这个维度指的是物化视图要将数据进行物理化存储,这样后续应用就能够直接使用,起到查询加速的效果。视图是逻辑层次的概念,表达的是一个查询的结果集,视图可以直接被用来指定进行查询。用户使用视图更多的是想做一个逻辑的抽象,用来简化 SQL。
所以物化视图是两者的融合,一方面能够通过物理层的存储来加速查询,另一方面提供了逻辑层的抽象,用来简化用户的 SQL 表达。之前的 StarRocks 也支持物化视图,1.0 版本的物化视图存在着以下几个方面的缺陷:
4. 物化视图 1.0 只支持同步更新,在基础表导入时,物化视图同步进行导入。只有当物化视图和基础表都导入成功后,用户的数据才可见。这样有一个弊端,当物化视图数目增多时,导入的时效性就会受到一定的影响。所以,物化视图 1.0 版本更多像是一个索引,而缺少视图这方面的能力。
经过过去一年的设计与研发,StarRocks 发布了物化视图 2.0。物化视图 2.0 是一套全新的物化视图架构,与物化视图 1.0 版本完全不同。相比于物化视图 1.0,物化视图 2.0 具备以下能力:
4. 物化视图 2.0 支持异步刷新的机制,所以创建物化视图本身并不会影响数据的导入时效性。StarRocks 内部会根据基础表的变更,智能地判断出哪些物化视图的分区需要更新。StarRocks 会异步地完成物化视图的刷新。
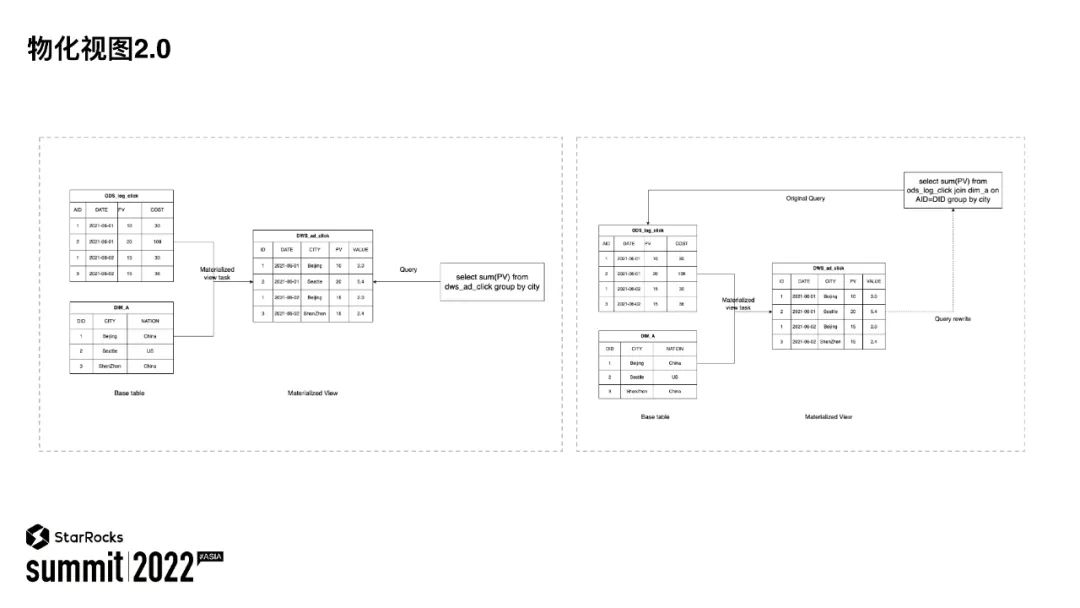
上图展示的是用户在分析时如何使用物化视图。
图左展示的是,用户可以直接指定物化视图进行分析。用户在创建物化视图的时候使用较复杂的逻辑用于逻辑抽象,其他的用户可以直接针对抽象之后的视图进行查询分析。相比于视图,通过做物化视图能够获得更快的查询性能体验。
图右展示的是 StarRocks 能够将用户对原表的查询自动改写为对物化视图的查询。这里的物化视图起到的是一个透明加速的能力。
StarRocks 讲的是极速统一。当用户用 StarRocks 来服务越来越多的业务时,就会面临一个问题:采用什么样的方式来支持不同的业务部署?是业务独立部署还是业务混合部署?
独立部署为每一个业务独立部署一个物理集群,这样的好处显而易见,就是业务之间相互不影响。但这样部署也会有以下缺陷:
3. 由于物理的隔离,数据共享会变得复杂,用户想要数据共享,往往只能将数据拷贝多份。
混合部署,将所有的业务放到一个共享的集群中。在一个大集群中,运维的成本会降低,资源的利用率会升高,数据共享也会变得简单。但是最让用户头疼的一个问题就是在同样的一个集群中,业务之间会相互影响。比如某个业务不小心发了一个查询,将整个集群的资源全部吃光,那么在这个集群上,其他的业务都会被影响。
所以有没有第三种选择呢?尤其是在当前降本增效的大环境下,既能更高效地利用资源,又能够保证业务之间互不影响。
StarRocks 提供了这样的选择:集群内的资源隔离。用户可以为每个业务指定不同的资源组,资源隔离的机制会保证每个业务的资源组不被其他业务所影响。接下来我就为大家简单介绍一下 StarRocks 的资源隔离运行机制以及当前达到的能力。
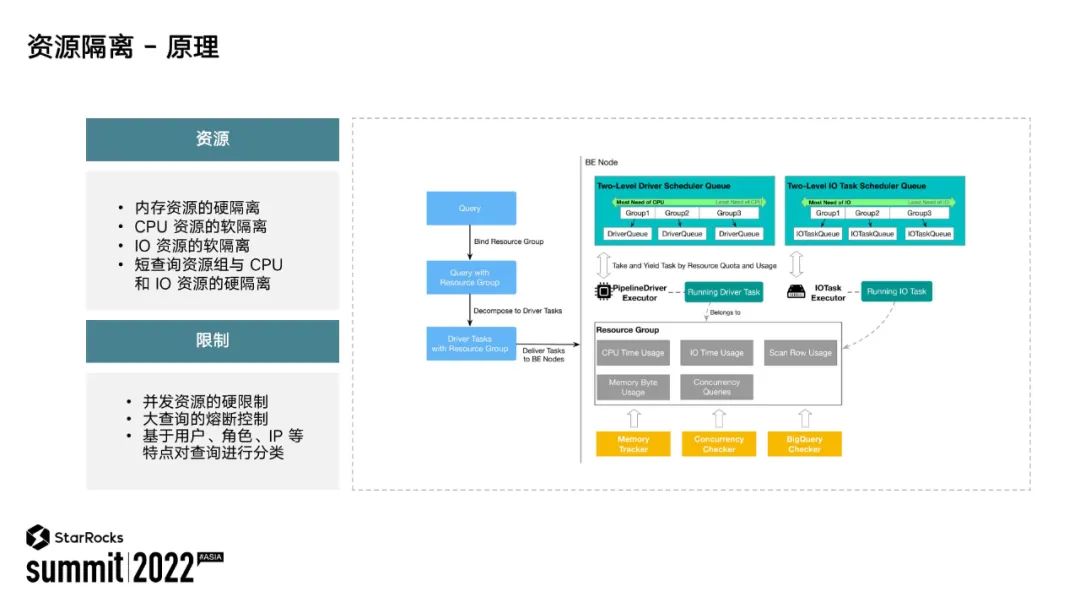
上图展示的是 StarRocks 资源隔离运行的机制。StarRocks 内部会给资源组划分固定的资源,包括 CPU内存、IO 等等。有些资源是软隔离,比如 CPU、IO,有些资源是硬隔离,所谓的硬隔离超过了就要失败,比如内存。除了资源分配以外,StarRocks 也支持为每个资源组设定一定的限制,对于超过限制的请求就会予以拒绝。比如每个资源组都会有最大的请求并发数,当请求的并发超过限制时,新的请求就会被资源组拒绝掉。
那么资源隔离是如何生效的呢?如上图所示,StarRocks 接收到一个用户请求后,会根据请求的属性将这个请求划分到对应的资源组里。然后 StarRocks 内部就会利用资源组所分配到的资源来执行这个请求,这样一个资源组的资源就能够得到保证,不会使用其他资源组的资源,也不会被其他资源组所抢占。通过这样的机制,StarRocks 就能够保证各个业务在同一个集群内,并且相互之间不影响。
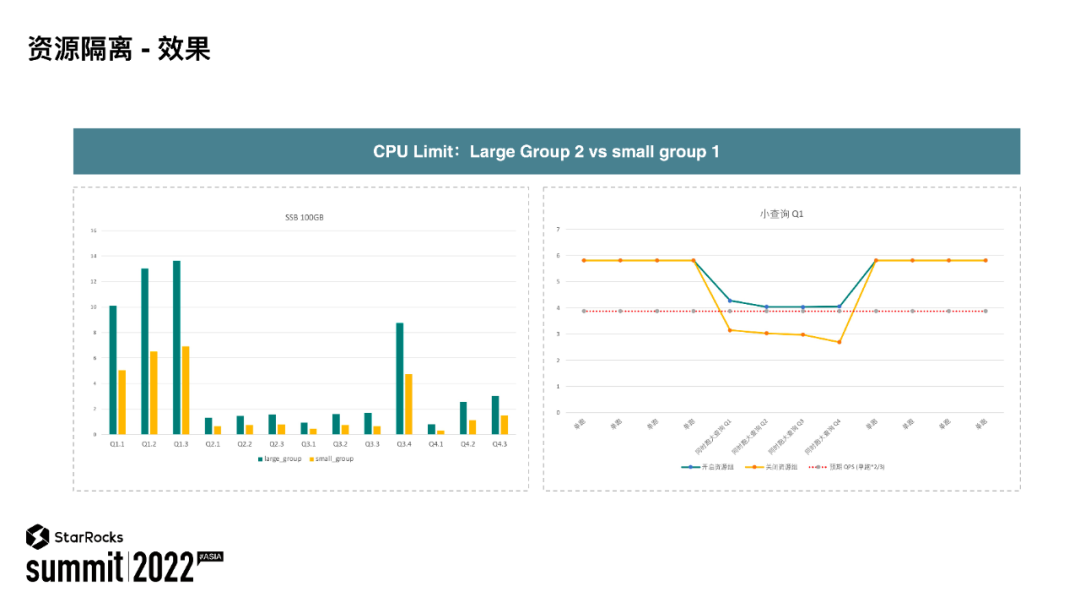
上图展示的是 StarRocks 当前资源隔离的一个运行效果。测试分两个资源组:大资源组和小资源组,大资源组获得的资源是小资源组的两倍。
图左可以看出,两个资源组运行同样的请求的情况下,大资源组运行更快,并且从执行效率上看是符合所获得资源比例的。图右展示的是当查询运行在大资源组时,开启资源隔离与关闭资源隔离时执行效率的对比图。可以看到,当开启资源隔离后,大资源组里面执行的效率与理论计算效率较相符。通过上面这两个 case 可以看出 StarRocks 当前资源隔离的效果,我也期待资源隔离能够给更多用户带来价值。
比如下面这个查询要计算过去 7 天每天的 UV 值,但其实只有最近一天的数据在变更,其他 6 天的数据并没有更新。实际上过去 6 天的数据查询结果是能够被复用的。如果能够复用之前的查询结果,那查询就会执行得更快。所以很自然想到,我们可以针对这样的查询场景设计中间结果 cache 加速查询。

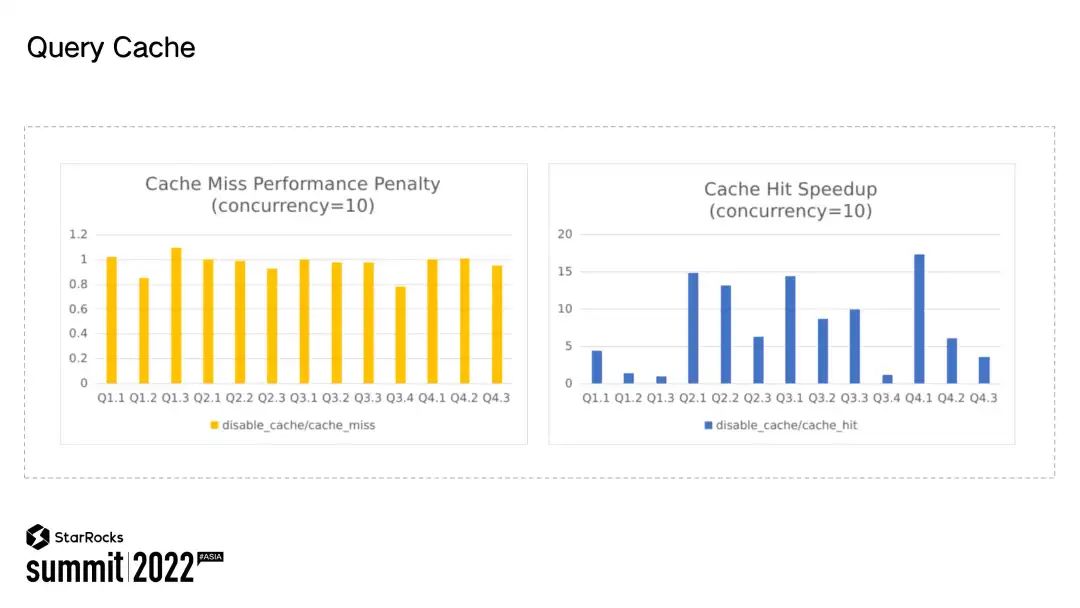
使用过 StarRocks 的同学都会面临一个问题,表的 bucket 到底要设置成多少?为什么设置合适的 bucket 会如此重要呢?如果 bucket 数目少了,StarRocks 的查询并行度与 bucket 数目绑定,过少的 bucket 数目会影响整个的查询性能。

所以用户就会问,那么我到底应该设置成多少呢?为了解决用户的这个困扰,让用户能够更简单地使用 StarRocks,我们做了以下两方面的工作:首先是解耦 tablet 与执行并行度之间的关系。我们通过支持 local shuffle 这样的能力,使得查询并行度与 tablet 数目之间无关。即使只有一个 tablet,上层仍然可以并行执行查询。之前 StarRocks 一个 tablet 上层只能有一个并行路来执行,但新版本的 StarRocks 可以不受 tablet 数目的限制。虽然只有一个 tablet,上层仍然可以并行的执行。
从我们的测试结果中也可以看出,如上图所示,创建一个 tablet 与创建多个 tablet 性能可以一致。这样用户在创建表的时候就不需要为查询性能而考虑应该设置多少个 buckets。除此之外,StarRocks 也支持了按照历史数据大小自适应的选择 bucket 的数目。这样通过上述两项工作,用户在创建表时就不需要花过多的精力来思考到底应该将 buckets number 设置成多少了。
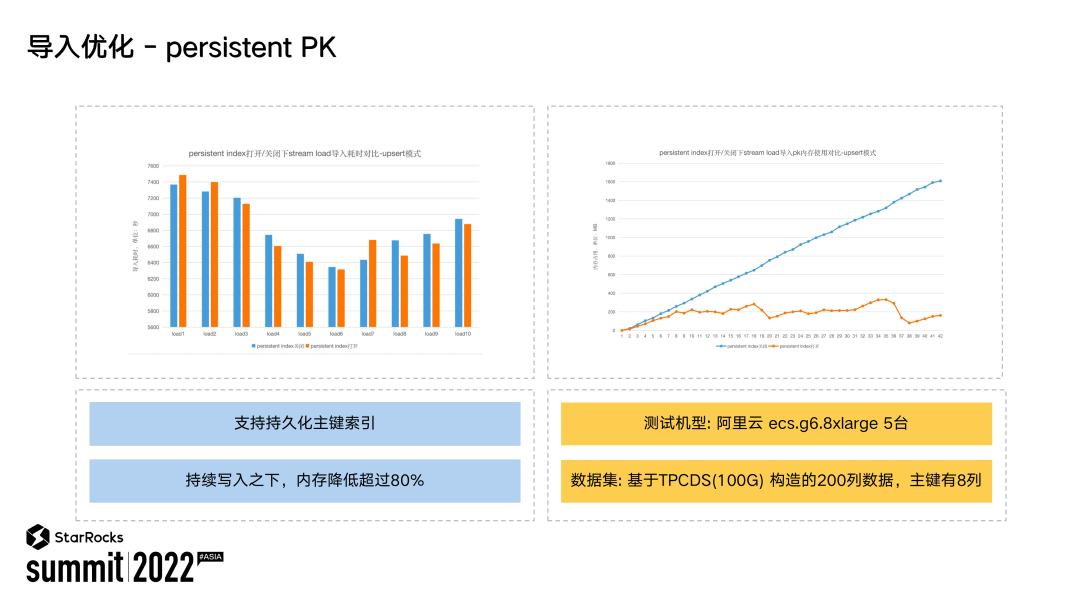
从上图中也可以看到,在开启了 persistent PK 时,导入性能基本上没有什么影响,但系统占用的内存比例下降了 80%。
除了在 Primary Key 模型的优化之外,我们还做了很多导入优化。将导入全流程接入了我们 Pipeline 引擎,提供了 2PC 导入事务语义,支持了 Replicate Storage,能够极大提升多副本导入的速率,优化了 Apache Kafka 导入的调度策略。当前最大规模已经支持了 1000 亿/天的导入速度,实现了全面向量化解析 JSON/Parquet,提升两者的导入速度。
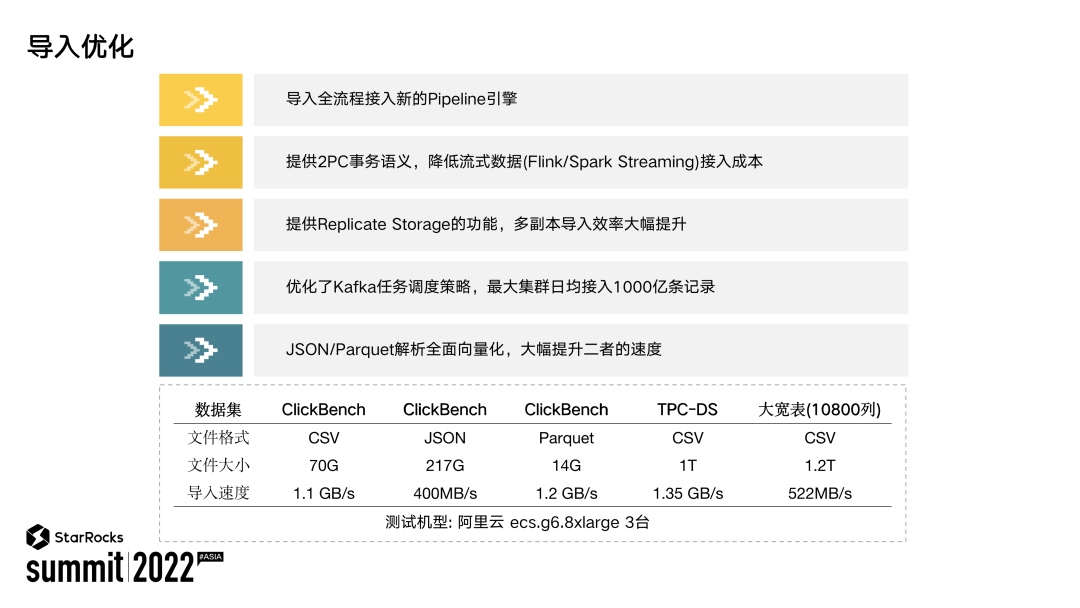
上表展示的是当前 StarRocks 的导入性能。可以看到在 342 核、3 台节点的集群规模下,我们导入 3 副本的数据:CSV、Parquet 能够达到 1GB/s 甚至更高的导入性能,JSON 可以达到 400MB/s 的导入性能,即使对于 1 万列的数据也可以达到 500MB/s 的导入性能。
由于篇幅的限制,不能在这里为大家介绍我们的所有优化。过去一年,我们做的优化还包括:CTE 复用、Global Runtime Filter 等等的优化。关于极速统一这件事情,StarRocks 从未停止前进的步伐,相信未来会给大家带来更加极速、更加统一的分析体验。
#02
极速数据湖分析
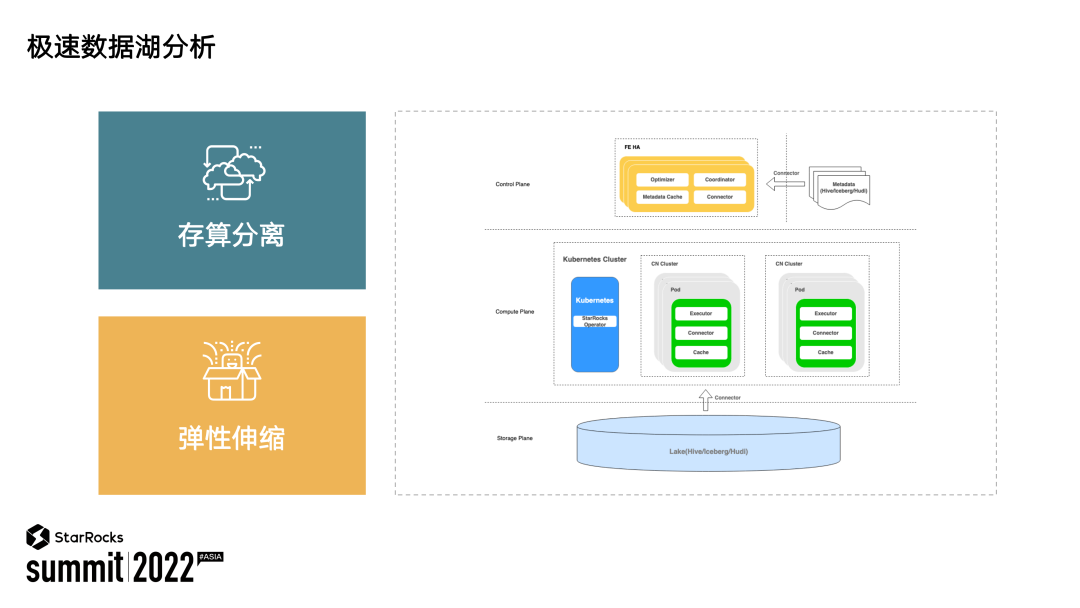
上图展示的是 StarRocks 数据湖分析的整体架构。可以看到,在 Storage 层,数据都存储在 Apache Hive/Apache lceberg/Apache Hudi 这样的数据湖中。在计算层,StarRocks 的无状态节点 Compute Node 会组成多个物理集群,执行用户具体的查询请求。当前 StarRocks 已经可以对接 K8S。物理集群能够自动根据负载情况完成自动伸缩。在控制层,StarRocks FE 完成了数据湖元数据的对接,并接入用户所有的查询请求。在整个架构层面可以看到,当前 StarRocks 的数据湖分析已经具备了存算分离、弹性伸缩的能力。
提到数据湖分析,用户总是觉得数据湖分析的性能会不如 OLAP 快。我们把 StarRocks 数据湖分析叫做极速数据湖分析。那到底有多极速呢?我们认为为用户提供跟仓一样性能的数据湖分析,就是极速数据湖分析。
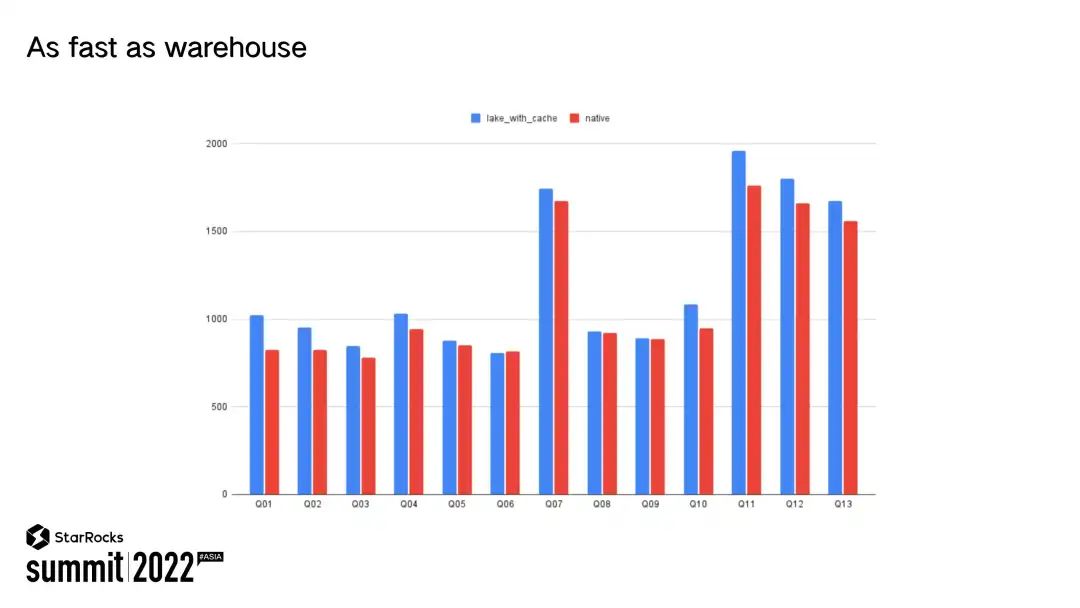
StarRocks 在数据湖的工作主要分为以下几个维度:第一,更容易的数据接入;第二,更快的分析性能;第三,更好的弹性;第四,更灵活的数据分析方式。数据湖分析数据都已经存在了各个数据湖中,那么我们需要一个简易的方式,能够将数据湖中的数据接入到 StarRocks中。StarRocks 现在提供了Web Catalog 的能力,用户只需要通过一条 SQL 命令就能够将外部数据湖整个湖的数据挂接到 StarRocks 中来,然后用户就可以在 StarRocks 中分析湖上所有的数据。
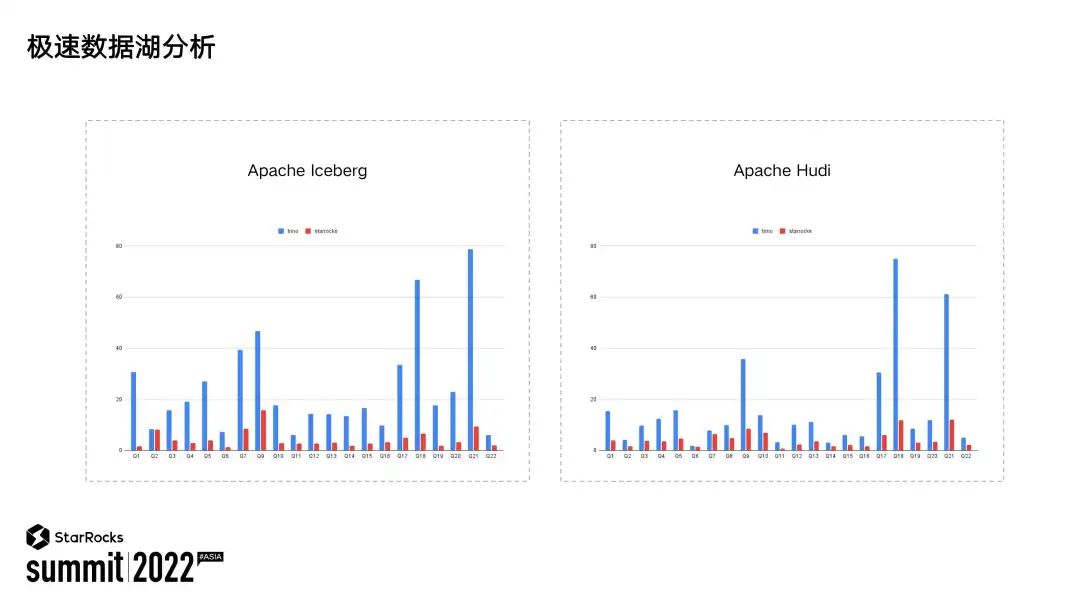
1. 数据湖 IO 延迟比较高。数据湖上的数据通常存储在对象存储或者 HDFS 中,其单次的 IO 请求延迟一般会在 20-30ms 之间,相比于本地 SSD 不到 1ms 的查询延迟要高出几十倍。另外不像本地系统一样,数据湖的 IO 访问一般通过 RPC 的方式,很难利用到 OS 的 page cache。
2. 数据湖上的数据来源比较多,缺少对数据产生者的约束。所以有时数据湖上的数据并不是对数据分析十分有利,比如在有些场景下会有大量的小文件存在。
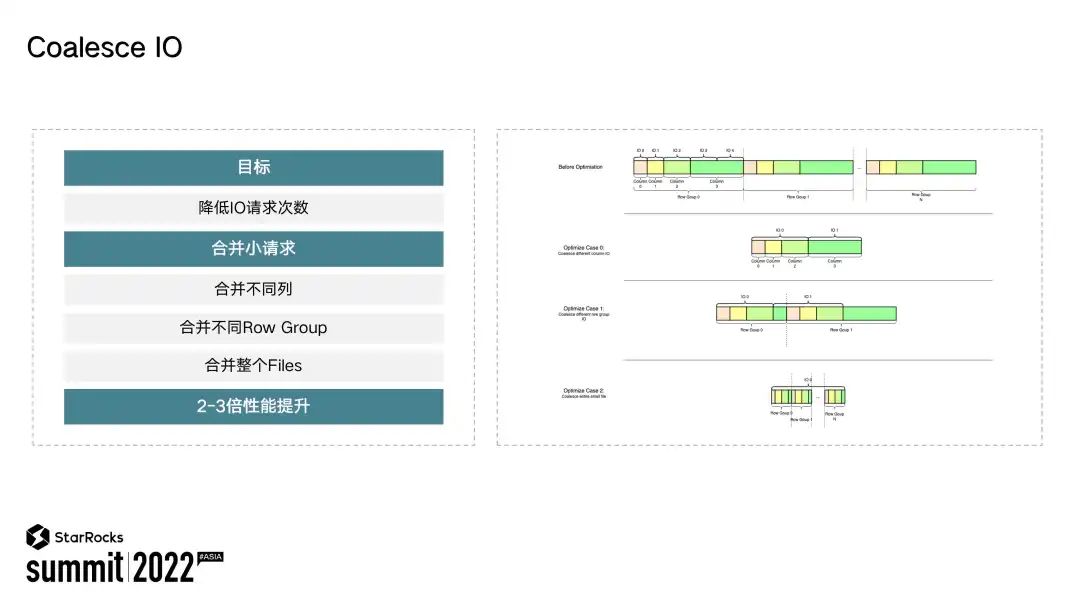
针对湖上单次 IO 请求延时比较高的情况,为了能够让分析执行地更迅速,StarRocks 支持了 Coalesce IO用于合并小的 IO 请求,通过减少 IO 次数,增加每次 IO 的请求量,这样就能够提升整个查询时延。
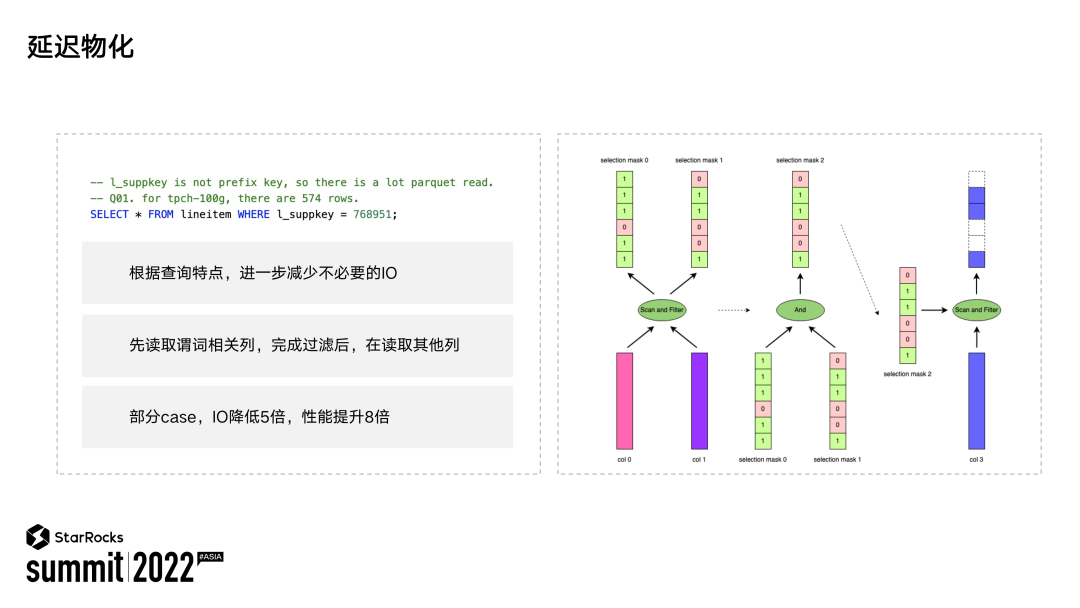
Coalesce IO 是根据文件的物理属性进行 IO 优化,那么延迟物化是根据查询请求的特征来进行优化,其目的仍然是减少 IO 的请求次数。像上图中第三行,这样一条 SQL 指令会扫描表中所有的列,但是有一个选择度超低的过滤条件,在正常的执行逻辑过程中会将所有的列先扫描出来,然后完成谓词过滤。这样基本上是一个全标扫描的操作,会有大量的 IO 请求。
数据湖上存储了大量没有处理过的数据,存在大量半结构化的数据,比如会有似 Struct、Map 等类型。为了能够让用户分析所有的数据,StarRocks 原生地支持了常见的半结构化数据类型,包括 JSON、Array、Struct、Map。用户可以使用 StarRocks 对这些类型的数据进行极速分析,并且 StarRocks 实现了Java UDF 框架支持用户自定义 UDF、UDAF、UDWF、UDTF。这样用户可以很容易进行能力扩展。StarRocks 也支持了 λ 表达式,使得用户分析更加灵活。
#03
总结与展望
回看 StarRocks Summit Asia 2022
关于 StarRocks
StarRocks 创立两年多来,一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 170 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。


StarRocks 技术内幕:
👇 阅读原文回看 StarRocks Summit Asia 2022
