





昨天冤种带教老师叫我打的电话还没打完
非常烫嘴的广普
我跟旁边的小哥说
我帮他做表
他帮我打电话

社会主义接班人如我
还是帮他做了表
今天记录一下昨天做表的用到的函数
(祈祷一下冤种带教老师不要再叫我打电话😭)
🙋利用百分位数筛选每组前20%的数据
🙋按照公司内码分组,然后挑选每组中金额最大的前20%数据,最后将所有数据合并输出。
import pandas as pdimport numpy as npdata = pd.read_excel("分位数计算.xlsx")grouped = data.groupby("公司内码")df_all = []for g,df in grouped:df = df[(df["其他流动资产"]> np.percentile(df["其他流动资产"],80))].copy() ##按照分位数筛选,>80,即代表选择金额最大的前20%的数据df["前20%其他流动资产的平均值"] = df["其他流动资产"].mean()df_all.append(df)data_all = pd.concat(df_all)data_all.to_excel("前20%其他流动资产的数据.xlsx",index=False)##要加copy(),要不然会报错SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame##百分位数的概念:np.percentile(a,80)的意思是该列数据中有80%的数小于或者等于这个数。np.percentile会对数值从小到大自动排序后再确定分位数##筛选前20%数据的另外方法# for g,df in grouped:# df = df.sort_values(["其他流动资产"], ascending=False)# df = df.head(int(len(df) (1/(30/100)))) ##前30%数据# df["前20%其他流动资产的平均值"] = df["其他流动资产"].mean()# df_all.append(df)
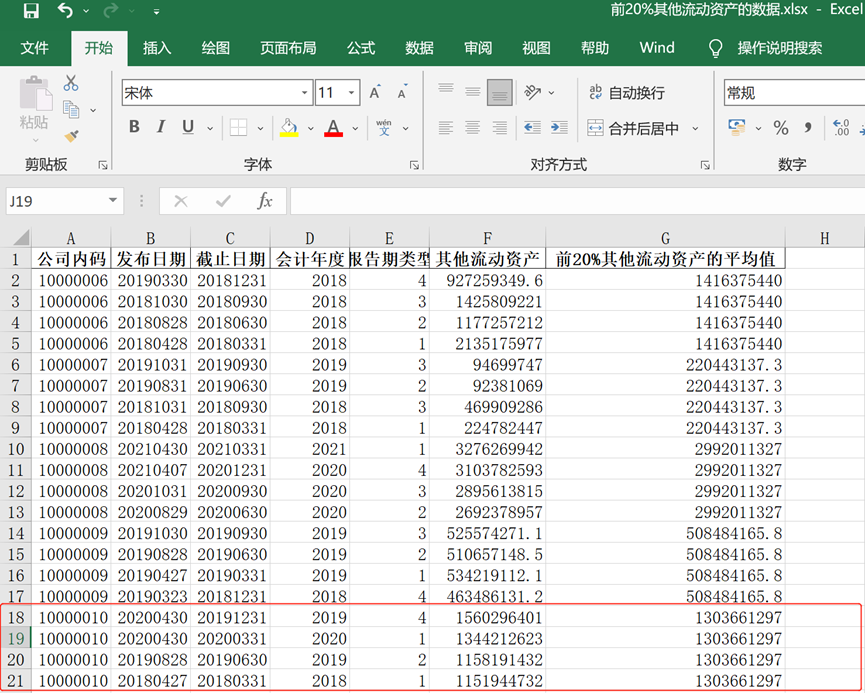
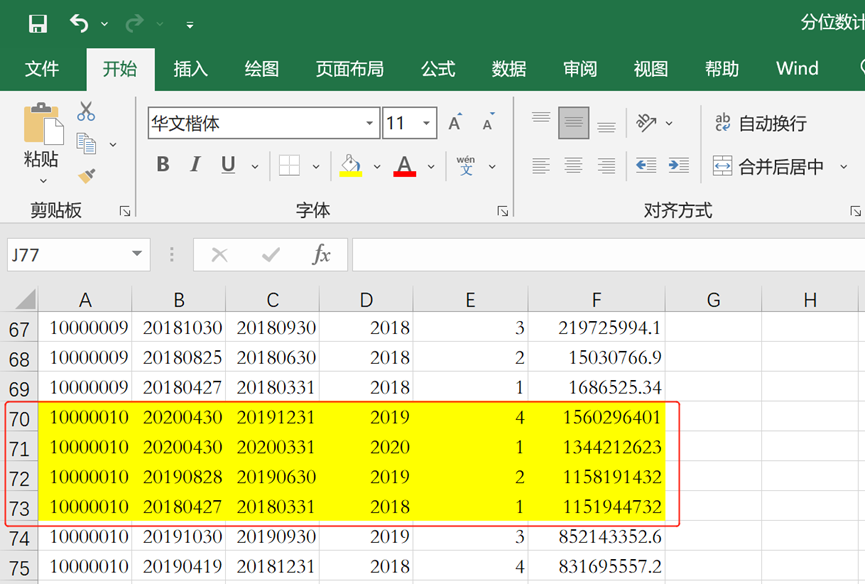
🙋检验输出结果,原表中公司代码10000010有17条数据,前20%的数据就有3.4条,向下取整应该是4条数据。将其他流动资产按照降序排序,前四条数据中的其他流动资产分别为1560296401、1344212623、1158191432、1151944732,输出结果与上述的4条数据一致。
🙋筛选每组金额最大的一行数据
🙋按照公司内码分组,然后挑选每组中金额最大的数据,最后将所有数据合并输出。
import pandas as pdimport numpy as npdata = pd.read_excel("分位数计算.xlsx")grouped = data.groupby("公司内码")df_all = [] #df_all是一个列表for g,df in grouped:df = df.iloc[df['其他流动资产'].idxmax()] ##找出其他流动资产中金额最大值所在行的索引,再根据索引选取行数据。df_all.append(df)data_all = pd.DataFrame(df_all) ##此处df是series,series合并构建一个dataframedata_all.to_excel("其他流动资产最大的数据.xlsx",index=False)#列表构建dataframe可以直接用pd.DataFrame
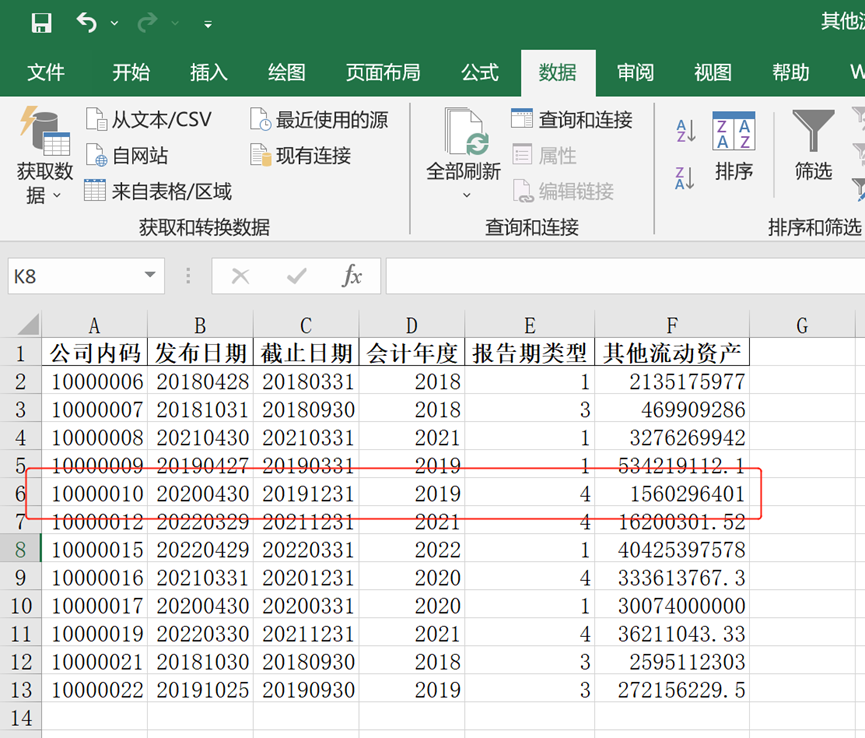
以上就是今天的内容!

文章转载自筑基期摸鱼大师,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
