





ProxySQL 作为一款强大的中间件为 MySQL 的架构提供了有力的支持。
目前可以很好的支持 Master Slave MGR PXC等,并提供连接池、读写分离、日志记录等功能,当然还有很多其他实用功能,这里不一一列举了。
本文都是基础概念,基本出自官方文档,官方已经解释的非常清晰,我就不太多加工,汇总一些实用的分享给大家。
安装
ProxySQL 安装非常简单。
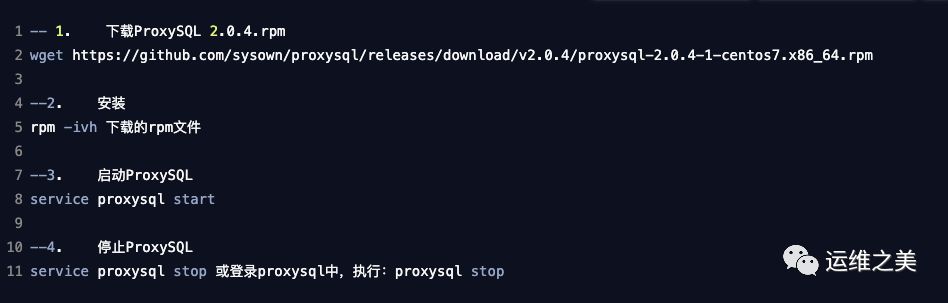
连接 ProxySQL
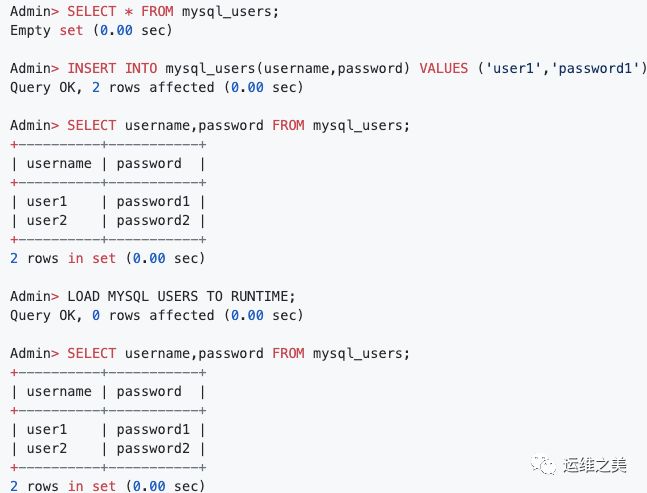
ProxySQL 默认管理端口 6032,默认需要 127.0.0.1 来进入,进入方式和连接MySQL 方式一致:
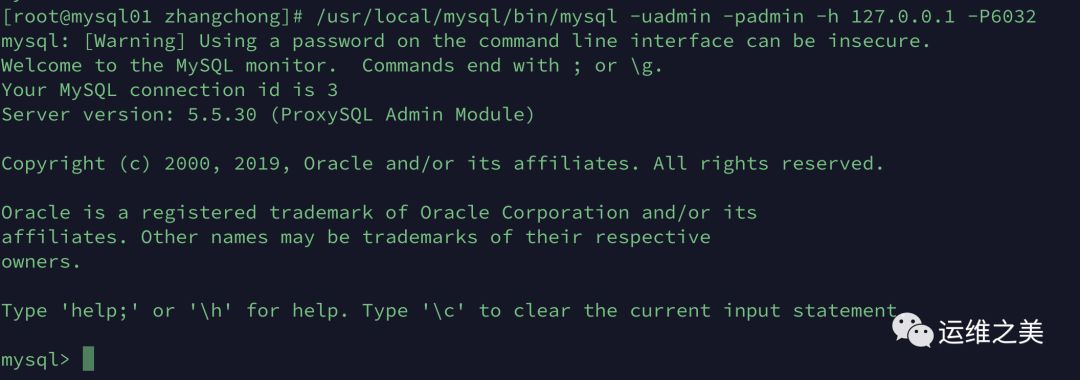
ProxySQL 运行机制
RUNTIME
RUNTIME 表示处理请求的线程使用的 ProxySQL 的内存数据结构。
Runtime Variables 包含了:
1. Global Variables 的实际值。
2. 将后端的服务器列表分组到 hostgroup 中。
3. 让 MySQL 的 User 们可以连接 ProxySQL。
注意:Runntime 层数据,谁都不能直接修改,必须通过下一层来提交修改。
MEMORY
MEMORY(有时也称为 Main)表示通过 MySQL 兼容接口公开的内存数据库。用户可以将 MySQL 客户端连接到此接口,并查询各种 ProxySQL 配置表/数据库。
通过此接口可用的配置表是:
mysql_servers - ProxySQL 连接到的后端服务器列表
mysql_users - 连接到 ProxySQL 的用户及其凭据列表。请注意,ProxySQL 也将使用相同的凭据连接到后端服务器!
mysql_query_rules - 将流量路由到各种后端服务器时评估的查询规则列表。这些规则还可以重写查询,甚至可以缓存已执行查询的结果。
global_variables - 代理配置使用的全局变量列表,可在运行时调整。
DISK 和 CONFIG FILE
DISK 表示磁盘上的 SQLite3 数据库,默认位置为 $(DATADIR)/proxysql.db。
在重新启动时,未保留的内存中配置将丢失。因此,将配置保留在 DISK 中非常重要。
启动过程
如果找到数据库文件(proxysql.db),ProxySQL 将从 proxysql.db 初始化其内存中配置。因此,磁盘被加载到 MEMORY 中,然后加载到 RUNTIME 中。
如果找不到数据库文件(proxysql.db)且存在配置文件(proxysql.cfg),则解析配置文件并将其内容加载到内存数据库中,然后将其保存在 proxysql.db 中并在加载到 RUNTIME。
请务必注意,如果找到 proxysql.db,则不会解析配置文件。也就是说,在正常启动期间,ProxySQL 仅从持久存储的磁盘数据库初始化其内存配置。
配置文件有 4 个变量,即使存在 proxysql.db,也始终会从配置文件里去解析:
1. datadir
定义了 ProxySQL datadir 的路径,其中存储了数据库文件,日志和其他文件。
2. restart_on_missing_heartbeats(1.4.4中的新增内容)
如果 MySQL 线程错过了 restart_on_missing_heartbeats 心跳,则 ProxySQL 将引发 SIGABRT 信号并重新启动。默认值为 10。
详情请见:https://github.com/sysown/proxysql/wiki/Watchdog。
3 .execute_on_exit_failure(1.4.4 中的新增内容)
如果设置,ProxySQL 父进程将在每次 ProxySQL 崩溃时执行定义的脚本。建议使用此设置生成警报或记录事件。
请注意,在崩溃的情况下,ProxySQL 能够在几毫秒内重新启动,因此其他监视工具可能无法检测到正常故障。
4. errorlog(2.0.0中的新增内容):
如果设置,ProxySQL 将使用定义的文件作为错误日志。如果未传递此类变量,则 errolog 将位于 datadir/proxysql.log 中
初始化启动过程(或 --initial)
在初始启动时,将从配置文件中填充内存和运行时配置。此后,配置将保留在ProxySQL 的嵌入式 SQLite 数据库中。
通过使用 --initial 标志运行 ProxySQL 可以强制重新发生初始配置,这会将 SQLite 数据库文件重置为其原始状态(即配置文件中定义的状态)并重命名现有的 SQLite 数据库文件。
如果需要回滚(如果需要,检查已定义的数据目录中的旧文件)。
重新加载启动(或--reload)
如果使用 --reload 标志执行 ProxySQL,它会尝试将配置文件中的配置与数据库文件的内容合并。之后,ProxySQL 将继续启动程序。
如果配置文件和数据库文件的参数存在冲突,则无法保证 ProxySQL 将成功管理合并,用户应始终验证合并结果是否符合预期。
核心配置表
在运行时修改配置是通过 ProxySQL 的 MySQL 管理端口(默认为 6032)完成的。
连接到它后,您将看到一个与 MySQL 兼容的接口,用于查询各种与 ProxySQL 相关的表:
mysql> show tables;+-------------------+| tables |+-------------------+| mysql_servers || mysql_users || mysql_query_rules || global_variables || mysql_collations || debug_levels |+-------------------+
每个这样的表都有明确的定义:
mysql_servers: 包含要连接的 ProxySQL 的后端服务器列表
mysql_users: 包含 ProxySQL 将用于向后端服务器进行身份验证的用户列表
mysql_query_rules: 包含用于缓存,路由或重写发送到 ProxySQL 的SQL查询的规则
global_variables: 包含在服务器初始配置期间定义的 MySQL 变量和管理变量
debug_levels: 仅用于调试 ProxySQL 的手动构建
在不同层级间移动配置信息
为了将配置持久化到磁盘或将配置加载到运行时,可以使用一组不同的管理命令,这些命令可以通过管理界面执行。
一旦理解了三层中的每一层的使用方式,语义都应该清楚。
连同每个命令的说明,每个命令旁边都有一个编号选项。该数字对应于下图中列出的箭头。
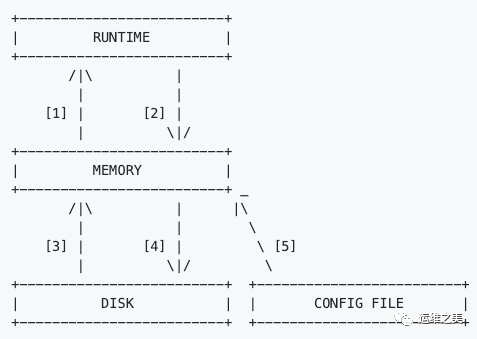
要重新配置 MySQL 用户,请执行以下命令之一:
[1] LOAD MYSQL USERS FROM MEMORY LOAD MYSQL USERS TO RUNTIME
将 MySQL 用户从 MEMORY 加载到 RUNTIME 数据结构,反之亦然。
[2] SAVE MYSQL USERS TO MEMORY SAVE MYSQL USERS FROM RUNTIME
将 MySQL 用户从 RUNTIME 保存到 MEMORY
[3] LOAD MYSQL USERS TO MEMORY LOAD MYSQL USERS FROM DISK
将持久化的 MySQL 用户从磁盘数据库加载到 MEMORY
[4] SAVE MYSQL USERS FROM MEMORY SAVE MYSQL USERS TO DISK
将 MySQL 用户从 MEMORY 中保存到 DISK
[5] LOAD MYSQL USERS FROM CONFIG
从配置文件加载用户到 MEMORY
常用的命令参考:
LOAD MYSQL USERS TO RUNTIME;SAVE MYSQL USERS TO DISK;LOAD MYSQL SERVERS TO RUNTIME;SAVE MYSQL SERVERS TO DISK;LOAD MYSQL QUERY RULES TO RUNTIME;SAVE MYSQL QUERY RULES TO DISK;LOAD MYSQL VARIABLES TO RUNTIME;SAVE MYSQL VARIABLES TO DISK;LOAD ADMIN VARIABLES TO RUNTIME;SAVE ADMIN VARIABLES TO DISK;注意:关键字 MEMORY/RUNTIME 都支持缩写:MEM for MEMORYRUN for RUNTIME
故障排除
请注意,只有在将值加载到运行时才会进行最终验证。
可以设置一个值,该值在保存到内存时不会引发任何类型的警告或错误,甚至可以保存到磁盘。
但是,当执行加载到运行时,会自动将更改恢复为先前已经保存的状态。
如果发生这种情况,应该检查定义的错误日志文件:
例如:
[WARNING] Impossible to set variable monitor_read_only_interval with value "0". Resetting to current "1500".
常用的一些命令技巧
1. 限制 ProxySQL 到后端 MySQL 的连接数通过权重,来控制 ProxySQL 到后端 MySQL 的访问量
权重只作用在同一个 hostgroup 中有效

2. 自动回避复制延迟较大的节点
如果服务器将 max_replication_lag 设置为非零值,则 Monitor 模块会定期检查复制延迟。
下图中,当172.16.0.3的复制延迟超过了30秒会自动回避,设置max_replication_lag = 0,代表不检查复制延迟 。
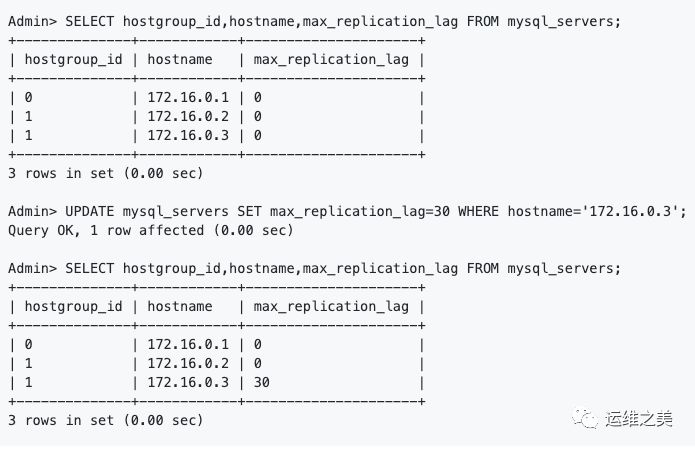
注意,max_replication_lag主要来源Seconds_Behind_Master,该参数判断延迟准确性不高,顾个人建议为参考功能。
3. Master Slave,将 Master 作为 Slave 的备用读节点
在下面的示例中,如果我们将 HG1 配置为提供读请求,则 99.95% 的请求将发送到 172.16.0.2 和 172.16.0.3,而 0.05% 的请求将正常发送到172.16.0.1。
如果 172.16.0.2 和 172.16.0.3 不可用,172.16.0.1 将获取所有读取请求。
注意:max_replication_lag 仅适用于从节点。如果服务器未启用复制,则 Monitor 不会执行任何操作。

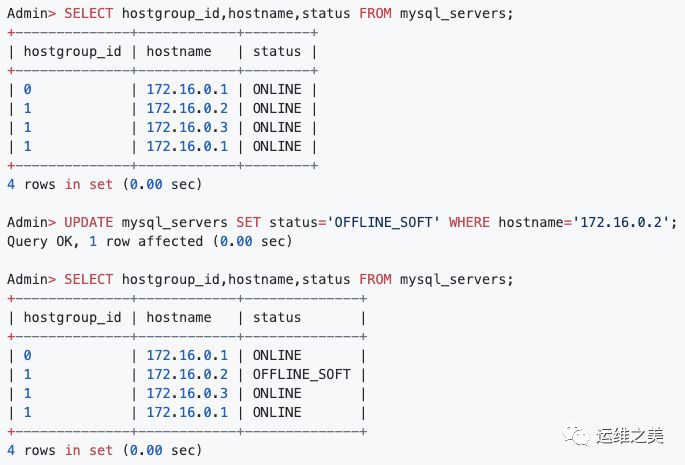
4. 优雅的禁用后端 Server
要正常禁用后端服务器,需要将其状态更改为 OFFLINE_SOFT。
不会影响当前的活动事务和连接,但不会向该节点发送新流量。
5. 立即禁用后端 Server
要立即禁用后端服务器,需要将其状态更改为 OFFLINE_HARD。所有当前请求将立即终止,并且不会发送新请求。
172.18.0.1 设置了OFFLINE_HARD 会立刻中断当前的请求。

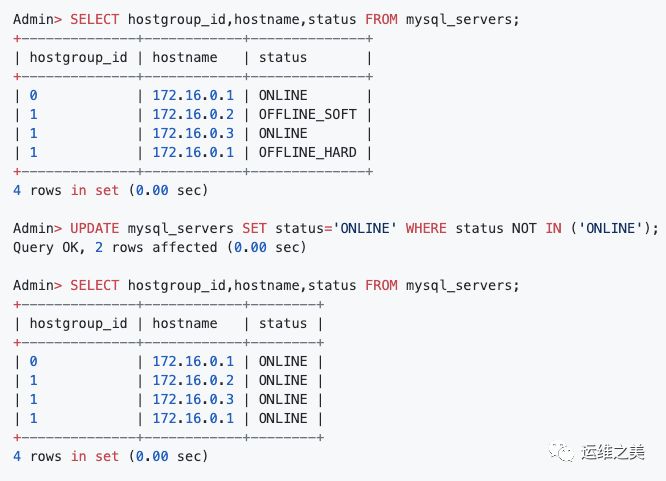
6. 重新启用脱机/禁用后端 Server
要在离线后端重新启用,将其状态更改回ONLINE就可以了
7. 删除后端 Server
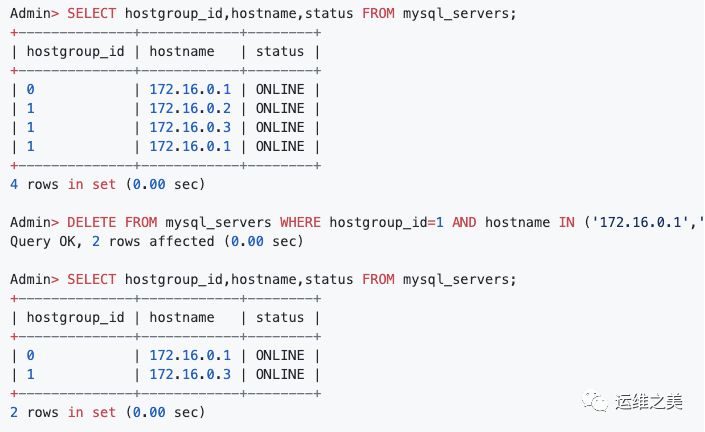
注意:
在内部,删除后端或将其设置为 OFFLINE_HARD 的方式相同。
当执行 LOAD MYSQL SERVERS TO RUNTIME 时,Hostgroup_Manager 将检测到后端服务器已被删除,并在内部将其标记为 OFFLINE_HARD。
8. 将明文密码转换成Hash密码,配置到ProxySQL中的mysql_users表
mysql_users表,支持明文密码和 Hash 密码的写入,但生产环境,我们还是建议用 Hash 密码。
将明文密码转换Hash密码有两种方式:
1. 通过PASSWORD()
该函数生成 Hash 密码,但该函数 ProxySQL 是不支持的,需要在 MySQL 数据库里自行生成,再粘贴加密后的密码插入到 ProxySQL 中。
2.通过变量:admin-hash_passwords(推荐)
此参数默认开启,明文密码存放到MEMORY的mysql_user中,一旦load到RUNTIME会自动HASH加密。
然后再 SAVE 回 MEMORY/DISK 即可完成明文到 Hash 密码的转换。
9. 限制 User 和 ProxySQL 之间的连接数

10. 同个事务内的 SQL,禁止被路由到不同节点上
启动事务后,可能会根据查询规则将某些查询发送到其他主机组。为了防止这种情况发生,可以开启 transaction_persistent。

The Admin Schemas
ProxySQL 管理界面是一个使用 MySQL 协议的界面,任何能够通过这种界面发送命令的客户端都很容易配置它。
ProxySQL 解析通过此接口发送的查询以查找特定于 ProxySQL 的任何命令,如果适当,则将它们发送到嵌入式 SQLite3 引擎以运行查询。
请注意,SQLite3 和 MySQL 使用的 SQL 语法不同,因此并非所有适用于MySQL 的命令都适用于 SQLite3。例如,尽管管理界面接受 USE 命令,但它不会更改默认架构,因为 SQLite3 中不提供此功能。
连接到 ProxySQL 管理界面时,我们可以看到有一些数据库可用。ProxySQL 将 SHOW DATABASES 命令转换为 SQLite3 的等效命令。

这些数据库的作用如下:
main:内存配置数据库 。
使用此数据库,可以轻松地以自动方式查询和更新 ProxySQL 的配置。
使用 LOAD MYSQL USERS FROM MEMORY 和类似命令,存储在此处的配置可以在运行时传播到 ProxySQL 使用的内存数据结构。
disk:基于磁盘的 “main” 镜像。
在重新启动时,“main” 不会持久存在,并且可以从 “磁盘” 数据库或配置文件中加载,具体取决于启动标志和磁盘数据库的存在。
stats:包含从代理的内部功能收集的运行时指标。
示例度量标准包括每个查询规则匹配的次数,当前运行的查询等。
monitor:包含与 ProxySQL 连接的后端服务器相关的监控指标。
示例度量标准包括连接到后端服务器或对其进行ping操作的最短和最长时间。
myhgm:仅在调试版本中启用。
此外,使用这两种类型的用户使用这些默认凭据访问管理数据库。user:admin password:admin - 具有对所有表的读写访问权限
user:stats password:stats - 具有对统计表的只读访问权限。这用于从ProxySQL中提取指标,而不会暴露太多的数据库。
上述的访问凭据,可通过变量 admin-admin_credentials 和 admin-stats_credentials 进行配置。
MAIN 数据库
主要包含了以下数据表:
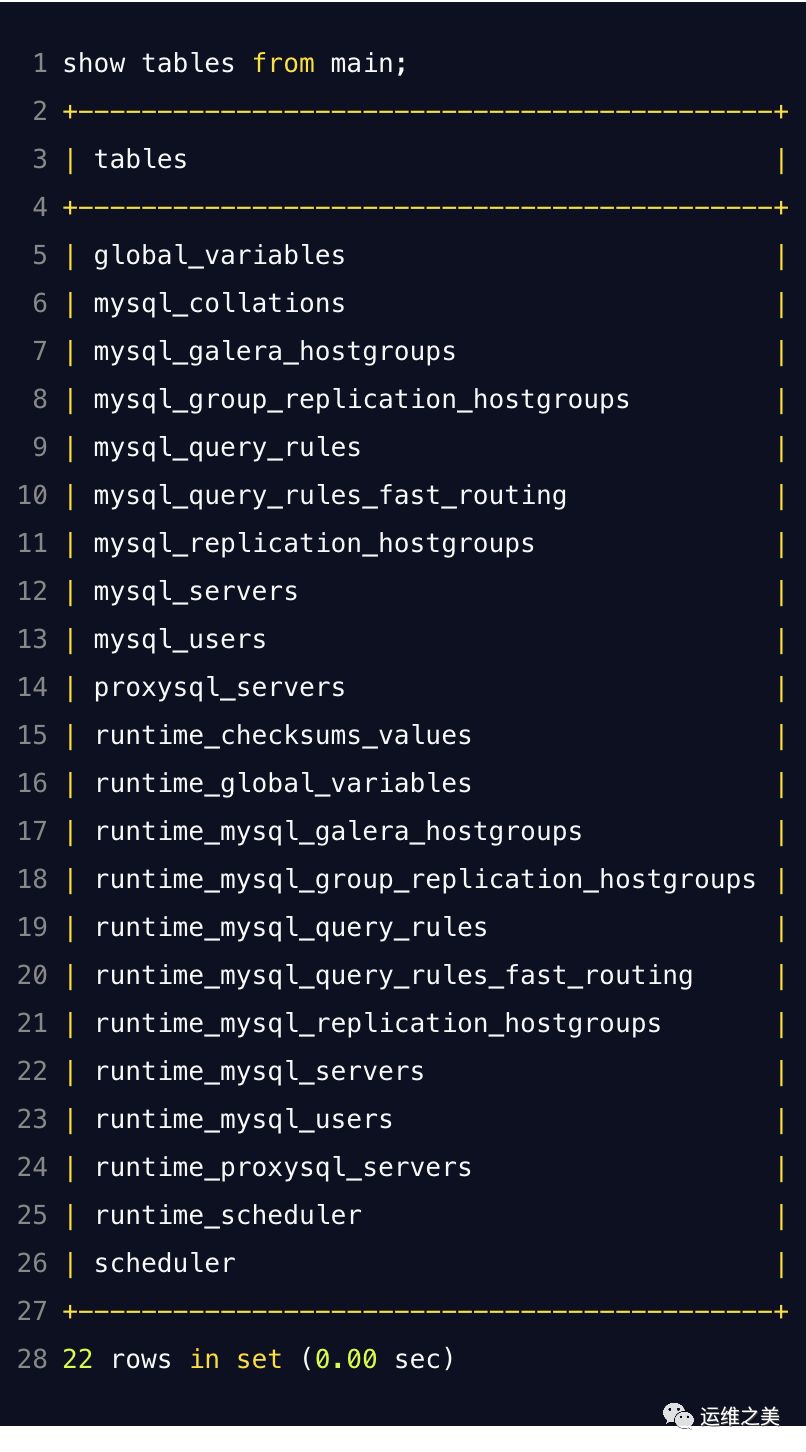
核心配置表
1. mysql_server
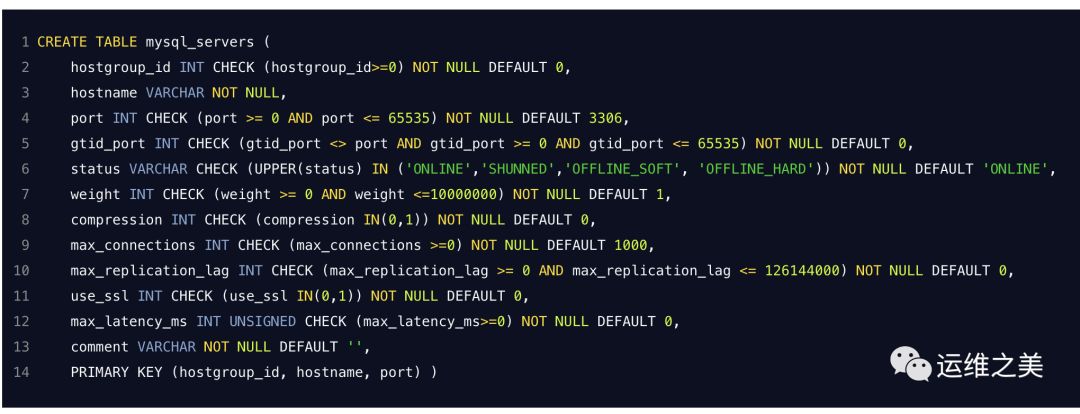
字段定义
hostgroup_id
包含此 mysqld 实例的主机组。请注意,同一实例可以是多个主机组的一部分
hostname,port
可以联系 mysqld 实例的 TCP 端点
gtid_port
ProxySQL Binlog Reader 侦听 GTID 跟踪的后端服务器端口
status
ONLINE - 后端服务器完全可以运行
SHUNNED - 后端服务器暂时停止使用,因为在时间太短或复制延迟超过允许阈值的情况下连接错误太多
OFFLINE_SOFT - 当服务器进入 OFFLINE_SOFT 模式时,不再接受新的传入连接,而现有连接将保持不变,直到它们变为非活动状态。换句话说,连接一直在使用,直到当前事务完成。这允许优雅地分离后端
OFFLINE_HARD - 当服务器进入 OFFLINE_HARD 模式时,现有连接被丢弃,而新的传入连接也不被接受。这相当于从主机组中删除服务器,或暂时将其从主机组中取出以进行维护工作
weight
服务器相对于其他权重的权重越大,从主机组中选择服务器的概率就越高
compression如果该值大于0,则与该服务器的新连接将使用压缩
max_connectionsProxySQL将向此后端服务器打开的最大连接数。即使此服务器具有最高权重,但一旦达到此限制,就不会向其打开新连接。请确保后端配置了正确的max_connections值,以避免ProxySQL尝试超出该限制
max_replication_lag如果更大且为0,ProxySQL将定期监视复制延迟,如果超出此阈值,它将暂时避开主机,直到复制赶上
use_ssl如果设置为1,则与后端的连接将使用SSL
max_latency_ms定期监视ping时间。如果主机的ping时间大于max_latency_ms,则它将从连接池中排除(尽管服务器保持ONLINE状态)
comment可用于用户定义的任何目的的文本字段。可以是主机存储内容的描述,添加或禁用主机的提醒,或某些检查器脚本处理的 JSON。
2. mysql_replication_hostgroups
表 mysql_replication_hostgroups 定义用于传统主/从异步或者半同步或者增强半同步复制的复制主机组。
如果使用 Group Replication InnoDB Cluster 或 Galera Percona XtraDB Cluster 进行复制,则应使用 mysql_group_replication_hostgroups 或mysql_galera_hostgroups(在2.x版中提供)。

mysql_replication_hostgroups中的每一行代表一对writer_hostgroup和reader_hostgroup。
ProxySQL 将监视指定主机组中所有服务器的 read_only 值,并根据 read_only 的值将服务器分配给 writer 组或 reader 组。
字段的注释可用于存储任意数据。
字段定义
writer_hostgroup - 默认情况下将发送所有请求的主机组,MySQL 中 read_only = 0 的节点将分配给该主机组。
reader_hostgroup - 应该发送读取请求的主机组,应该定义查询规则或单独的只读用户将流量路由到此主机组,将 read_only = 1 的节点分配给该主机组。
check_type - 执行只读检查时检查的 MySQL 变量,默认情况下为 read_only(也可以使用 super_read_only)。对于AWS Aurora,应使用innodb_read_only。
comment - 可用于用户定义的任何目的的文本字段。可以是集群存储内容的描述,添加或禁用主机组的提醒,或某些检查器脚本处理的 JSON。
3. mysql_group_replication_hostgroups(MGR)
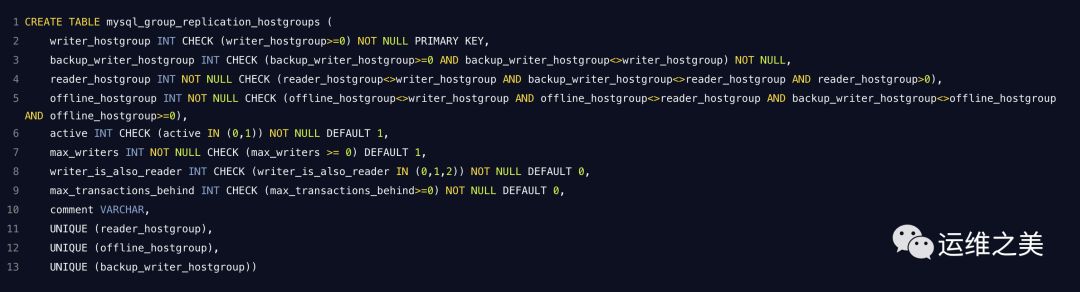
字段定义
writer_hostgroup - 默认情况下将发送所有请求的主机组,MySQL 中 read_only = 0 的节点将分配给该主机组。
backup_writer_hostgroup - 如果集群有多个节点,其 read_only = 0 和max_writers,则 ProxySQL 会将其他节点(超过max_writes的节点)放入 backup_writer_hostgroup 中。
reader_hostgroup - 应该发送读请求的主机组,将 read_only = 1 的节点分配给该主机组。
offline_hostgroup - 当 ProxySQL 的监视确定节点为 OFFLINE 时,它将被放入offline_hostgroup。
active - 启用时,ProxySQL 监视主机组并在适当的主机组之间移动节点。
max_writers - 此值确定 writer_hostgroup 中应允许的最大节点数,超过此值的节点将放入 backup_writer_hostgroup 中
writer_is_also_reader - 确定是否应将同一个节点添加到 reader_hostgroup 和writer_hostgroup 中。
max_transactions_behind - 确定在屏蔽节点之前,ProxySQL 应允许的写入器后面的最大事务数,以防止读取落后过多(这是通过查询 MySQL 中sys.gr_member_routing_candidate_status表的transactions_behind 字段来确定的)。
comment - 可用于用户定义的任何目的的文本字段。可以是集群存储内容的描述,添加或禁用主机组的提醒,或某些检查器脚本处理的 JSON。
4. mysql_galera_hostgroups(PXC)
表 mysql_galera_hostgroups(在 ProxySQL 2.x 及更高版本中可用)定义了用于 Galera Cluster Percona XtraDB Cluster 的主机组。
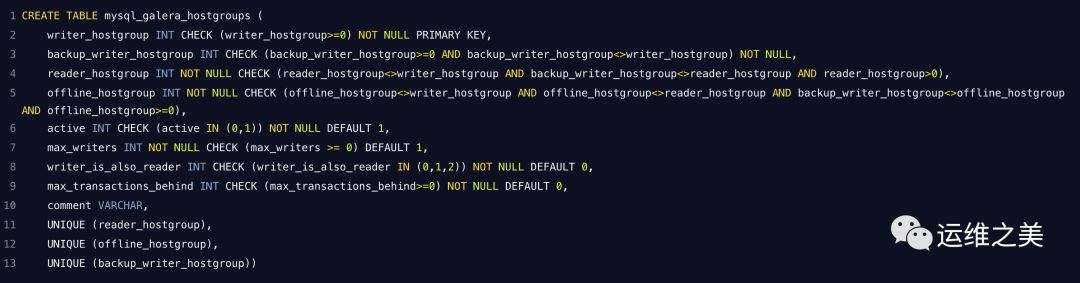
字段定义
writer_hostgroup - 默认情况下将发送所有流量的主机组,MySQL 中 read_only = 0 的节点将分配给该主机组。
backup_writer_hostgroup - 如果集群有多个节点,其 read_only = 0 和max_writers,则 ProxySQL 会将其他节点(超过 max_writes )放入 backup_writer_hostgroup 中。
reader_hostgroup - 应该发送读取流量的主机组,应该定义查询规则或单独的只读用户将流量路由到此主机组,将 read_only = 1 的节点分配给该主机组。
offline_hostgroup - 当 ProxySQL 的监控确定主机处于OFFLINE 时,它将被放入 offline_hostgroup
active - 启用时,ProxySQL 监视主机组并在适当的主机组之间移动服务器。
max_writers - 此值确定 writer_hostgroup 中应允许的最大节点数,超过此值的节点将放入 backup_writer_hostgroup 中
writer_is_also_reader - 确定是否应将节点添加到 reader_hostgroup 以及在提升后的 writer_hostgroup。
max_transactions_behind - 确定在避开节点之前 ProxySQL 应允许的集群后面的最大写集数,以防止过时读取(这是通过查询 wsrep_local_recv_queue Galera变量确定的)。
comment - 可用于用户定义的任何目的的文本字段。可以是集群存储内容的描述,添加或禁用主机组的提醒,或某些检查器脚本处理的 JSON。
5. mysql_users
表 mysql_users 定义 MySQL 用户,用于连接后端。
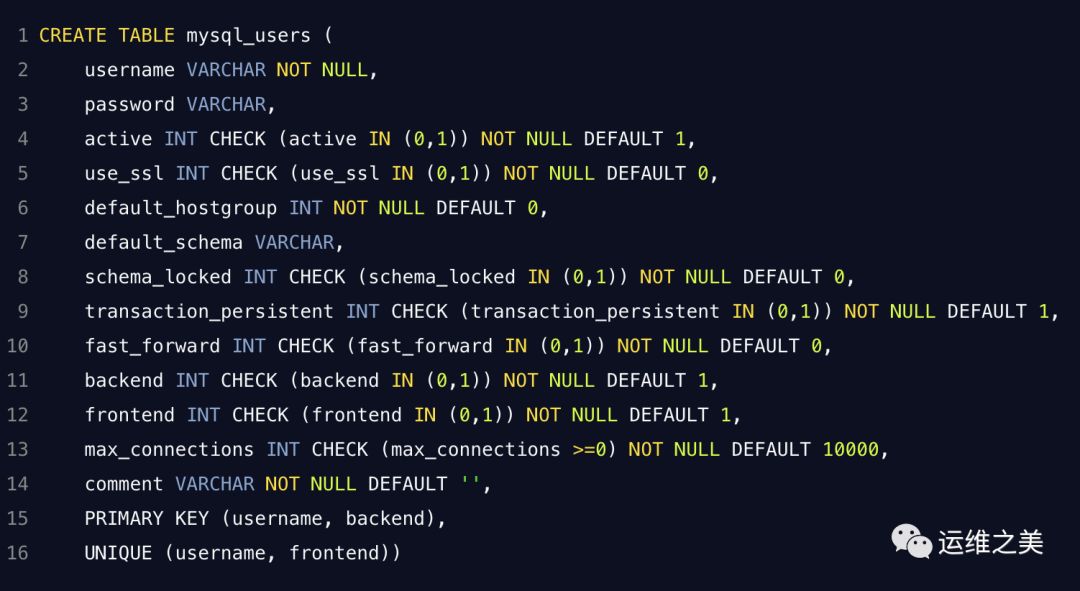
字段定义
username,password - 用于连接 mysqld 或 ProxySQL 实例的凭据。
active - 将在数据库中跟踪 active = 0 的用户,但永远不会在内存数据结构中加载
default_hostgroup - 如果此用户发送的查询没有匹配规则,则生成的流量将发送到指定的主机组
default_schema - 默认情况下连接应更改的架构
schema_locked - 尚不支持(TODO:check)
transaction_persistent - 如果是一个事务内的多条 SQL,只会路由到一个主机组中。
fast_forward - 如果设置,它绕过查询处理层(重写,缓存)并直接将查询传递给后端服务器。
frontend - 如果设置为1,则此(用户名,密码)对用于对 ProxySQL 实例进行身份验证
backend - 如果设置为1,则此(用户名,密码)对用于针对任何主机组对 mysqld 服务器进行身份验证
max_connections - 定义特定用户的最大允许前端连接数。
comment - 可用于用户定义的任何目的的文本字段。可以是集群存储内容的描述,添加或禁用主机组的提醒,或某些检查器脚本处理的 JSON。
注意,目前所有用户都需要将 “frontend” 和“后 backend” 都设置为 1。
ProxySQL 的未来版本将在前端和后端之间分离证书。
通过这种方式,前端永远不会知道直接连接到后端的凭证,强制通过 ProxySQL 进行所有连接并提高系统的安全性。
fast_forward 注意事项:
1. 它不需要不同的端口:完整的功能代理逻辑和“快进”逻辑在同一代码/模块中实现
2. fast_forward 是基于每个用户实现的:取决于连接到 ProxySQL 的用户,启用或禁用 fast_forward
3. 验证后启用 fast_forward 算法:客户端仍然对 ProxySQL 进行身份验证,当客户端开始发送流量时,ProxySQL 将创建连接。这意味着在连接阶段仍然会处理连接错误。
4. fast_forward 不支持 SSL
5. 如果使用压缩,则必须在两端启用它
注意:mysql_users 中的用户也不应该与 admin-admin_credentials 和 admin-stats_credentials 里的配置相同
6. mysql_query_rules
表 mysql_query_rules 定义了路由策略和属性。
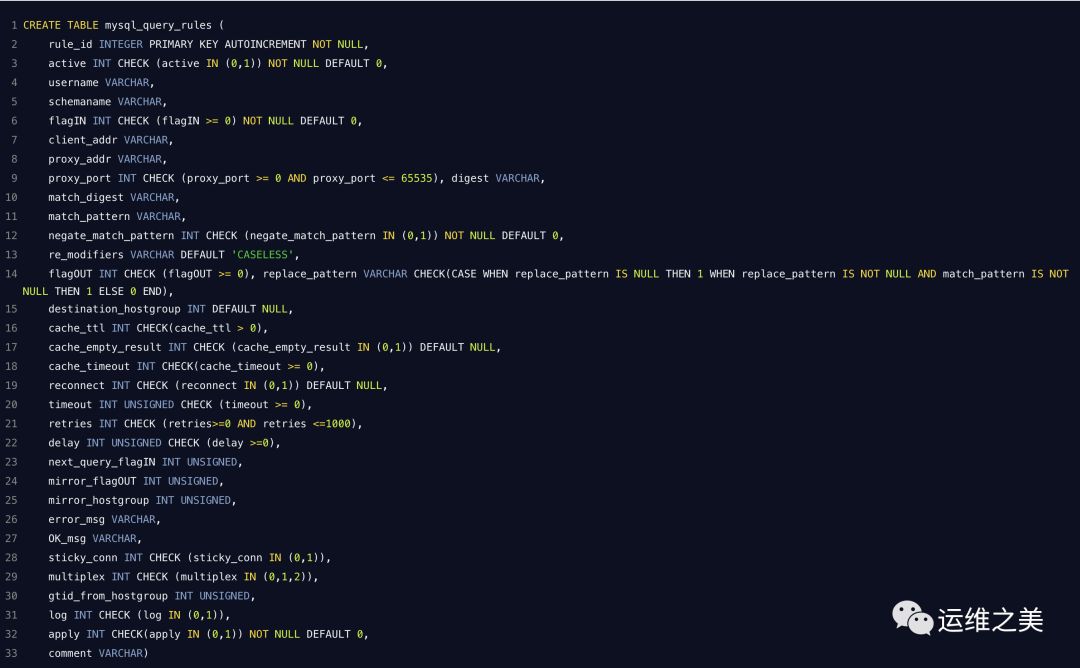
字段定义
rule_id - 规则的唯一 ID。规则以 rule_id 顺序处理
active - 查询处理模块将仅考虑 active = 1 的规则,并且只将活动规则加载到运行时。
username - 匹配用户名的过滤条件。如果为非 NULL,则仅当使用正确的用户名建立连接时,查询才会匹配
schemaname - 匹配 schemaname 的过滤条件。如果为非 NULL,则仅当连接使用 schemaname 作为默认模式时,查询才会匹配(在 mariadb mysql schemaname 中等效于 databasename)
flagIN,flagOUT,apply -
这些允许我们创建一个接一个地应用的“规则链”。
输入标志值设置为 0,并且在开始时仅考虑 flagIN = 0 的规则。
当为特定查询找到匹配规则时,将评估 flagOUT,如果为 NOT NULL,则将使用flagOUT 中的指定标志标记查询。
如果 flagOUT 与 flagIN 不同,则查询将退出当前链并输入一个新的规则链,其中flagIN 作为新的输入标志。
如果 flagOUT 与 flagIN 匹配,则将针对具有所述flagIN的第一个规则再次重新评估查询。
这种情况会发生,直到没有更多匹配规则,或者 apply 设置为 1(这意味着这是要应用的最后一条规则)
client_addr - 匹配来自特定源的流量
proxy_addr - 匹配特定本地 IP 上的传入流量
proxy_port - 匹配特定本地端口上的传入流量
使用 stats_mysql_query_digest.digest 返回的特定摘要匹配查询
match_digest - 与查询摘要匹配的正则表达式。另请参见https://github.com/sysown/proxysql/wiki/Global-variables#mysql-query_processor_regex
match_pattern - 与查询文本匹配的正则表达式。另请参见https://github.com/sysown/proxysql/wiki/Global-variables#mysql-query_processor_regex
negate_match_pattern - 如果将其设置为 1,则只有与查询文本不匹配的查询才会被视为匹配项。这在与 match_pattern 或 match_digest 匹配的正则表达式前面充当 NOT 运算符
re_modifiers -
用逗号分隔的选项列表,用于修改RE引擎的行为。使用CASELESS,匹配不区分大小写。
使用GLOBAL,替换是全局的(替换所有匹配而不仅仅是第一个匹配)。
为了向后兼容,默认情况下仅启用CASELESS。有关更多详细信息,另请参见https://github.com/sysown/proxysql/wiki/Global-variables#mysql-query_processor_regex。
replace_pattern -
这是用于替换匹配模式的模式。
它是使用RE2 :: Replace完成的,因此值得一看有关的在线文档:https://github.com/google/re2/blob/master/re2/re2.h#L378。
请注意,这是可选的,当缺少此选项时,查询处理器将仅缓存,路由或设置其他参数而不重写。
destination_hostgroup -
将匹配的查询路由到此主机组。
除非存在已启动的事务且登录用户将transaction_persistent标志设置为1(请参阅mysql_users表),否则会发生这种情况。
cache_ttl - 缓存查询结果的毫秒数。注意:在 ProxySQL 1.1 中,cache_ttl 只需几秒钟
cache_empty_result -
控制是否缓存没有行的结果集
重新连接 - 未使用的功能
timeout -
应执行匹配或重写查询的最大超时(以毫秒为单位)。
如果查询运行的时间超过特定阈值,则会自动终止查询。如果未指定timeout,则应用全局变量mysql-default_query_timeout
retries - 在执行查询期间检测到失败时需要重新执行查询的最大次数。如果未指定重试,则应用全局变量 mysql-query_retries_on_failure
delay -
延迟执行查询的毫秒数。
这本质上是一种限制机制和QoS,允许优先考虑某些查询而不是其他查询。
此值将添加到适用于所有查询的mysql-default_query_delay全局变量中。未来版本的ProxySQL将提供更高级的限制机制。
mirror_flagOUT 和 mirror_hostgroup - 与镜像相关的设置 https://github.com/sysown/proxysql/wiki/Mirroring。
error_msg - 将阻止查询,并将指定的 error_msg 返回给客户端
OK_msg - 将为使用已定义规则的查询返回指定的消息
sticky_conn - 尚未实现
multiplex -
如果为0,则禁用Multiplex。
如果为1,如果没有任何其他条件阻止此操作(如用户变量或事务),则可以重新启用Multiplex。
如果为2,则不会仅针对当前查询禁用多路复用。请参阅 wiki 默认为 NULL,因此不会修改多路复用策略
gtid_from_hostgroup - 定义哪个主机组应该用作 GTID 一致性读取的领导者(通常是复制主机组对中定义的 WRITER 主机组)
log- 将记录查询
apply - 当设置为1时,在匹配和处理此规则后,将不再评估进一步的查询(注意:之后不会评估 mysql_query_rules_fast_routing 规则)
comment- 自由格式文本字段,可用于查询规则的描述性注释
7. mysql_query_rules_fast_routing
表 mysql_query_rules_fast_routing 是 mysql_query_rules 的扩展,之后会对快速路由策略和属性进行评估(仅在ProxySQL 1.4.7+中可用)。
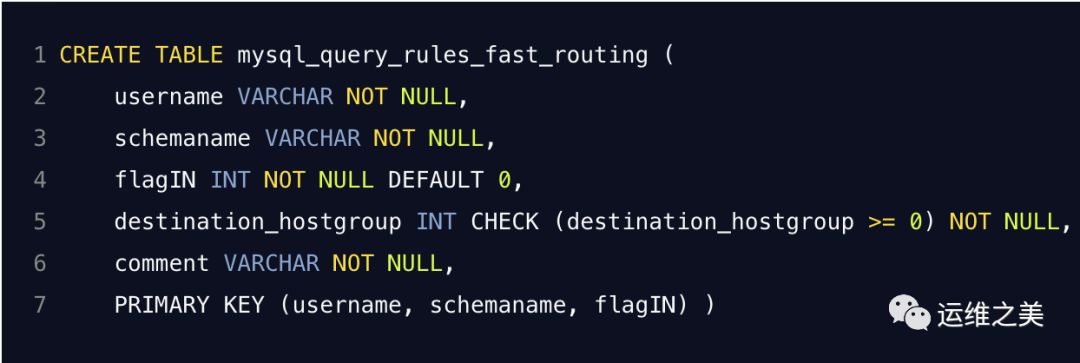
字段定义
username - 与用户名匹配的过滤条件,只有在使用正确的用户名建立连接时,查询才会匹配
schemaname - 匹配 schemaname 的过滤条件,只有当连接使用 schemaname作为默认模式时,查询才会匹配(在 mariadb mysql schemaname 中,这相当于 databasename)
flagIN - 与 mysql_query_rules 中 flagin 相同,并与 mysql_query_rules 表中指定的 flagout apply 相关联
destination_hostgroup - 将匹配的查询路由到此主机组。
comment- 自由格式文本字段,可用于查询规则的描述性注释
8. global_variablesmysql_collationsscheduler
暂不介绍了,后面会逐步投在功能介绍里提及
Runtime 层对应表
表以 runtime_开头,其余基本与MAIN库中的表名相同,例如:runtime_mysql_servers 是 内存层 mysql_servers表的对应表
runtime_global_variables : runtime version of global_variables
runtime_mysql_replication_hostgroups : runtime version of mysql_replication_hostsgroups
runtime_mysql_galera_hostgroups : runtime version of mysql_replication_hostsgroups
runtime_mysql_group_replication_hostgroups : runtime version of mysql_replication_hostsgroups
runtime_mysql_query_rules : runtime version of mysql_query_rules
runtime_mysql_query_rules_fast_routing : runtime version of mysql_query_rules_fast_routing
runtime_mysql_servers : runtime version of mysql_servers
runtime_mysql_users : runtime version of mysql_users
runtime_proxysql_servers : runtime version of proxysql_servers
runtime_scheduler : runtime version of scheduler
请注意,如果 ProxySQL 重新启动,如果内容未保存在磁盘数据库中,则内存表(MAIN数据库)的所有内容都将丢失。
Disk 层对应表
“disk” 数据库与 “main” 数据库具有完全相同的表,具有相同的语义。
唯一的主要区别是这些表存储在磁盘上,而不是存储在内存中。
每当重新启动 ProxySQL 时,将从此数据库开始填充内存中的 “main” 数据库。
监控MGR,需要在 MySQL 实例中配置一些监控脚本(MySQL 5.7 和 MySQL 8.0 略有不同)
该脚本需要配置到 sys 库下,因笔记 web 显示问题,无法显示折行,但是不影响复制,可以自行复制粘贴出来即可。
先看看执行效果
select * from sys.gr_member_routing_candidate_status;+------------------+-----------+---------------------+----------------------+| viable_candidate | read_only | transactions_behind | transactions_to_cert |+------------------+-----------+---------------------+----------------------+| YES | NO | 0 | 0 |+------------------+-----------+---------------------+----------------------+viable_candidate:MGR当前节点是否正常read_only:当前节点是否开启了只读transactions_behind:MGR应用relay log的队列中,积压事务数transactions_to_cert:MGR当前节点的验证队列,积压事务数
MySQL 5.7 配置脚本为:
USE sys;DELIMITER $$CREATE FUNCTION IFZERO(a INT, b INT) RETURNS INT DETERMINISTIC RETURN IF(a = 0, b, a)$$CREATE FUNCTION LOCATE2(needle TEXT(10000), haystack TEXT(10000), offset INT)RETURNS INT DETERMINISTIC RETURN IFZERO(LOCATE(needle, haystack, offset), LENGTH(haystack) + 1)$$CREATE FUNCTION GTID_NORMALIZE(g TEXT(10000))RETURNS TEXT(10000) DETERMINISTIC RETURN GTID_SUBTRACT(g, '')$$CREATE FUNCTION GTID_COUNT(gtid_set TEXT(10000))RETURNS INT DETERMINISTIC BEGIN DECLARE result BIGINT DEFAULT 0; DECLARE colon_pos INT;DECLARE next_dash_pos INT; DECLARE next_colon_pos INT; DECLARE next_comma_pos INT;SET gtid_set = GTID_NORMALIZE(gtid_set); SET colon_pos = LOCATE2(':', gtid_set, 1);WHILE colon_pos != LENGTH(gtid_set) + 1 DO SET next_dash_pos = LOCATE2('-', gtid_set, colon_pos + 1);SET next_colon_pos = LOCATE2(':', gtid_set, colon_pos + 1); SET next_comma_pos = LOCATE2(',', gtid_set, colon_pos + 1);IF next_dash_pos < next_colon_pos AND next_dash_pos < next_comma_posTHEN SET result = result + SUBSTR(gtid_set, next_dash_pos + 1,LEAST(next_colon_pos, next_comma_pos) - (next_dash_pos + 1)) - SUBSTR(gtid_set, colon_pos + 1, next_dash_pos - (colon_pos + 1)) + 1;ELSE SET result = result + 1; END IF;SET colon_pos = next_colon_pos;END WHILE; RETURN result;END$$CREATE FUNCTION gr_applier_queue_length()RETURNS INT DETERMINISTICBEGIN RETURN(SELECT sys.gtid_count( GTID_SUBTRACT( (SELECT Received_transaction_setFROM performance_schema.replication_connection_statusWHERE Channel_name = 'group_replication_applier' ), (SELECT @@global.GTID_EXECUTED) )));END$$CREATE FUNCTION gr_member_in_primary_partition()RETURNS VARCHAR(3) DETERMINISTIC BEGIN RETURN (SELECT IF( MEMBER_STATE='ONLINE' AND ((SELECT COUNT() FROM performance_schema.replication_group_members WHERE MEMBER_STATE != 'ONLINE') >= ((SELECT COUNT() FROM performance_schema.replication_group_members)/2) = 0), 'YES', 'NO' )FROM performance_schema.replication_group_membersJOIN performance_schema.replication_group_member_stats USING(member_id));END$$CREATE VIEW gr_member_routing_candidate_status ASSELECTsys.gr_member_in_primary_partition() AS viable_candidate,IF((SELECT(SELECTGROUP_CONCAT(variable_value)FROMperformance_schema.global_variablesWHEREvariable_name IN ('read_only' , 'super_read_only')) != 'OFF,OFF'),'YES','NO') AS read_only,sys.gr_applier_queue_length() AS transactions_behind,Count_Transactions_in_queue AS 'transactions_to_cert'FROMperformance_schema.replication_group_member_stats$$DELIMITER ;
MySQL 8.0 配置脚本为:
USE sys;DELIMITER $$CREATE FUNCTION IFZERO(a INT, b INT)RETURNS INTDETERMINISTICRETURN IF(a = 0, b, a)$$CREATE FUNCTION LOCATE2(needle TEXT(10000), haystack TEXT(10000), offset INT)RETURNS INTDETERMINISTICRETURN IFZERO(LOCATE(needle, haystack, offset), LENGTH(haystack) + 1)$$CREATE FUNCTION GTID_NORMALIZE(g TEXT(10000))RETURNS TEXT(10000)DETERMINISTICRETURN GTID_SUBTRACT(g, '')$$CREATE FUNCTION GTID_COUNT(gtid_set TEXT(10000))RETURNS INTDETERMINISTICBEGINDECLARE result BIGINT DEFAULT 0;DECLARE colon_pos INT;DECLARE next_dash_pos INT;DECLARE next_colon_pos INT;DECLARE next_comma_pos INT;SET gtid_set = GTID_NORMALIZE(gtid_set);SET colon_pos = LOCATE2(':', gtid_set, 1);WHILE colon_pos != LENGTH(gtid_set) + 1 DOSET next_dash_pos = LOCATE2('-', gtid_set, colon_pos + 1);SET next_colon_pos = LOCATE2(':', gtid_set, colon_pos + 1);SET next_comma_pos = LOCATE2(',', gtid_set, colon_pos + 1);IF next_dash_pos < next_colon_pos AND next_dash_pos < next_comma_pos THENSET result = result +SUBSTR(gtid_set, next_dash_pos + 1,LEAST(next_colon_pos, next_comma_pos) - (next_dash_pos + 1)) -SUBSTR(gtid_set, colon_pos + 1, next_dash_pos - (colon_pos + 1)) + 1;ELSESET result = result + 1;END IF;SET colon_pos = next_colon_pos;END WHILE;RETURN result;END$$CREATE FUNCTION gr_applier_queue_length()RETURNS INTDETERMINISTICBEGINRETURN (SELECT sys.gtid_count( GTID_SUBTRACT( (SELECTReceived_transaction_set FROM performance_schema.replication_connection_statusWHERE Channel_name = 'group_replication_applier' ), (SELECT@@global.GTID_EXECUTED) )));END$$CREATE FUNCTION gr_member_in_primary_partition()RETURNS VARCHAR(3)DETERMINISTICBEGINRETURN (SELECT IF( MEMBER_STATE='ONLINE' AND ((SELECT COUNT(*) FROMperformance_schema.replication_group_members WHERE MEMBER_STATE != 'ONLINE') >=((SELECT COUNT(*) FROM performance_schema.replication_group_members)/2) = 0),'YES', 'NO' ) FROM performance_schema.replication_group_members JOINperformance_schema.replication_group_member_stats USING(member_id)where performance_schema.replication_group_members.member_host=@@hostname);END$$CREATE VIEW gr_member_routing_candidate_status ASSELECTsys.gr_member_in_primary_partition() AS viable_candidate,IF((SELECT(SELECTGROUP_CONCAT(variable_value)FROMperformance_schema.global_variablesWHEREvariable_name IN ('read_only' , 'super_read_only')) != 'OFF,OFF'),'YES','NO') AS read_only,sys.gr_applier_queue_length() AS transactions_behind,Count_Transactions_in_queue AS 'transactions_to_cert'FROMperformance_schema.replication_group_member_stats aJOINperformance_schema.replication_group_members b ON a.member_id = b.member_idWHEREb.member_host IN (SELECTvariable_valueFROMperformance_schema.global_variablesWHEREvariable_name = 'hostname')$$DELIMITER ;
还有很多没有总结,一点点来,基础知识梳理完成,会对核心功能再进行测试说明,希望对需要的同学有帮助。
来源:cnblogs
原文:http://t.cn/Ai9B8mrV
题图:来自谷歌图片搜索
版权:本文版权归原作者所有
投稿:欢迎投稿,投稿邮箱: editor@hi-linux.com
文末推荐:极客时间视频专栏 「Elasticsearch 核心技术与实战」,一共 95 讲,约 1000 分钟,更多专栏介绍可戳「这里」。如果你想快速构建分布式搜索和分析引擎,这个课程可以帮到你,该专栏刚上架已经有 8000+ 名同学在学习了。
公众号额外福利:通过下面海报订阅专栏的读者,公众号再返 24 元红包。到手相当于 75 元,非常划算。(购买后,加我微信返现,还没加我微信的可戳「这里」找到我哟~)。
👇 优惠仅剩最后 3 天,抓紧时间订购吧

△ 扫码试读或订阅

推荐阅读


文章转载自公众号:运维之美
