作者:Hironobu SUZUKI
翻译:qinghui.guo
声明:该系列文章为Hironobu SUZUKI的私人项目,为促进PostgreSQL的技术分享,现翻译出来供大家学习。
版权:所有版权归 Hironobu SUZUKI所有,本系列文章只是负责翻译和分享工作,再次感谢大神。
概述:本系列文章,旨在分享PostgreSQL技术,推广PostgreSQL。由于该系列文章原作者还在更新中,中文版将会同步更新
原文链接
PostgreSQL的内部结构—第三章 查询处理
第3章 查询处理第3章 查询处理
3.1。 概述
3.1.1。 分析器
3.1.2。分析器/分析仪
3.1.3。 重写
3.1.4。 规划器和执行器
第3章 查询处理
正如官方文档中所述,PostgreSQL支持2011年SQL标准所需的大量功能。查询处理是PostgreSQL中最复杂的子系统,它可以高效地处理支持的SQL。 本章概述了此查询处理; 特别是,它专注于查询优化。
本章包括以下三个部分:
第1部分:第3.1节。
本节概述了PostgreSQL中的查询处理。
第2部分:第3.2节——3.4。
本部分介绍了获取单表查询的最佳计划所遵循的步骤。 在第3.2和3.3节中,分别解释了估算成本和创建计划树的过程。 在3.4节中,简要描述了执行器的操作。
第3部分:第3.5节——3.6。
本部分介绍了获取多表查询的最优计划的过程。 在3.5节中,描述了三种连接方法:嵌套循环,合并和散列连接。 在3.6节中,解释了创建多表查询计划树的过程。
PostgreSQL支持三个技术上有趣和实用的功能,即外部数据包装(FDW) , 并行查询和JIT编译 ,它们从版本11开始支持。前两个将在第4章中介绍,JIT编译超出这份文档的范围; 详见官方文档 。
3.1。 概述
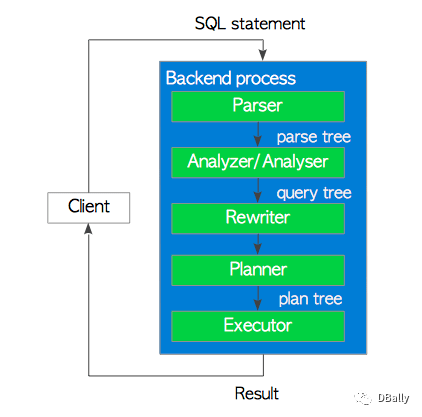
在PostgreSQL中,尽管版本9.6中使用多个后台工作进程实现的并行查询,但后端进程基本上处理由连接的客户端发出的所有查询。 该后端由五个子系统组成,如下所示:
1、解析器
解析器以纯文本形式从SQL语句生成解析树。2、分析器—【转换器,转换过程】
分析器/分析器执行解析树的语义分析并生成查询树。3、重写
如果存在这样的规则,则重写器使用存储在规则系统中的规则来变换查询树。4、规划器–【优化器】
规划器生成可以从查询树中最有效地执行的计划树。5、执行器
执行程序通过按计划树创建的顺序访问表和索引来执行查询。
图3.1。 查询处理。
在本节中,提供了这些子系统的概述。 由于规划器和执行器非常复杂,因此将在以下各节中详细说明这些功能。
PostgreSQL的查询处理在官方文档中有详细描述。
3.1.1。 分析器
解析器生成一个解析树,后续子系统可以从纯文本的SQL语句中读取该解析树。 这里,具体示例如下所示,没有详细描述。
让我们参考下面显示的查询。
testdb =#SELECT id,data FROM tbl_a WHERE id <300 ORDER BY data;
解析树是一个树,其根节点是parsenodes.h中定义的SelectStmt结构。 图3.2(b)说明了图3.2(a)所示查询的解析树。
图3.2。 解析树的一个例子。
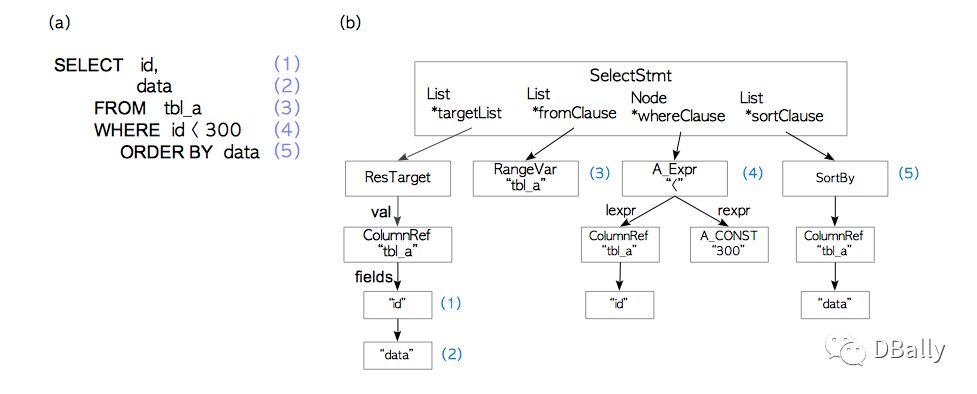
SELECT查询的元素和解析树的相应元素编号相同。 例如,(1)是第一个目标列表的项目,它是表的列“id”,(4)是WHERE子句,依此类推。
由于解析器仅在生成解析树时检查输入的语法,因此只有在查询中存在语法错误时才会返回错误。
解析器不检查输入查询的语义。 例如,即使查询包含不存在的表名,解析器也不会返回错误。 语义检查由分析器/分析器完成。
3.1.2。分析器/分析仪
分析器/分析仪对解析器生成的解析树进行语义分析,并生成查询树。
查询树的根是parsenodes.h中定义的Query结构; 此结构包含其相应查询的元数据,例如此命令的类型(SELECT,INSERT或其他)和几个叶子; 每个叶子形成一个列表或一个树,并保存各个特定条款的数据。
图3.3说明了前一小节中图3.2(a)所示查询的查询树。
图3.3。 查询树的示例。
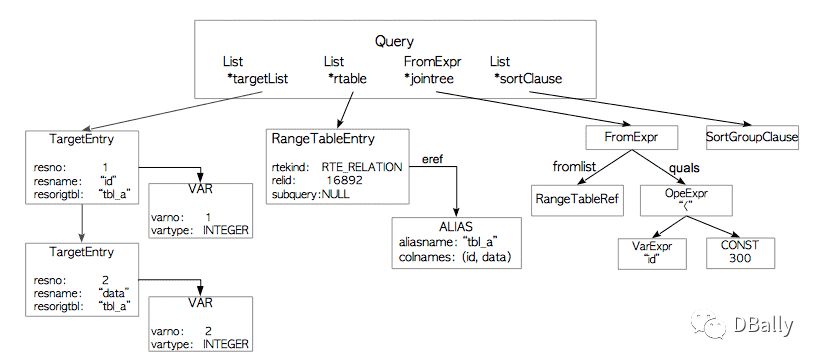
上面的查询树简要描述如下。
目标列表是此查询结果的列列表。 在此示例中,此列表由两列组成: “id”和“data” 。 如果输入查询树使用’ ‘∗’ (星号),分析器/分析器将明确地将其替换为所有列。
范围表是此查询中使用的关系列表。 在此示例中,此表包含表’ tbl_a ‘的信息,例如此表的oid和此表的名称。
连接树存储FROM子句和WHERE子句。
sort子句是SortGroupClause的列表。
官方文档中描述了查询树的详细信息。
3.1.3。 重写
重写器是实现规则系统的系统 ,并在必要时根据存储在pg_rules系统目录中的规则转换查询树。 规则系统本身就是一个有趣的系统,但是,省略了对规则系统和重写器的描述以防止本章变得太长。
视图
PostgreSQL中的视图是使用规则系统实现的。 当CREATE VIEW命令定义视图时 ,将自动生成相应的规则并将其存储在目录中。
假设已定义以下视图,并且相应的规则存储在pg_rules系统目录中。
sampledb = #CREATE VIEW employees_list
sampledb- #AS SELECT e.id,e.name,d.name AS部门
sampledb-#FROM employees AS e,departments AS d WHERE e.department_id = d.id;
当发出包含如下所示视图的查询时,解析器将创建解析树,如图3.4(a)所示。
sampledb =#SELECT * FROM employees_list;
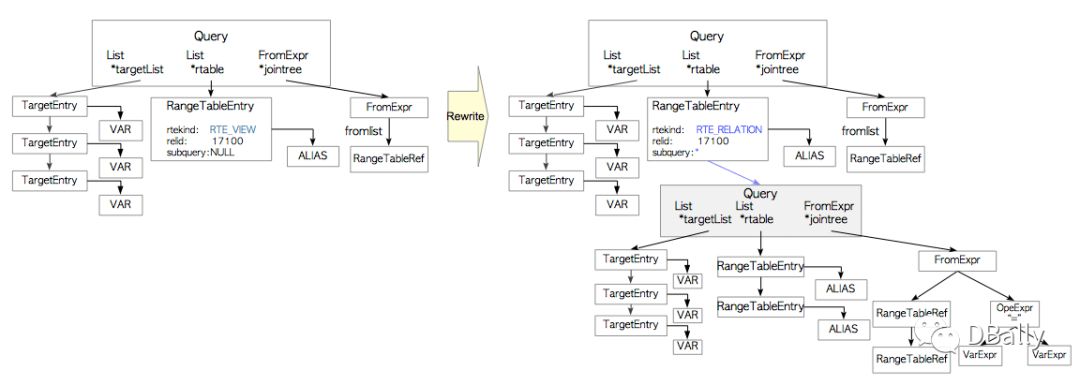
在此阶段,重写器将范围表节点处理为子查询的分析树,该分析树是存储在pg_rules中的相应视图。
图3.4。 重写阶段的一个例子。
由于PostgreSQL使用这种机制实现视图,因此在版本9.2之前无法更新视图。 但是,视图可以从9.3版开始更新; 尽管如此,更新视图还有许多限制。 这些细节在官方文件中有描述。
3.1.4。 规划器和执行器
规划器从重写器接收查询树并生成(查询)计划树,该树可以由执行器最有效地处理。
PostgreSQL中的规划器基于纯粹的基于成本的优化; 它不支持基于规则的优化和提示。 该规划器是RDBMS中最复杂的子系统; 因此,本章后续章节将提供对规划人员的概述。
pg_hint_plan
PostgreSQL不支持SQL中的计划程序提示,并且不会永久支持它。 如果要在查询中使用提示,则引用pg_hint_plan的扩展名值得考虑。 详细信息请参阅官方网站 。
与其他RDBMS一样,PostgreSQL中的EXPLAIN命令显示计划树本身。 具体示例如下所示。
testdb = #EXPLAIN SELECT * FROM tbl_a WHERE id <300 ORDER BY data;
查询计划
---------------------------------------------------------------
排序(成本= 182.34..183.09行= 300宽度= 8)
排序键:数据
- > seq扫描tbl_a(成本= 0.00..170.00行= 300宽度= 8)
过滤器:(id <300)
(4排)
该结果显示了图3.5中所示的计划树。
图3.5。 一个简单的计划树以及计划树和EXPLAIN命令结果之间的关系。
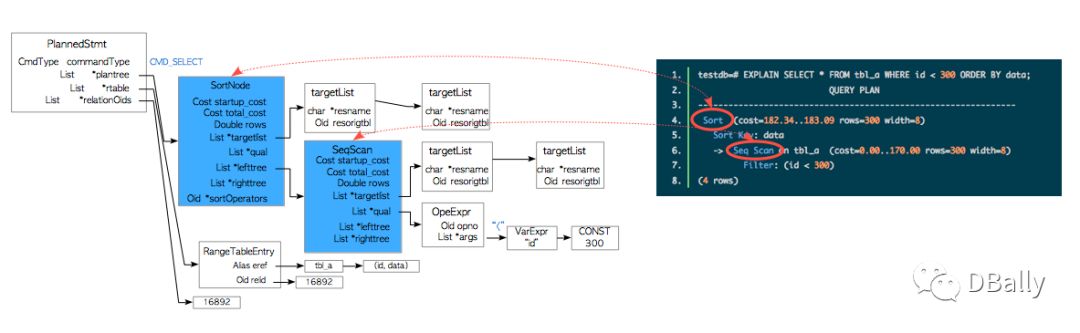
计划树由称为计划节点的元素组成,并且它连接到PlannedStmt结构的工厂列表。 这些元素在plannodes.h中定义。 细节将在第3.3.3节(和第3.5.4.2节)中解释。
每个计划节点都具有执行程序处理所需的信息,并且执行程序在单表查询的情况下从计划树的末尾处理到根。
例如,图3.5中所示的计划树是排序节点和顺序扫描节点的列表; 因此,执行程序通过顺序扫描扫描表: tbl_a ,然后对获得的结果进行排序。
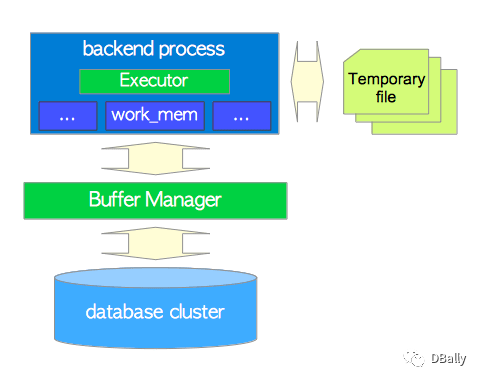
执行程序通过第8章中描述的缓冲区管理器在数据库集群中读取和写入表和索引。 处理查询时,执行程序使用一些预先分配的内存区域,例如temp_buffers和work_mem,并在必要时创建临时文件。
此外,在访问元组时,PostgreSQL使用并发控制机制来维护正在运行的事务的一致性和隔离性。 并发控制机制在第5章中描述。
图3.6。 执行程序,缓冲区管理器和临时文件之间的关系。