




1. 基本信息
| 系统 | 版本 |
| 主机macos,m1pro芯片 | macOS Monterey 12.6.1 |
| 虚拟机pd | parallels desktop 18 for mac |
| 虚拟机上安装系统ubuntu22.04 | arm64架构的ubuntu22.04 |
2. 集群安排
因为hadoop集群至少要三个节点,所以我们需要三台虚拟机,每一台虚拟机上分别设置namenode、resourcemanager、secondarynamenode,保证集群的高可用性。配置如下:
| 主机名 | hadoop01 | hadoop02 | hadoop03 |
| HDFS | namenode、datanode | datanode | datanode、secondarynamenode |
| YARN | nodemanager | resourcemanager、nodemanager | nodemanager |
3. 安装虚拟机和操作系统
3.1 首先安装正版parallels desktop 18 for mac
链接:https://www.parallels.cn/products/desktop/
免费安装后会有14天试用期,如果有支持正版意愿和实力的小伙伴可以购买套餐,如果不想付费,那么可以去淘宝买激活码。
3.2 安装ubuntu22.04-arm64
打开pd18,并打开控制中心
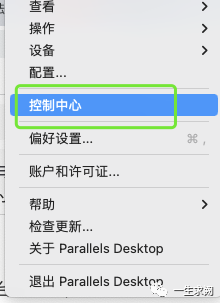
点击控制中心右上角的加号

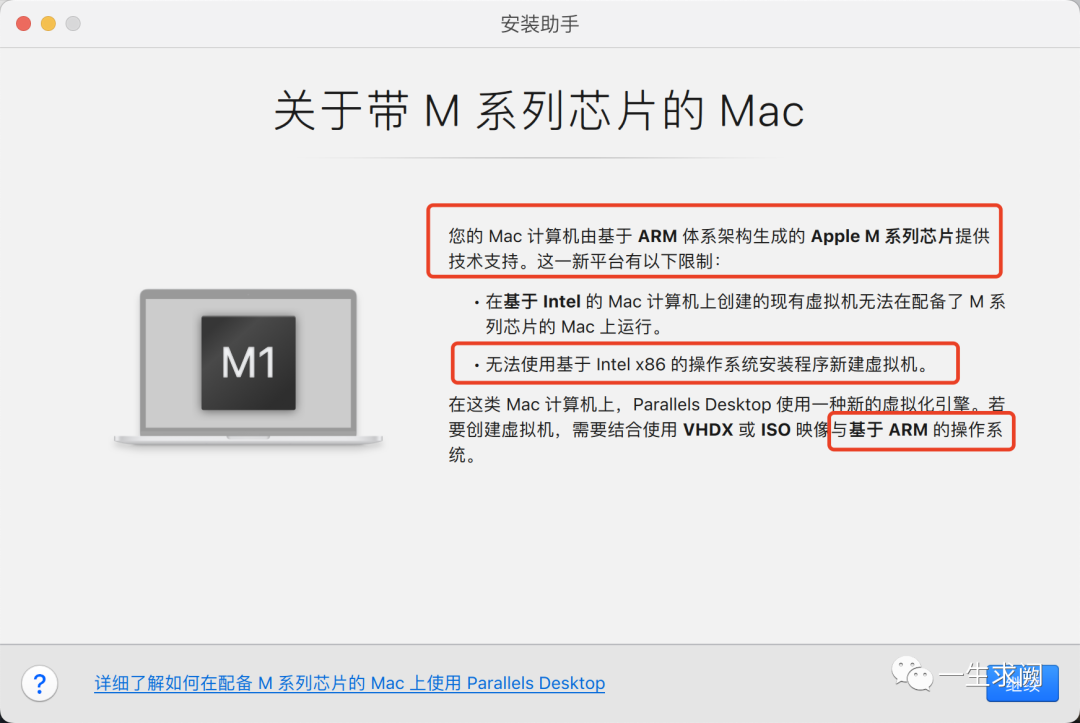
然后就看到这个,也就解释了为什么安装ubuntu一定要是arm架构的,点击继续按钮进入安装助手
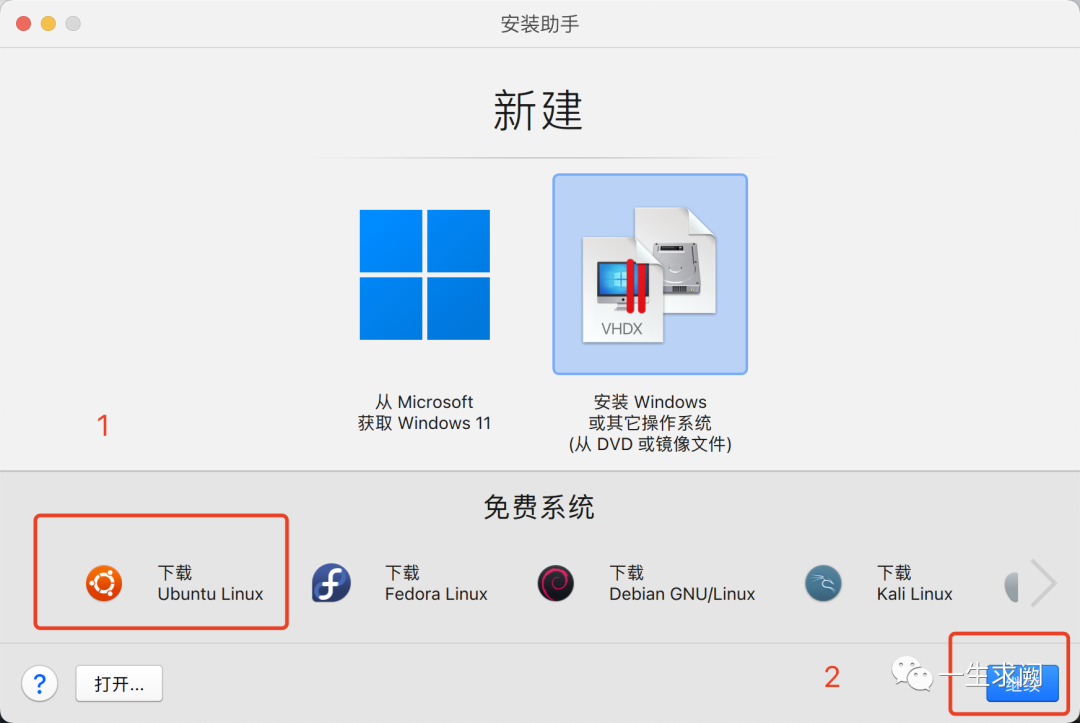
点击下载ubuntu linux,再点击继续
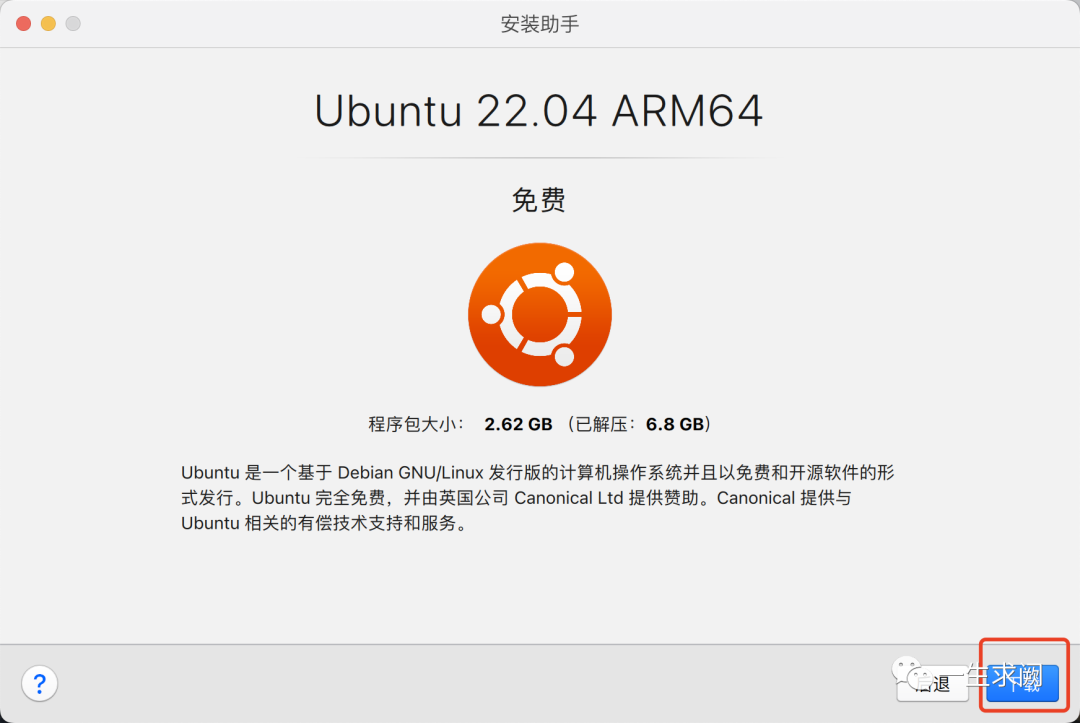
接着点击下载即可
当我们进入系统时是这样的,刚开始进去的时候会自动创建一个用户名,我这个是改过之后的,没改之前好像叫parallels,如何修改用户名呢
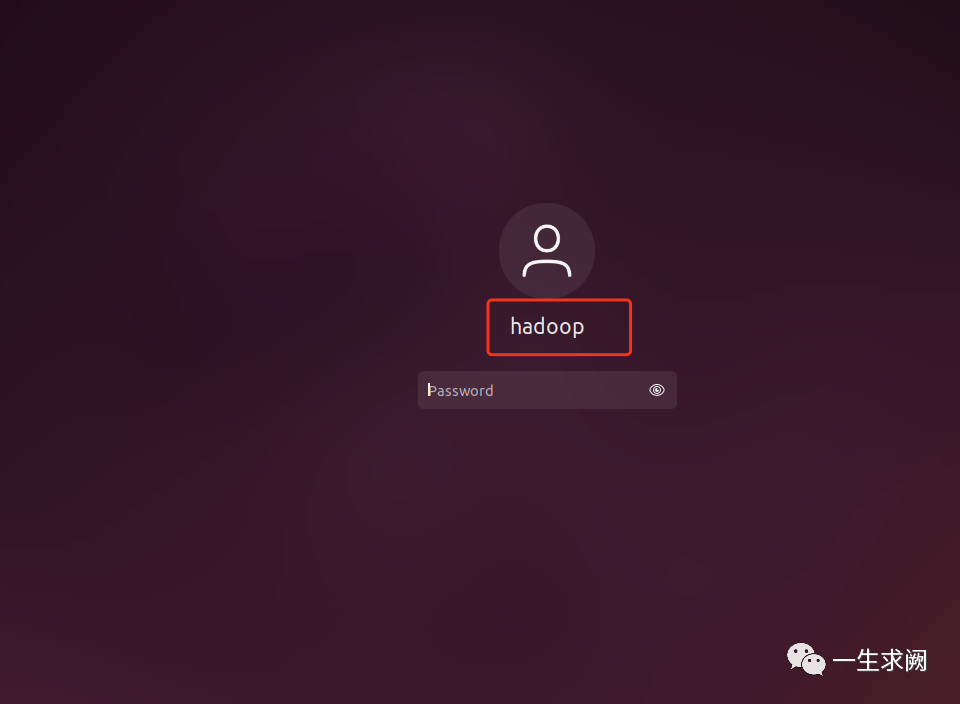
首先设置密码后进入系统,然后打开终端:
第一步:创建新用户名:
sudo adduser 新用户名
sudo adduser 新用户名 sudo
第二步:登录新用户名:
sudo 新用户名,会提示输入新用户名密码
第三步:重启系统进入系统,会看到新的和旧的两个用户名,登录新用户名
命令:reboot
第四步:删除旧的用户名
sudo deluser 老用户名 删除旧用户名
第五步:删除旧的home用户文件夹
sudo rm -rf home/旧用户
第六步:重启登录系统时旧的用户名没有了。
这个时候就改好了用户名,为了后面方便理解,后续需要用到用户名的地方,我统一采用我自己的用户名,大家记得改成自己的用户名
4. 克隆虚拟机&对每一台虚拟机进行配置
4.1 克隆虚拟机
我们已经安装了一台虚拟机,还需要两台,直接克隆两台虚拟机
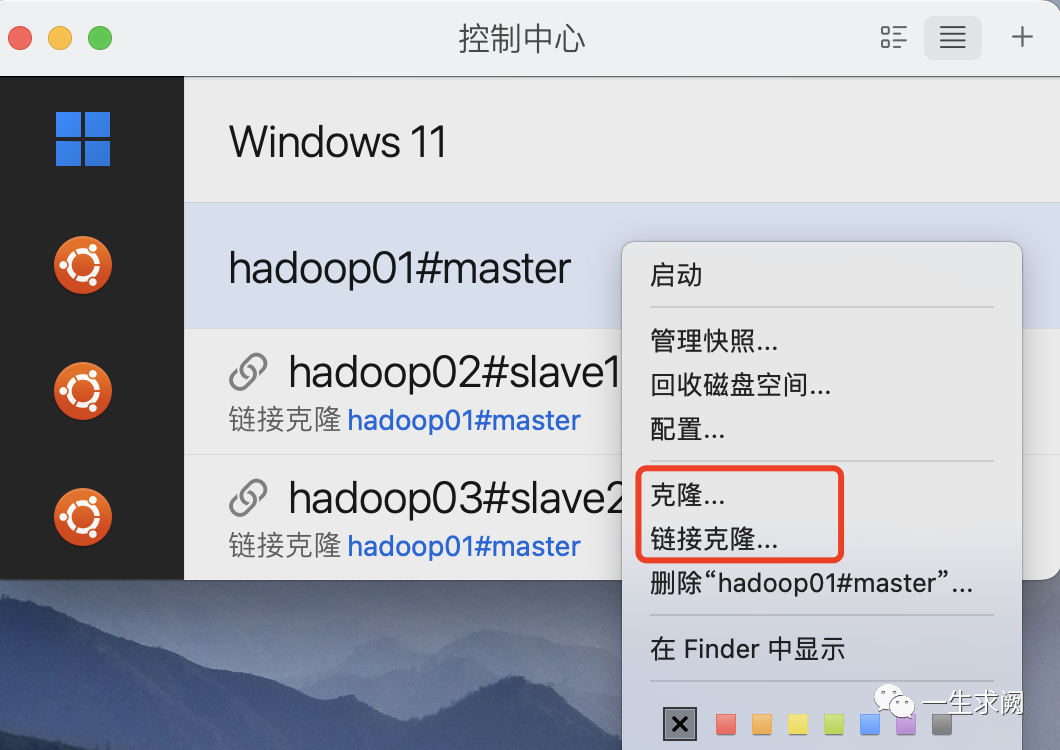
有两种克隆方法:克隆和链接克隆,克隆属于完整克隆,完全独立于原虚拟机的存在;链接克隆是指利用原虚拟机的快照创建而成,克隆速度快,节省了磁盘空间,但是克隆后的虚拟机性能会有所下降。
具体用哪一种看大家的电脑性能哈。
4.2 对每一台虚拟机进行主机名修改、配置静态ip、映射、配置ssh
(我是将主虚拟机名设置为hadoop01,从虚拟机名设置为hadoop02和hadoop03,但是记得,三台虚拟机的用户名都要是hadoop(对应你的用户名),如果不是,就改成一样的)
接下来的四步每一台虚拟机上都要操作,我以hadoop01主机为操作对象进行演示,hadoop02和hadoop03也都要操作下面的四步
4.2.1 主机名修改
hadoop@hadoop01:~$ hostname #先查看自己的主机名xxxhadoop@hadoop01:~$ sudo vim /etc/hostname #进入文件中将主机名修改为hadoop01[sudo] password for hadoop:如果提示没有vim,先安装一下:sudo apt-get install vim-gtkhadoop@hadoop01:~$ reboot #修改完后重启系统就生效了
4.2.2 配置静态ip
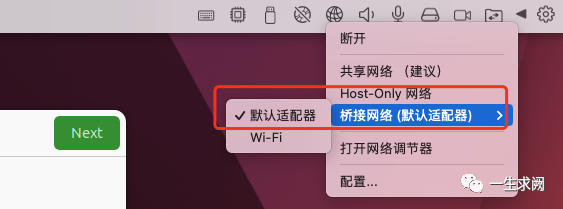
先将虚拟机的网络改成默认适配器
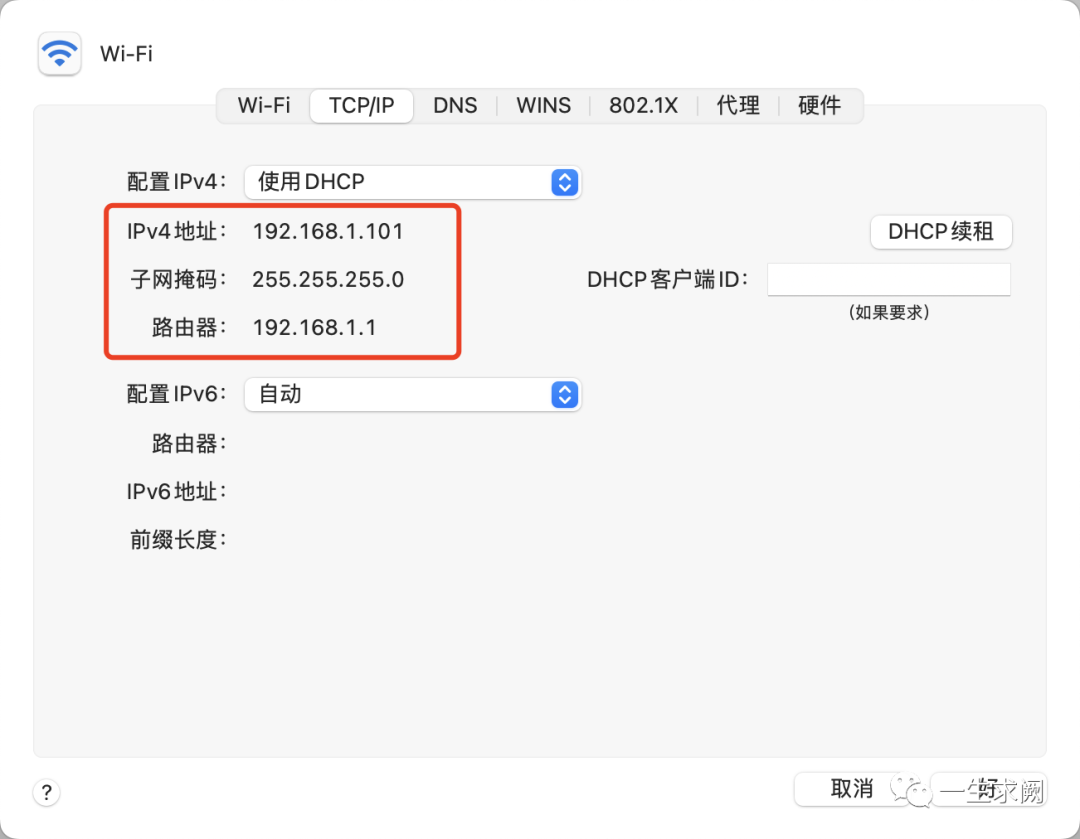
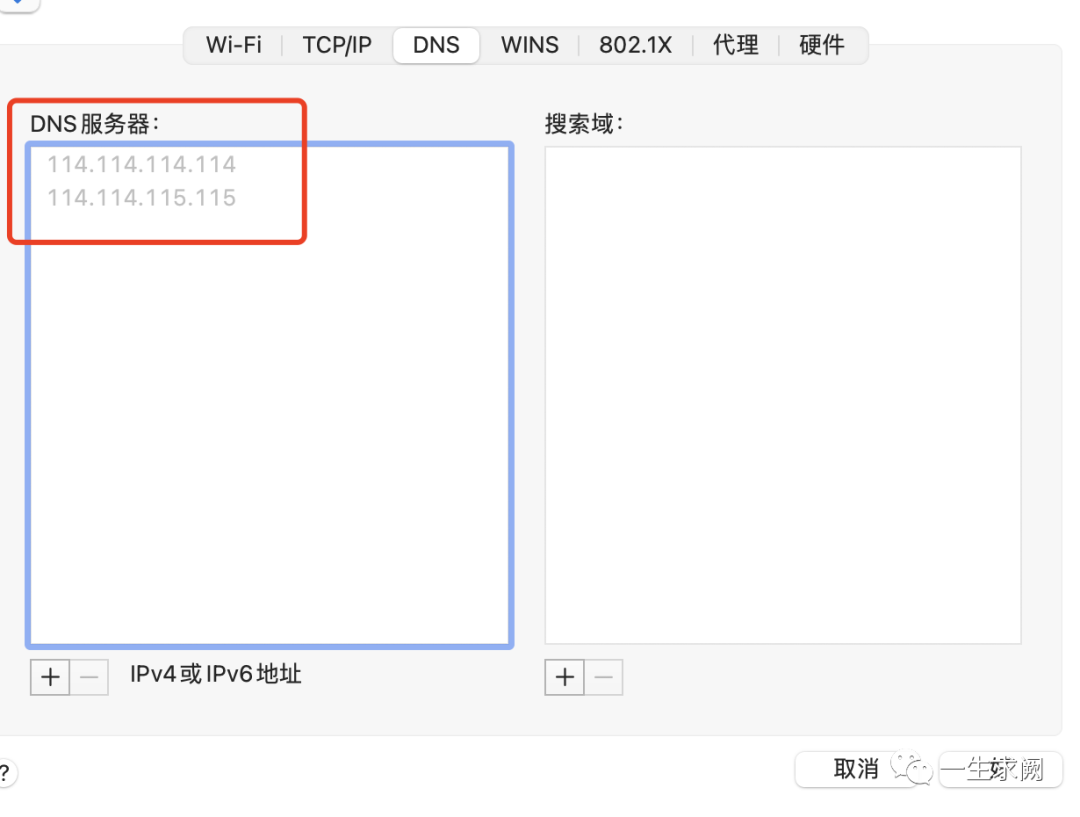
再查看自己mac电脑的ip地址,默认网关等信息:
系统偏好设置>>网络>>点击右下角的高级选项,分别记住以下这些内容
ubuntu18之后开始不采用在/etc/network/interfaces里进行固定ip的配置
而是在/etc/netplan/00-installer-config.yaml里进行配置
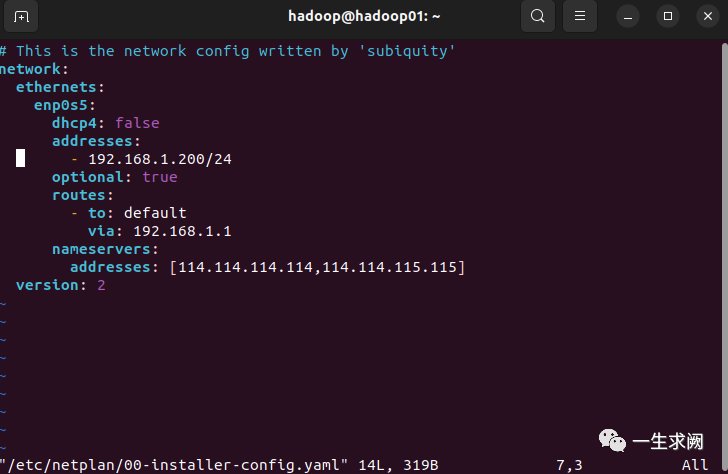
hadoop@hadoop01:~$ sudo vim /etc/netplan/00-installer-config.yaml
network:ethernets:enp0s5:dhcp4: false #改成falseaddresses:- 192.168.1.200/24 #将地址改成跟mac电脑的ip同网段即可optional: trueroutes:- to: defaultvia: 192.168.1.1 #将默认网关写成跟mac电脑一样的网关nameservers:#将mac电脑里的常用dns地址写上去addresses: [114.114.114.114,114.114.115.115]version: 2
这是写好之后的内容,注意格式,空格和缩进一定要注意,不然会报错!
之后重启(reboot )
看是否成功,通过ping一下外网看是否可以上网,能ping通就是可以了

4.2.3 更改虚拟机映射
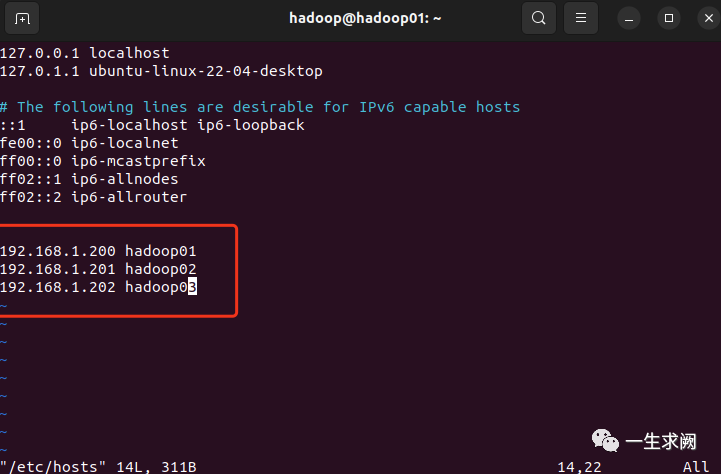
我的ip地址和主机名映射关系规划如下:
192.168.1.200 hadoop01
192.168.1.201 hadoop02
192.168.1.202 hadoop03
第一步:
hadoop@hadoop01:~$ sudo vim /etc/hosts#进入hosts文件中将三台虚拟机ip和主机名映射关系写上去
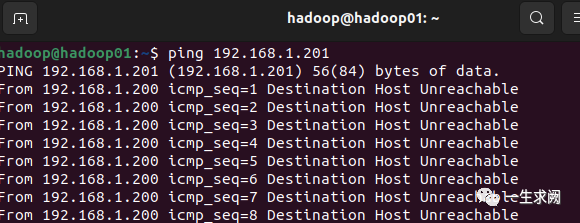
同样,分别ping一下其他主机看是否配置好,如下图:
4.2.4 配置ssh,免密登陆
首先在每个节点上都安装:
sudo apt-get install openssh-server
在hadoop01节点上:
hadoop@hadoop01:~$ ssh-keygen -t rsa#接下来连续按三个回车,生成密钥hadoop@hadoop01:~$ ssh-copy-id hadoop01#打yes,输入密码再重复如下:hadoop@hadoop01:~$ ssh-copy-id hadoop02hadoop@hadoop01:~$ ssh-copy-id hadoop03
之后检查是否可以免密码登录其他主机:
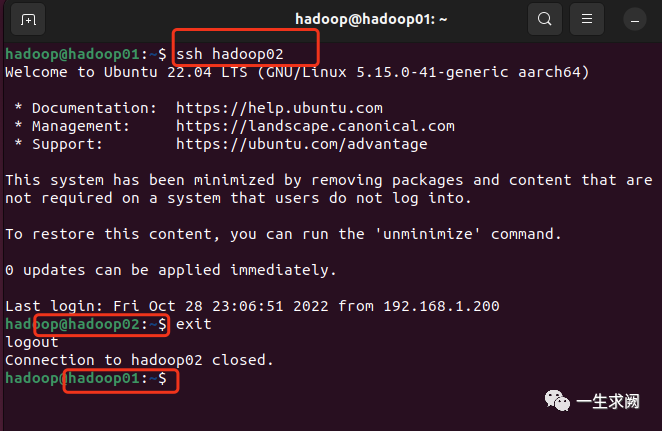
5. 安装jdk和hadoop并配置信息
5.1 安装jdk和hadoop&解压
jdk下载地址:https://www.oracle.com/java/technologies/downloads/#java8
(如果没有oracle账号,要注册一下)
Hadoop下载地址:https://hadoop.apache.org/release.html
我下的是这个:

在hadoop01上:
如果是在虚拟机firefox上下的jdk和hadoop,一般都是存在~/Downloads里,所以我们要执行如下操作:
将软件解压至安装目录:
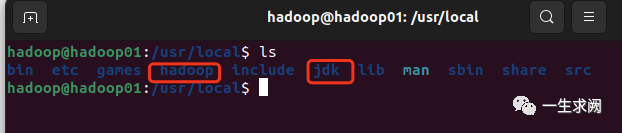
hadoop@hadoop01:~$ sudo tar -zxvf hadoop-3.2.1.tar.gz -C /usr/local #-C参数是指定解压到哪个目录下hadoop@hadoop01:~$ sudo tar -zxvf jdk-8u351-linux-aarch64.tar.gz -C /usr/localhadoop@hadoop01:~$ cd usr/localhadoop@hadoop01:~$ ls #应该可以看到解压的文件了#接着将两份文件名字分别hadoop和jdkhadoop@hadoop01:/usr/local$ sudo mv ./xxx(你的hadoop文件名) ./hadoophadoop@hadoop01:/usr/local$ sudo mv ./xxx(你的jdk文件名) ./jdk
改完之后就是这样的:
然后配置环境变量:
hadoop@hadoop01:~$ sudo vim ./.bashrc #分别在三台节点配置
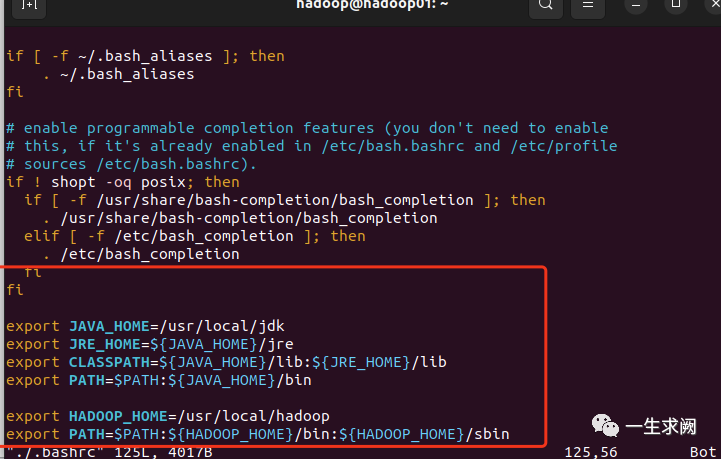
在里面加入如下内容:
export JAVA_HOME=/usr/local/jdkexport JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=$PATH:${JAVA_HOME}/binexport HADOOP_HOME=/usr/local/hadoopexport PATH=$PATH:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
之后:
hadoop@hadoop01:~$ source ./.bashrc #使环境变量生效,三台节点上都要
验证一下是否添加成功:

5.2 配置hadoop文件
在hadoop01上:
hadoop@hadoop01:~$ cd usr/local/hadoop/etc/hadoop
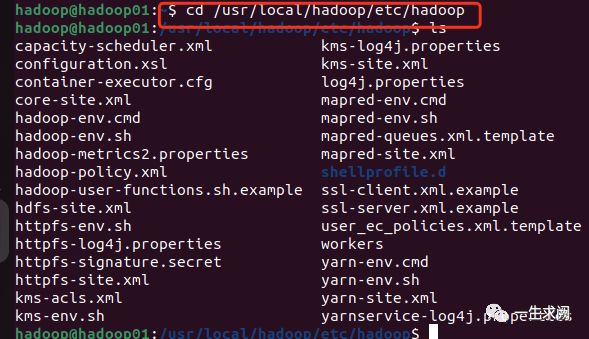
5.2.1 修改core-site.xml
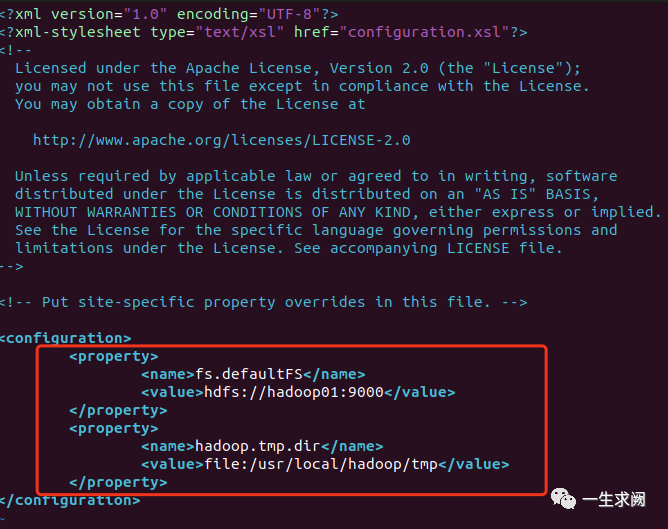
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim core-site.xml在文件里添加以下内容:<--!配置namenode位置--><property><name>fs.defaultFS</name><value>hdfs://hadoop01:9000</value></property><--!配置hadoop运行时文件存储的位置--><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value></property>
5.2.2 hdfs的配置文件
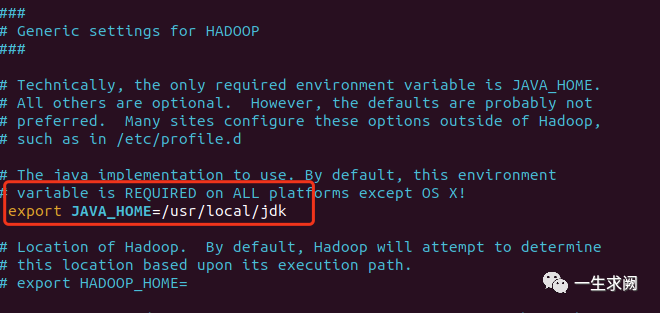
配置hadoop-env.sh
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim hadoop-env.sh在文件里添加如下内容:export JAVA_HOME=/usr/local/jdk
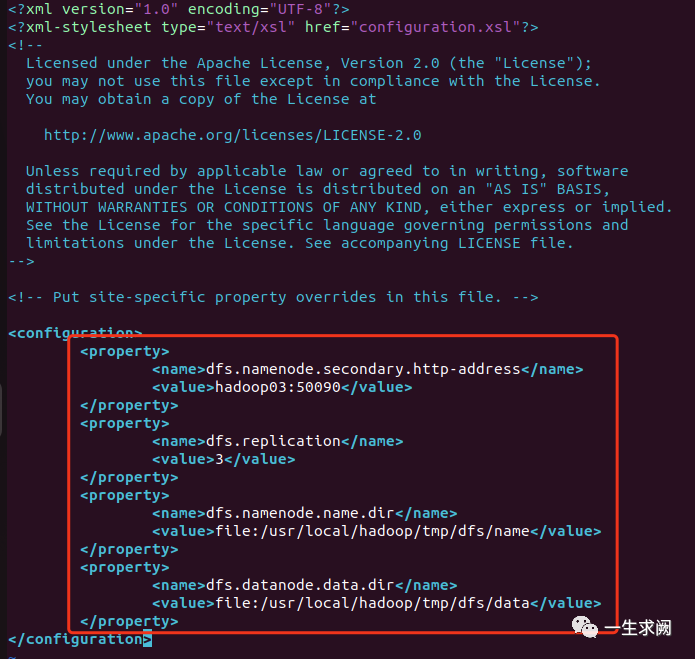
配置hdfs-site.xml
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim hdfs-site.xml在文件里添加如下内容:<!--指定sencodarynamenode地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop03:50090</value></property><!--指定hdfs保存的副本数量--><property><name>dfs.replication</name><value>3</value></property><!--其中/usr/local/hadoop/tmp这个路径是core-site里面设定的数据保存路径--><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property>
5.2.3 配置yarn文件
配置yarn-env.sh
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim yarn-env.sh在文件里添加如下内容:export JAVA_HOME=/usr/local/jdk
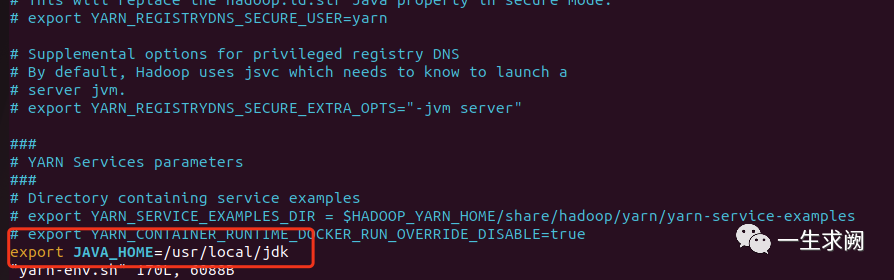
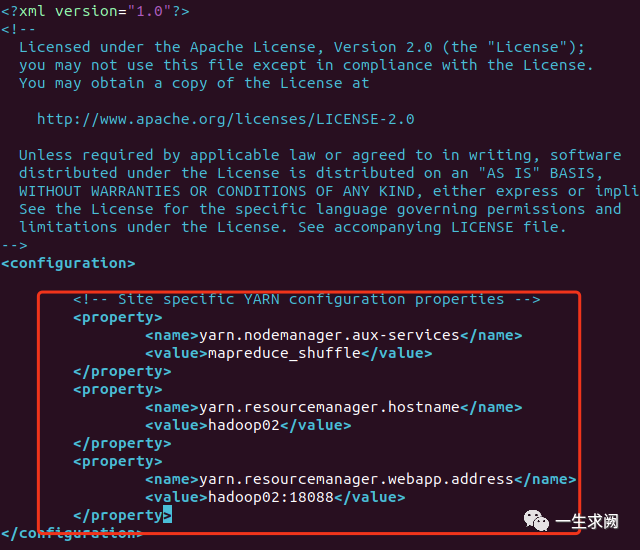
配置yarn-site.xml
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim yarn-site.xml在文件里添加如下内容:<!--获取数据方式为shuffle--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--指定resourcemanager的位置--><property><name>yarn.resourcemanager.hostname</name><value>hadoop02</value></property><!--指定resourcemanager对web页面曝光的访问地址--><property><name>yarn.resourcemanager.webapp.address</name><value>hadoop02:18088</value></property>
5.2.4 配置mapreduce文件
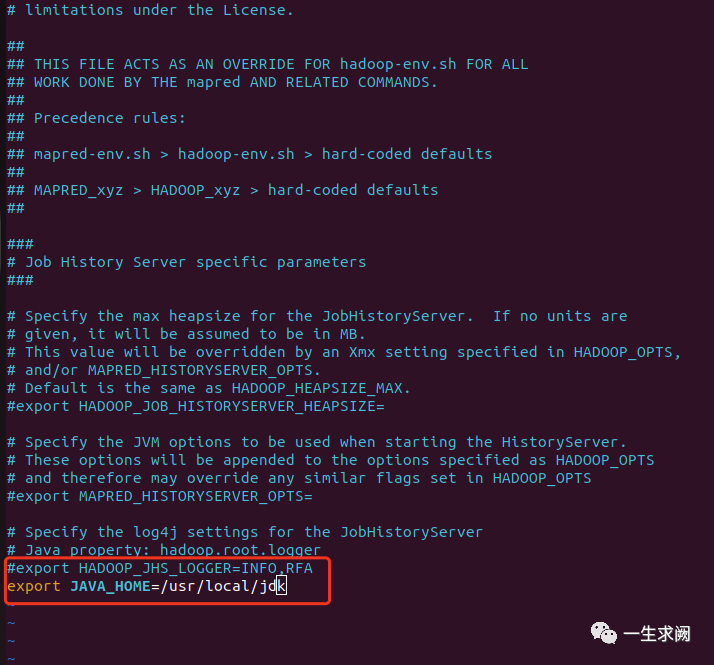
配置mapred-env.sh
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim mapred-env.sh在文件里添加如下内容:export JAVA_HOME=/usr/local/jdk
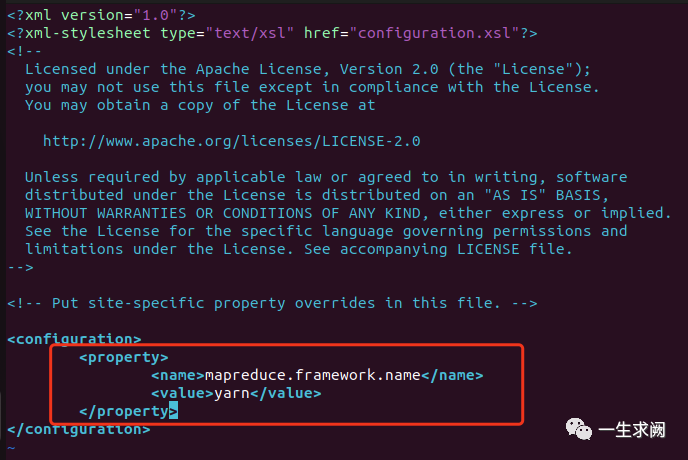
配置mapred-site.xml
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim mapred-site.xml在文件里添加如下内容:<!--指定mapreduce运行在yarn上--><property><name>mapreduce.framework.name</name><value>yarn</value></property>
5.2.5 配置workers文件(hadoop 3.x之前是叫slave,之后改成了workers)
hadoop@hadoop01:/usr/local/hadoop/etc/hadoop$ sudo vim workers在文件里添加如下内容:(将localhost删掉,只要配置有datanode的节点都写进去)hadoop01hadoop02hadoop03
5.3 复制文件
使用scp命令将hadoop01上的hadoop、jdk文件复制到hadoop02和hadoop03上:
在hadoop01上执行如下命令:sudo scp -r usr/local/hadoop hadoop@hadoop02:~/sudo scp -r /usr/local/hadoop hadoop@hadoop03:~/sudo scp -r usr/local/jdk hadoop@hadoop02:~/sudo scp -r /usr/local/jdk hadoop@hadoop03:~/此时文件已经复制到hadoop02和hadoop03对应的目录下了分别在hadoop02和hadoop03节点上执行下面命令sudo mv /home/hadoop/hadoop /usr/localsudo mv /home/hadoop/jdk /usr/localsource ./.bashrc 生效一下环境变量,每台节点都要执行。
6. 启动集群
在格式化namenode之前,要将各个节点上/usr/local/hadoop目录下的logs和tmp文件删除掉,如果这两个文件存在的话。
6.1 在hadoop01上格式化namenode
hadoop@hadoop01:~$ hdfs namenode -format
6.2 启动集群
在hadoop01上:start-dfs.sh在hadoop02上:start-yarn.sh
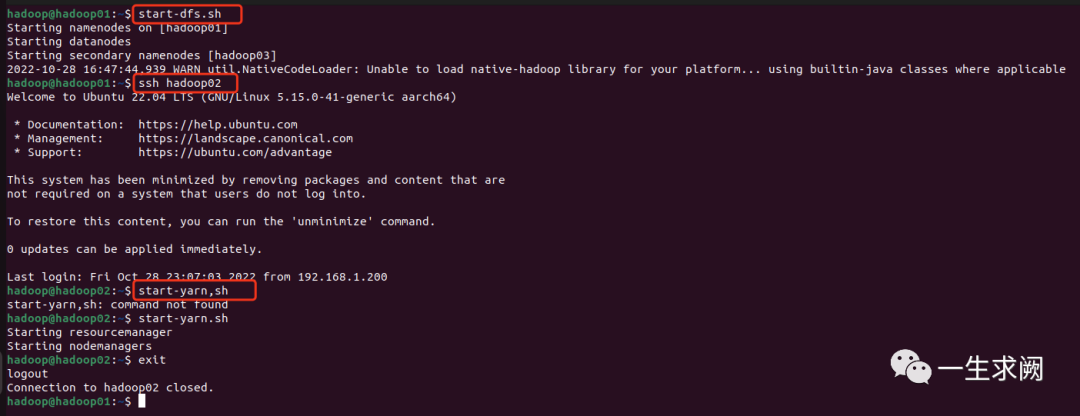
查看hadoop01节点上进程:
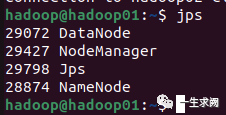
查看hadoop02节点上进程:
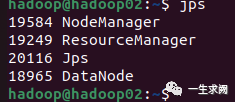
查看hadoop03节点上进程:
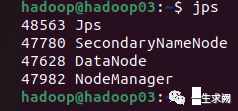
6.3 通过浏览器访问UI集群信息图
hadoop3.x浏览器管理页面的端口号由原来的50070改成了9870
http://192.168.1.200:9870/ #因为主节点配置在了hadoop01
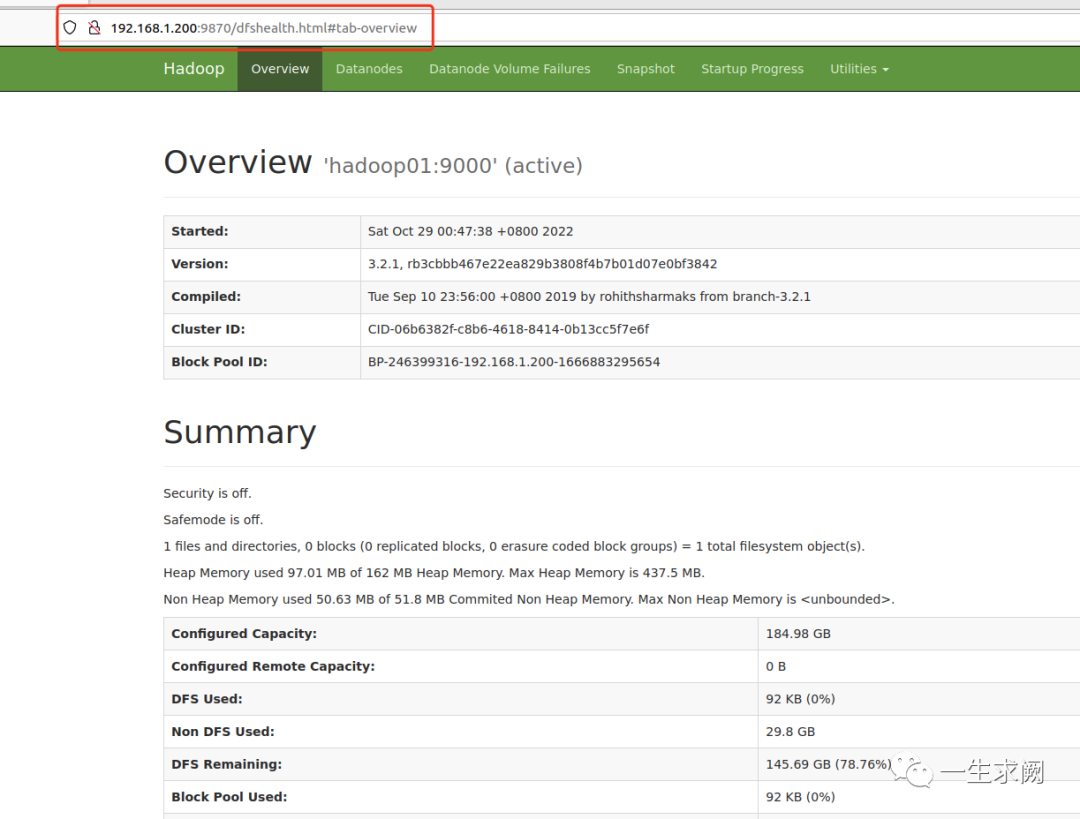
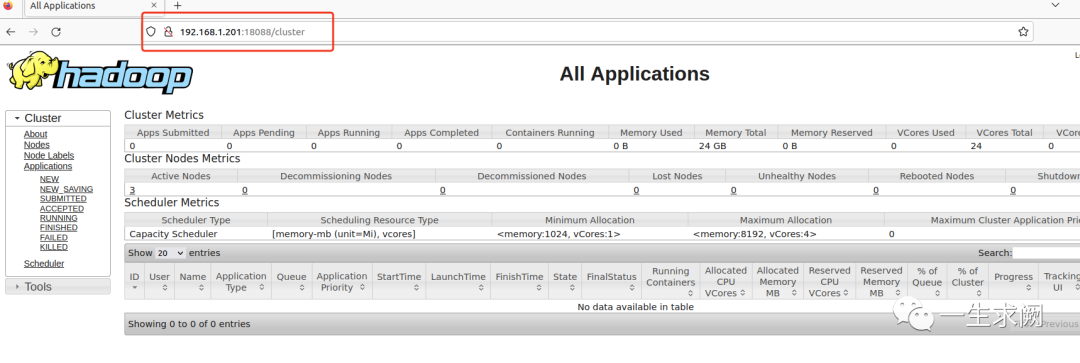
6.4 通过浏览器访问yarn web 信息图
http://192.168.1.201:18088 #因为将resourcemanager配置在了hadoop02上,且指定了固定端口
以上就是配置hadoop集群的整个过程,编写不易,大家的点赞是我前进的动力,有需要的话编者后续会出如何在hadoop集群上安装大数据组件(例如hive,spark,flink之类)的文章~~
