




ESS
为什么需要spark ESS?
在Spark中,Executor进程除了运行task,还要负责写shuffle 数据,以及给其他Executor提供shuffle数据。当Executor进程任务过重,导致GC而不能为其他Executor提供shuffle数据时,会影响任务运行。同时,ESS的存在也使得,即使executor挂掉或者回收,都不影响其shuffle数据,因此只有在ESS开启情况下才能开启动态调整executor数目。
因此,spark提供了external shuffle service这个接口,常见的就是spark on yarn中的,YarnShuffleService。这样,在yarn的nodemanager中会常驻一个externalShuffleService服务进程来为所有的executor服务,默认为7337端口。
其实在spark中shuffleClient有两种,一种是blockTransferService,另一种是externalShuffleClient。如果在ESS开启,那么externalShuffleClient用来fetch shuffle数据,而blockTransferService用于获取broadCast等其他BlockManager保存的数据。
如果ESS没有开启,那么spark就只能使用自己的blockTransferService来拉取所有数据,包括shuffle数据以及broadcast数据。
总之使用Spark ESS 为 Spark Shuffle 操作带来了以下好处:
即使 Spark Executor 正在经历 GC 停顿,Spark ESS 也可以为 Shuffle 块提供服务。
即使产生它们的 Spark Executor 挂了,Shuffle 块也能提供服务。
可以释放闲置的 Spark Executor 来节省集群的计算资源。
何为spark ESS ?
为了解耦数据计算和数据读取服务,Spark 支持单独的服务来处理读取请求。这个单独的服务叫做 ExternalShuffleService。该服务运行在每一个nodemanager节点上,而且是常驻的进程,用来管理该节点上每个executor 在shuffle writer过程中生成的中间数据。
因为之前是由多个 Executor 负责处理读取请求,而现在一台主机只有一个 ExternalShuffleService 处理请求,其实性能问题不必担心,因为它主要消耗磁盘和网络,而且采用的是异步读取,所以并不会有性能影响。
解耦之后,如果 Executor 在数据计算时不小心挂掉,也不会影响 shuffle 数据的读取。而且Spark 还可以实现动态分配,动态分配是指空闲的 Executor 可以及时释放掉。
我们可以理解为ESS负责管理shuffle write端生成的shuffle数据,ESS是和yarn一起使用的, 在yarn集群上的每一个nodemanager上面都运行一个ESS,是一个常驻进程。一个ESS管理每个nodemanager上所有的executor生成的shuffle数据。总而言之,ESS并不是分布式的组件,它的生命周期也不依赖于Executor。
如何使用spark ESS?
1. 在NodeManager中启动External shuffle Service。
a. 在“yarn-site.xml”中添加如下配置项:<property><name>yarn.nodemanager.aux-services</name><value>spark_shuffle</value></property><property><name>yarn.nodemanager.aux-services.spark_shuffle.class</name><value>org.apache.spark.network.yarn.YarnShuffleService</value></property><property><name>spark.shuffle.service.port</name><value>7337</value></property>配置参数描述yarn.nodemanag er.aux-services :NodeManager中一个长期运行的辅助服务,用于提升Shuffle 计算性能。yarn.nodemanag er.auxservices. spark_s huffle.class :NodeManager中辅助服务对应的类。spark.shuffle.ser vice.port :Shuffle服务监听数据获取请求的端口。可选配置,默认值 为“7337”。b. 添加依赖的jar包拷贝“${SPARK_HOME}/lib/spark-1.3.0-yarn-shuffle.jar”到“$ {HADOOP_HOME}/share/hadoop/yarn/lib/”目录下。c. 重启NodeManager进程,也就启动了External shuffle Service。
2. Spark应用使用External shuffle Service。
在“spark-defaults.conf”中必须添加如下配置项:spark.shuffle.service.enabled truespark.shuffle.service.port 7337说明1.如果1.如果“yarn.nodemanager.aux-services”配置项已存在,则在value中添加 “spark_shuffle”,且用逗号和其他值分开。2.“spark.shuffle.service.port”的值需要和上面“yarn-site.xml”中的值一样。配置参数描述spark.shuffle.ser vice.enabled :NodeManager中一个长期运行的辅助服务,用于提升Shuffle 计算性能。默认为false,表示不启用该功能。spark.shuffle.ser vice.port :Shuffle服务监听数据获取请求的端口。可选配置,默认值 为“7337”。

spark.shuffle.service.enabled - 定义ESS服务是否启用,启动服务该参数必须设为true。
spark.shuffle.service.port - 定义运行ESS shuffle 服务的端口,默认为7337。由于该服务应该与执行程序在同一节点上运行,因此配置中不存在主机。
spark.shuffle.service.index.cache.size- 确定缓存的大小。在开启ESS shuffle 服务情况下,用于缓存存储索引文件信息。它避免了每次获取块时打开/关闭这些文件。主要用于基于排序的 shuffle 数据。
spark ESS常见参数?
// 服务启动时处理请求的线程数,默认是服务器的cores * 2spark.shuffle.io.serverThreads// ChannelOption.SO_RCVBUF,spark.shuffle.io.receiveBuffer// ChannelOption.SO_BACKLOGspark.shuffle.io.backLog// ChannelOption.SO_SNDBUFspark.shuffle.io.sendBuffer
Spark ESS的挑战和不足?
脆弱的网络模型: 传统的shuffle要求mapper到reducer之间建立 all-to-all的网络模型,这种模型在大规模的集群里面会非常的不可靠性。大集群里面节点挂掉是很常见的事情,在高峰的时候shuffle service的负载会被shuffle操作打得很高,这个又进一步提高了shuffle网络连接出问题的概率。而中间任何网络问题会使得整个shuffle reduce stage失败,从而会对上一个stage进行重试以重新产生shuffle数据,这种重试代价是很大的。
低效的小文件IO: 落盘的shuffle数据是以一个个shuffle block存在的,LinkedIn内部统计shuffle block的大小通常在几十KB左右。而这些数据块后面被reducer访问的时候访问的方式是很随机的,而LinkedIn Shuffle 磁盘使用的是HDD,大量的小文件随机读对于HDD特别不友好,因为底层磁头要不停地寻址。而且因为Shuffle场景数据只会读一遍,因此操作系统内部的各种缓存也帮不上忙。有同学可能会说用SSD啊,SSD没有磁头会很快啊,确实会快,但是也贵啊,而且SSD在Shuffle这种数据只使用一次,快速写快速读,然后很快又删除的场景下,很容易坏掉。
没有Shuffle数据的Locality调度: 虽然现在网络带宽提升很大,但是由于底层使用HDD,我们很多时候是打不满网络带宽的,因为瓶颈首先在磁盘,因此让Reduce Task调度到离数据更近的节点还是有意义的,因为如果把reduce task调度到数据所在的那个节点,reduce task可以直接读取本地的shuffle数据,这一方面提高了性能,另外一方面也降低了整个shuffle操作所需要建立的网络连接数,提高稳定性。而这个是Magnet之前的Spark Shuffle机制做不到的,因为一个reduce所需要的shuffle数据是分布在各个不同的map task机器上的,你没有办法实现Data Locality的调度。
RSS
ESS:External Shuffle Service,ESS 原理是 Map 任务在计算节点本地将相同 Partition 数据合并到一起;
RSS:Remote Shuffle Service,RSS 原理是 Map 任务将相同 Partition 数据 Push 到远端的 RSS,RSS 将同一 Partition 的数据合并。
在云原生环境下,Spark需要将Shuffle数据写出到远程的服务中。但是我们经过调研后发现Spark 3.0(之前的master分支)只支持了部分的接口,而没有对应的实现。该接口主要希望在现有的Shuffle代码框架下,将数据写到远程服务中。如果基于这种方式实现,比如直接将Shuffle以流的方式写入到HDFS或者Alluxio等高速内存系统,会有相当大的性能开销。
所以各个大厂都在考虑从自身的角度,如何完美的把计算和数据传输真正切分开,这就诞生了在Spark基础上还需要再次优化shuffle的需求,那么一般大家怎么优化呢?
其实思路差不多,既然shuffle是用来做数据传输,传输的内容是Executor计算出放在data node上的临时文件,那么就在Executor写入临时文件的时候把它放到另外的地方去,读取的时候让其他节点从其他地方去读就好了。
这个其他地方就非常重要了,他需要解决高io,高并发,高性能,从而不影响整个程序进行,另外因为是其他地方,所以自然也就解决了K8S场景下,对磁盘和数据存储的诉求,可以极大的利用K8S的优势,进行无缝的融合了,完美解决Spark on Kubernetes方案中对于本地磁盘的依赖。
像阿里的Remote Shuffle Service,就是一个完整的缓存服务器:
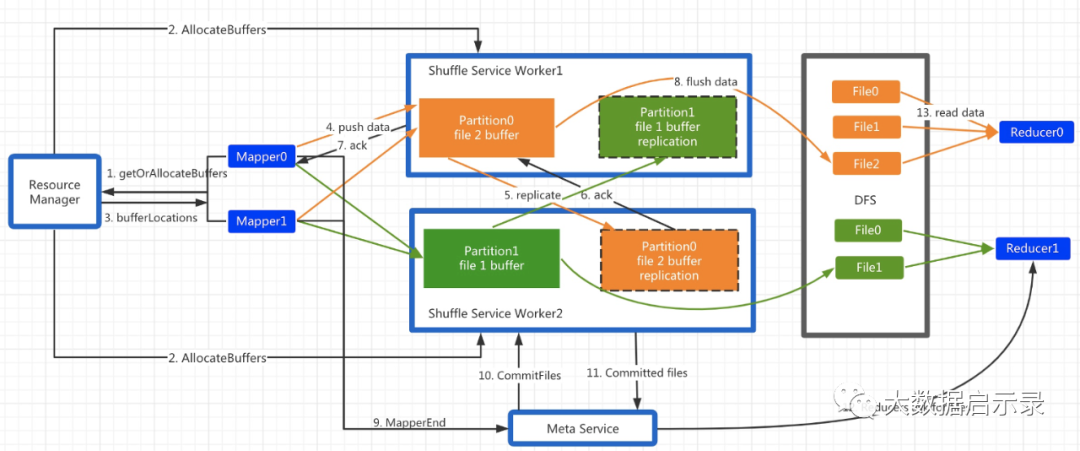
Spark RSS架构包含三个角色: Master, Worker, Client。Master和Worker构成服务端,Client以不侵入的方式集成到Spark ShuffleManager里(RssShuffleManager实现了ShuffleManager接口)。
实现流程是:
RSS采用Push Style的shuffle模式,每个Mapper持有一个按Partition分界的缓存区,Shuffle数据首先写入缓存区,每当某个Partition的缓存满了即触发PushData。
Driver先和Master发生StageStart的请求,Master接受到该RPC后,会分配对应的Worker Partition并返回给Driver,Shuffle Client得到这些元信息后,进行后续的推送数据。
Client开始向主副本推送数据。主副本Worker收到请求后,把数据缓存到本地内存,同时把该请求以Pipeline的方式转发给从副本,从而实现了2副本机制。
为了不阻塞PushData的请求,Worker收到PushData请求后会以纯异步的方式交由专有的线程池异步处理。根据该Data所属的Partition拷贝到事先分配的buffer里,若buffer满了则触发flush。RSS支持多种存储后端,包括DFS和Local。若后端是DFS,则主从副本只有一方会flush,依靠DFS的双副本保证容错;若后端是Local,则主从双方都会flush。
在所有的Mapper都结束后,Driver会触发StageEnd请求。Master接收到该RPC后,会向所有Worker发送CommitFiles请求,Worker收到后把属于该Stage buffer里的数据flush到存储层,close文件,并释放buffer。Master收到所有响应后,记录每个partition对应的文件列表。若CommitFiles请求失败,则Master标记此Stage为DataLost。
在Reduce阶段,reduce task首先向Master请求该Partition对应的文件列表,若返回码是DataLost,则触发Stage重算或直接abort作业。若返回正常,则直接读取文件数据。
总体来讲,RSS的设计要点总结为3个层面:
采用PushStyle的方式做shuffle,避免了本地存储,从而适应了计算存储分离架构。
按照reduce做聚合,避免了小文件随机读写和小数据量网络请求。
做了2副本,提高了系统稳定性。
spark rss常见优点?
所以一个好的RSS的方案必然从:
减少shuffle文件数量
减少读写磁盘的次数
这两方面来优化。
其实,RSS的优点还是很多的:
存储和计算分离
使计算节点和存储节点能够各司其职,而不是交汇在一起。现在的spark和yarn的架构其实还没有达到存储和计算分离的
动态资源分配
使用了RSS以后,任务完成以后,可以直接释放所占用的资源,而不是一直占用,直到shuffle文件不需要,这样能大大提高集群的资源利用率
能够很好的集成资源调度组件,如kubernetes
以后如果出现新的资源调度组件能够很方便的集成,代码级别几乎不需要修改
各家公司的RSS方案?
https://github.com/Tencent/Firestorm/blob/master/client-sparkhttps://github.com/alibaba/celeborn/blob/main/client-spark/shuffle-manager-3https://github.com/uber/RemoteShuffleService/tree/master/src/main/java/com/uber/rss/clientshttps://github.com/cubefs/shuttle/tree/master/src/main/java/com/oppo/shuttle/rss

