




随着移动设备技术的发展,人们产生的零碎时空数据越来越多。如何高效的存储并利用这些庞大的数据对于智慧交通等系统的研发是十分重要的。本篇文章带来由Hakan Ferhatosmanoglu教授团队发表在国际顶级的数据库会议VLDB 2021上的论文:《PPQ-Trajectory: Spatio-temporal Quantization for Querying in Large Trajectory Repositories》。

1.问题背景
现在定位装置和移动服务越来越普遍,因此产生的时空数据也越来越多。采用传统方法这些庞大、混乱的时空数据存储会占用很多的资源,而且不方便使用,所以需要将这些数据进行压缩处理后进行存储。
现在已有的数据压缩方法有许多不足:1)部分方法先将数据点映射到路网上再进行压缩,这降低了数据的准确性并且无法很好的反映轨迹的详细信息;2)目前广泛使用的压缩方式只支持离线处理;3)当进行查询的时候需要将压缩后的数据进行重构(解压缩),消耗计算资源。所以本文设计了时空数据量化器PPQ-trajectory所以本文设计了时空数据量化器PPQ来应对当前时空查询的需求。
什么是数据的量化呢?简单来说,就是将连续的数据集转换到简单的、有限的数据集合中。如图1,将数据空间中的四个点进行量化,得到右下表格结果。当数据点很多时,经过量化处理后最多也只有16个量化值来表示这个数据空间的所有数据点。这样就有效的减少数据存储占用的空间。
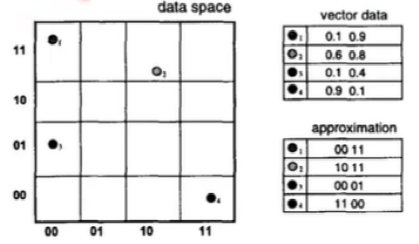
图1:数据量化
本文提出的PPQ-trajectory可以无需重构来回答查询而且具有高压缩度、高准确度,还能高效的进行数据更新。
2.基本框架
PPQ-trajectory由三部分组成。第一部分是分区预测量化器(PPQ),可以生成一个有界的误差概要,概要包含分区的码本(codebook)和该分区对应的预测系数。码本可以有效的记录误差,误差和预测系数相结合即可得到完整有效的路径信息。第二部分通过将PPQ的误差进行四叉树编码,用于准确的重构轨迹。这两个部分来生成轨迹数据的摘要。如图2所示。第三部分是基于时间分区的索引(TPI),在查询到来时,TPI可以生成一个候选轨迹列表,候选轨迹点可以通过轨迹数据的摘要来进行重构。PPQ-trajectory生成并且使用原始轨迹点的摘要来进行数据分析,可以处理简单的查询任务,也支持处理像轨迹预测之类的复杂的分析任务。
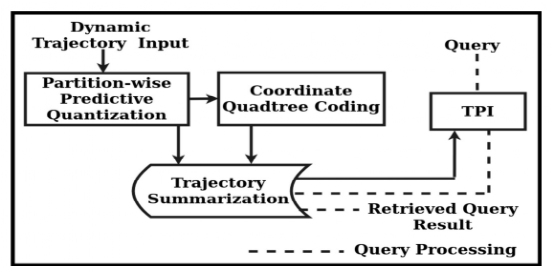
图2:PPQ-trajectory框架
3.PPQ-trajectory量化
现在已有的预测量化方法E-PQ可以很好的通过时间t的之前k个样本的误差进行一维数据流的量化。
为方便理解先介绍涉及到的三种不同含义的轨迹点:
(1) 真实轨迹点:未处理过的轨迹点
(2) 预测轨迹点:通过预测系数和之前的重构轨迹点计算得到的轨迹点
(3) 重构轨迹点:通过当前时间预测轨迹点加上误差得到的轨迹点
量化过程主要有三步,首先定义出预测方程f,使得当前真实轨迹点和预测函数计算的函数值距离最小,记录f中的每个点的预测系数P。之后用预测系数和当前时间之前的重构轨迹点计算出当前时间的预测轨迹点,计算出预测误差e。将误差记录在码本中,满足误差在当前码字所代表的范围内。如图3,每一个圈圈对应一个码字所能表示的误差范围,所有的码字构成码本。最后通过预测值和对应码字计算出重构轨迹点用于后续轨迹点的预测。
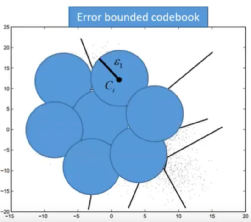
图3:误差空间
为了提高效率,PPQ-trajectory不仅仅采取上述方法,还将轨迹点进行分区,为每个分区选取一个独立的预测函数,这样可以更好的适应各种各样的轨迹点,而且误差的存储。如图4,轨迹点到f垂直距离为轨迹点的误差,可明显看出采用两个预测函数得到的误差种类少于只使用一个预测函数的E-PQ误差种类。这样可以减小码本C的大小,提高存储效率。
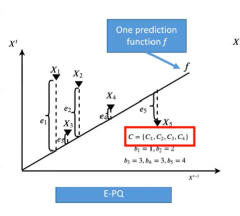
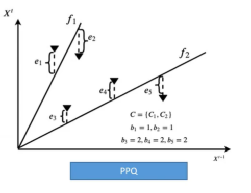
图4:预测函数数量效果对比
那么如何选取预测函数呢?正如地理学第一定律所说:“任何事物都是与其他事物相关的,只不过相近的事物关联更紧密”,主要利用轨迹点的相似性,分为空间相似和自相关相似两种方式。简单来说空间相似就是将一个范围临近的点划分为一个分区。自相关性就是利用当前轨迹点和前段时间的轨迹点之间的关系,如图5,给出两种分区方式的一个简单示例。每个分区内的点到分区中心要小于分区的阈值,保证分区内点的相似程度
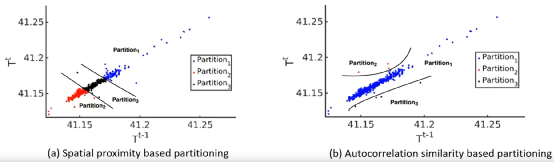
图5:空间相似性分区和自相似性分区
这两种预测函数对应的分区方式在不同的情况下各有自己的优势,但相比之下自相似性的适用性更强一些。
对于数据分区的更新,PPQ-trajectory采用时间增量分区,每次更新有以下三个步骤:
(1) 将t时间轨迹分区复制到t+1时间
(2) 当t+1分区点不满足分区阈值时,将t+1中新的轨迹点进行分区,知道全部满足阈值
(3) 检查合并,如果两个分区中心点的距离足够小,则将二者合并,为了保证分区准确性,每个分区只能合并一次。
这样分区避免了每次更新数据都进行重新分区,减少时间开销。
4.有限误差码本编码
图3中展示了码字所代表误差的范围,但是仅仅依靠这个范围不足以将轨迹准确展示和重构。我们将这个范围进行进一步的划分编码如图6所示。我们在此采取四叉树编码方式。
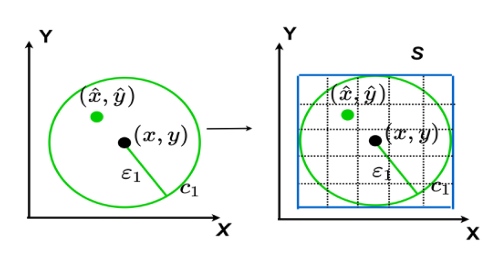
图6:误差空间中真实轨迹点和重轨迹点示例
我们将范围先补充为一个矩形,按照设定的小格边长g进行划分。划分后进行扩展,扩展为四个等分的正方形,如图7a。之后对于每个小正方形进行同样操作。每一条边记录父节点对应的象限编码。根节点上记录扩展前顶点位置坐标。我们可以很快的计算出图中点的大概位置,将每一个节点的坐标通过下面公式进行扩展后相加在除以2即可得到,如图7中绿色的点,位置为(-3/2, 1/2)。这样可以保证,重构轨迹点和真实轨迹点偏差不超过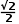 g,数据分析时可以接受这个微小的偏差。
g,数据分析时可以接受这个微小的偏差。
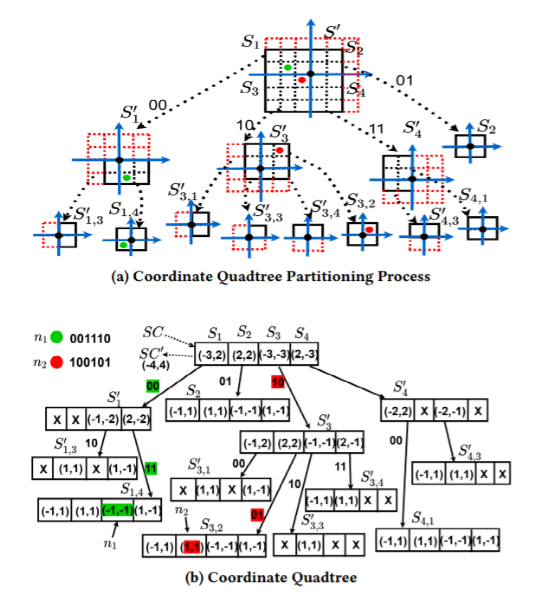
图7:四叉树编码过程
5.时间分区索引(TPI)
为了高效的对应一个时间段,我们构建分区索引(PI)。首先划分分区,类似于前面提到的相似分区方式。然后找到最小矩形来覆盖分区内的点如图8(a),可能会有重叠部分。最后将重叠的区域划分为小矩形。记录下轨迹点情况。
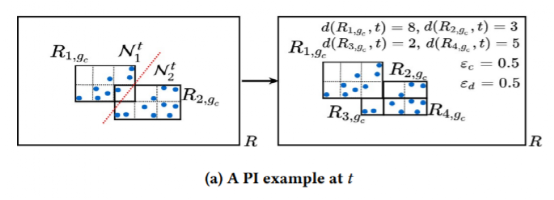
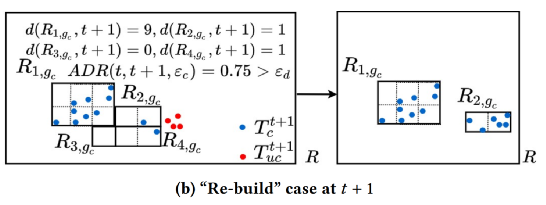
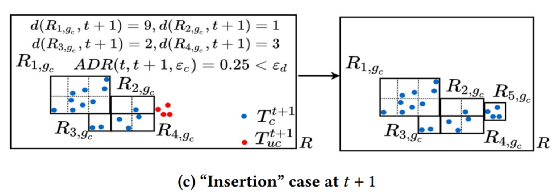
图8:TPI构建过程
后续时间在原有的基础上进行“Re-build”或者“Insertion”操作,计算出新增点的区域密度,如果平均密度下降超过阈值(自己设定),就将其进行“Re-build” ,如图8(b),若没超过则“Insertion”,如图8(c)
TPI是怎样回答查询呢?此处介绍时空范围查询和轨迹查询两种比较常见的查询方式,先按照时间,找到相应的PI,再通过PI中每个小格内存储的轨迹信息来回答时空范围查询。将时空范围查询的信息进行组合即可得到轨迹查询的结果,过程如图9所示。这样即可在不用重构的情况下来回答查询,更加高效快速。
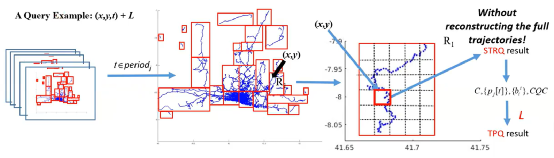
图9:回答查询过程
6.实验评估
本文选用Porto数据集和GecLife数据集来进行测试,并且对比了Product Quantization、Residual Quantization、REST、TrajStore方法。主要对比了压缩率,各种参数下的准确度,以及构建时所花费的时间。
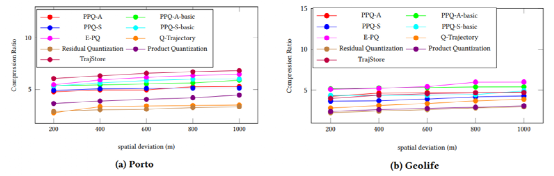 图10:各种方式压缩率对比
图10:各种方式压缩率对比
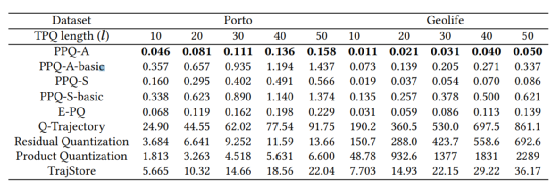
表1:不同轨迹长度(TPQ)时重构轨迹点和真实轨迹点误差平均误差对比
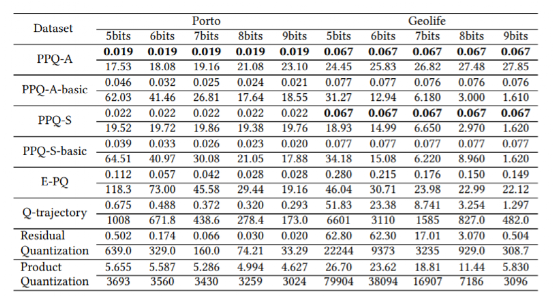
表2:码字大小不同时重构轨迹点和真实轨迹点平均误差对比
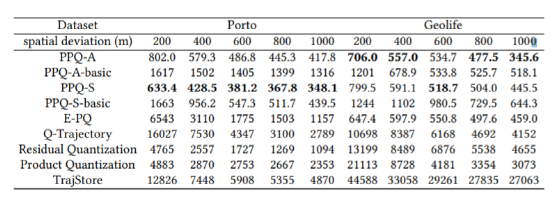
表3:构建摘要时间对比
通过实验我们可以看出,PPQ-trajectory有着高压缩率,高准确度的特性,而且本身就可以支持不重构来回答查询的特性。它为大规模的轨迹数据分析生成和维护一个有限误差的摘要,来满足现在时空数据查询的需求。未来可以基于量化的方法来考虑动态交通状况,并且利用机器学习更准确地预测轨迹点并生成更简洁的摘要。
参考文献:
[1]Kevin Gourley and Douglas Green. 1983. A polygon-to-rectangle conversion algorithm. IEEE Computer Graphics and Applications 1 (1983), 31–36.
[2] Yan Zhao, Shuo Shang, Yu Wang, Bolong Zheng, Quoc Viet Hung Nguyen, and Kai Zheng. 2018. Rest: A reference-based framework for spatio-temporal trajectory compression. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 2797–2806.
[3] Yongjian Chen, Tao Guan, and Cheng Wang. 2010. Approximate nearest neighbor search by residual vector quantization. Sensors 10, 12 (2010), 11259–11273.
[4] Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence 33, 1 (2010), 117–128.
[5] Philippe Cudre-Mauroux, Eugene Wu, and Samuel Madden. 2010. Trajstore: An adaptive storage system for very large trajectory data sets. In 2010 IEEE 26th International Conference on Data Engineering (ICDE 2010). IEEE, 109–120.

