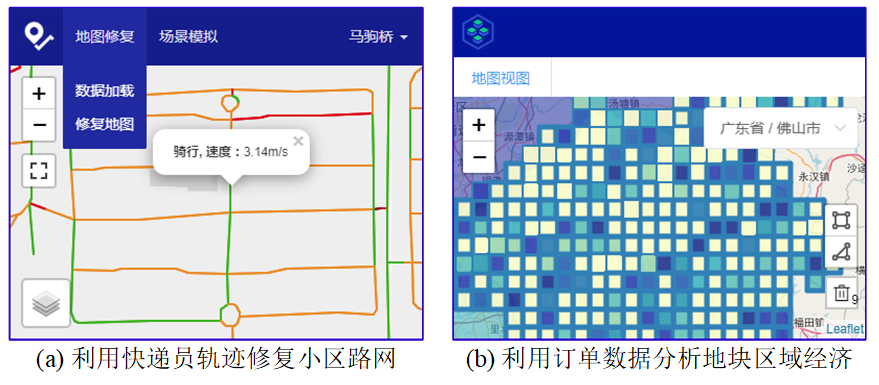
传统关系型数据库的空间扩展,例如Oracle Spatial、MySQL Spatial以及PostGIS,能够高效支持时空数据查询,但是当数据量特别大的时候,它们通常难以奏效。过去十几年,涌现了很多大数据存储和处理的框架,例如Apache Hadoop和ApacheSpark。基于Hadoop的分布式时空数据管理系统[2-5]仍然面临着效率问题,因为Hadoop将它们的中间结果存储到磁盘中,即使对于单个作业,也会触发多次磁盘读写。Spark将数据以RDD(Resilient Distributed Dataset)的形式缓存在内存中,因此相较于Hadoop,它的效率更高。大多数基于Spark的时空数据管理系统[6-11]在内存中构建了很大的空间索引,例如R-tree、KD-tree或者grid索引,因此能够高效支持时空数据管理。然而,这些系统需要先把数据加载到内存,然后构建索引,因此需要内存充足的高性能集群,故它们的扩展性是受限的。第二,当时空查询到来时,它们可能需要扫描很大的时空索引,通常比较耗时。第三,大多数基于Hadoop或者Spark的系统对数据更新不友好,因为它们构建的时空索引包含了不同记录之间的关系,如果有新的数据到来时,它们通常需要调整甚至重建索引,以保持一个良好的查询性能。第四,Hadoop和Spark主要面向于数据处理,因此基于它们构建的时空数据管理系统难以有效地支持高并发查询。分布式NoSQL(Not Only SQL)数据库,例如HBase能够高效支持百万级别的数据插入和更新。然而,由于缺乏二级索引,这些NoSQL数据库原生不支持时空数据的管理。基于NoSQL,涌现了很多时空数据管理系统[12-16]。例如,开源索引工具GeoMesa[12]能够将多维数据转化成一维数据,因此,它能够基于分布式NoSQL数据库管理大规模的时空数据。然而,这些系统主要面向的是数据存储,它们大多数未提供时空数据处理的方法或者SQL语言,因此,要使用这些系统的门槛较高,因为我们需要深究它们的开发手册,实现我们自己的时空数据分析算法。
JUST的特点
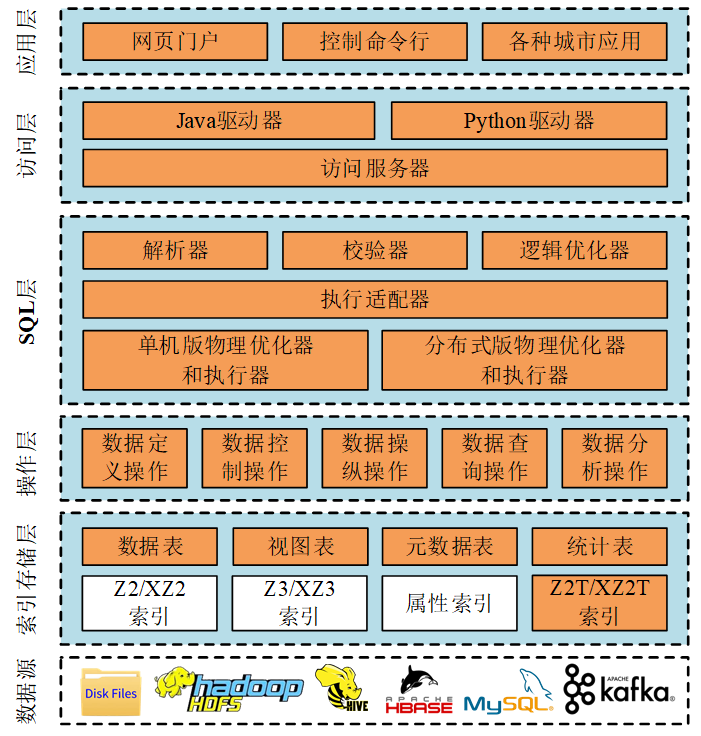
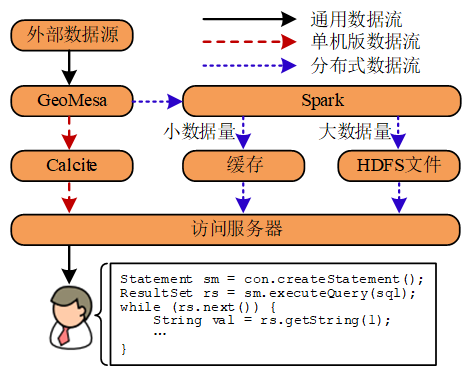
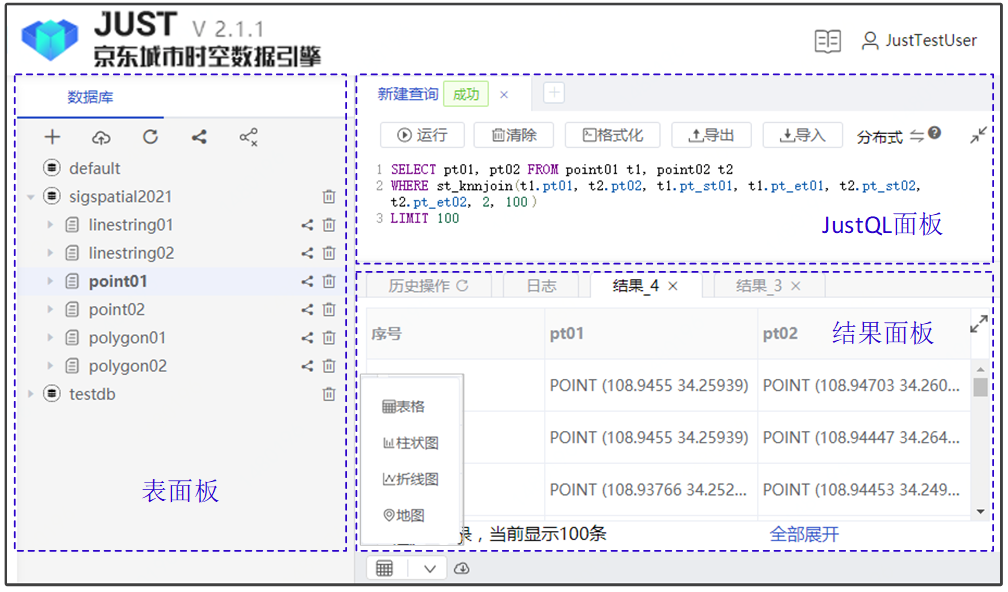
京东智能城市时空数据组实现了第一个完整的时空数据管理系统JUST(JD Urban Spatio-Temporal data engine)[17],能够便捷、高效地管理海量的时空数据。目前,JUST处在快速迭代中,新的功能和特性在不断地加入。本文基于2021年6月份发版的JUSTV2.1.2,该版本拥有很多显著的特点:(1)统一的。为了支持快速和高并发的时空数据查询,JUST实现了一个单机版执行引擎;为了支持高效可扩展的时空数据挖掘,JUST无缝集成了一个分布式执行引擎。JUST提供了一套统一的执行接口,并能够智能地为用户选择合适的执行引擎。(2)高可扩展的。JUST采用HBase作为底层的存储引擎,GeoMesa作为索引工具,Spark作为分布式的执行引擎。因此,JUST能够利用有限的集群资源管理海量的时空数据。(3)高效的。我们发现原生的GeoMesa提供的索引不大适合时空范围查询,因此,我们设计了两个新的索引,即Z2T和XZ2T[17],能够极大地提升查询效率。针对一种最通用的时空数据类型——轨迹,我们设计了一种新的存储机制[18][19],减少了存储开销的同时,加快了查询效率;(4)便于数据更新。时空信息编码到了HBase的键中,不同记录的键之间没有关系,因此JUST支持新数据的写入和历史数据的更新,而无需牺牲已有的索引性能。(5)易于使用的。我们设计并实现了一个完整的SQL引擎,预置了很多时空优化规则以及开箱即用的时空分析函数,所有的操作都可以通过一句标准的SQL语句来实现。
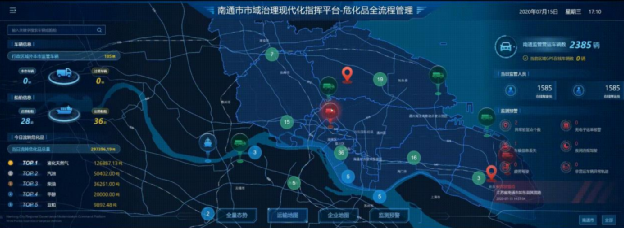
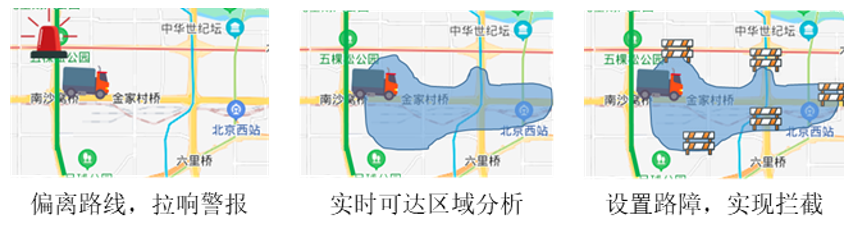
JUST作为一个PaaS(Platform as a Service)对外提供服务。基于JUST,已经落地了许多智能城市项目,包括雄安块数据平台、南通市域治理现代化平台、江苏园博园等。本文以南通市域治理现代化平台中的危化品监管应用举例,说明JUST是如何帮助快速构建智能城市应用的。图5展示了危化品监管系统的界面。图5 基于JUST的危化品监管系统在2020年6月13日,浙江温岭发生了一场严重的危化品爆炸事故,造成了20多人的死亡,170多人的受伤。因此,对危化品的监管事关人民的生命财产安全,受到了政府部门的极大关注。JUST目前在危化品监管上主要做了两件事情:1)危化品车辆是否按照了报备的路线行驶?因为如果危化品车辆闯入了居民区,会造成严重的安全威胁;2)是否存在非法的化工厂?比如,有些居民可能会将自己的住房腾出来,用来存储、生产化工用品,我们称之为“黑化工”,另外,一些不符合要求的化工厂,被政府勒令关停后,还可能偷偷进行生产。对危化品的监管是非常困难的,以南通为例,危化品监管涉及到6个环节、7个要素,需要9个不同的政府部门协同、12个软件系统的联动,而南通共有2000多家危化品企业、3000多辆危化品车辆、1000多艘船舶,一线的危化品监管人员只有20多人,如果只是通过人工进行排查,是非常困难的。JUST部署到了南通后,很好地解决了上述两个问题。JUST实时接入了危化品车辆的轨迹数据。针对第一个问题,JUST利用预置的轨迹地图匹配算法,一旦发现某辆危化品车辆偏离了原来报备的路线,就会实时拉响警报;同时,利用预置的实时可达区域分析算法[20],快速分析出这辆危化品车辆在当前交通状况下未来15分钟内能够到达的区域范围,结合路网信息,推荐交警部门设置路障的位置,对该车辆进行拦截,防止其驶入居民区,对社会安全造成威胁。针对第二个问题,我们对危化品车辆的GPS点轨迹信息进行分析,找到它们经常停留的地点,再结合POI分布信息,如果发现某些停留的地点周围没有危化品工厂,或者是已经关停的危化品工厂,那么这些停留的地方很有可能存在非法化工厂。我们把这些位置推荐给监管部门,他们再在实地进行核实。
[1]S. Ruan, C. Long, J. Bao, C. Li, Z. Yu, R. Li, Y. Liang, T. He, and Y. Zheng, “Learning to generate maps from trajectories,” in AAAI, 2020.[2]L. Alarabi, M. F. Mokbel, and M. Musleh, “St-hadoop: A mapreduce framework for spatio-temporal data,” GeoInformatica, vol. 22, no. 4, pp. 785–813, 2018.[3]A. Eldawy and M. F. Mokbel, “Spatialhadoop: A mapreduce framework for spatial data,” in ICDE. IEEE, 2015, pp. 1352–1363.[4]A. Eldawy, L. Alarabi, and M. F. Mokbel, “Spatial partitioning techniques in spatialhadoop,” VLDB, vol. 8, no. 12, pp. 1602–1605, 2015.[5]A. Aji, F. Wang, H. Vo, R. Lee, Q. Liu, X. Zhang, and J. Saltz, “Hadoop gis: a high performance spatial data warehousing system over mapreduce,” VLDB, vol. 6, no. 11, pp. 1009–1020, 2013.[6]J. Yu, J. Wu, and M. Sarwat, “A demonstration of geospark: A cluster computing framework for processing big spatial data,” in ICDE. IEEE, 2016, pp. 1410–1413.[7]J. Yu and J. Wu, “Geospark: A cluster computing framework for processing large-scale spatial data,” in SIGSPATIAL. ACM, 2015, p. 70.[8]M. Tang, Y. Yu, Q. M. Malluhi, M. Ouzzani, and W. G. Aref, “Locationspark: A distributed in-memory data management system for big spatial data,” VLDB, vol. 9, no. 13, pp. 1565–1568, 2016.[9]F. Baig, H. Vo, T. Kurc, J. Saltz, and F. Wang, “Sparkgis: Resource aware efficient in-memory spatial query processing,” in SIGSPATIAL. ACM, 2017, p. 28.[10]S. Hagedorn, P. Gotze, and K.-U. Sattler, “The stark framework for spatio-temporal data analytics on spark,” BTW, 2017.[11]D. Xie, F. Li, B. Yao, G. Li, L. Zhou, and M. Guo, “Simba: Efficient in-memory spatial analytics,” in SIGMOD. ACM, 2016, pp. 1071–1085.[12]“Geomesa,” https://www.geomesa.org/, 2021.[13]S. Nishimura, S. Das, D. Agrawal, and A. El Abbadi, “Md-hbase: A scalable multi-dimensional data infrastructure for location aware services,” in MDM, vol. 1. IEEE, 2011, pp. 7–16.[14]J. K. Nidzwetzki and R. H. Guting, “Bboxdb-a scalable data store ¨ for multi-dimensional big data,” in CIKM. ACM, 2018, pp. 1867–1870.[15]N. Du, J. Zhan, M. Zhao, D. Xiao, and Y. Xie, “Spatio-temporal data index model of moving objects on fixed networks using hbase,” in CICT. IEEE, 2015, pp. 247–251.[16]X. Tang, B. Han, and H. Chen, “A hybrid index for multi-dimensional query in hbase,” in CCIS. IEEE, 2016, pp. 332–336.[17]Li R, He H, Wang R, et al. Just: Jd urban spatio-temporal data engine[C]//2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020: 1558-1569.[18]Li R, He H, Wang R, et al. Trajmesa: A distributed nosql storage engine for big trajectory data[C]//2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 2020: 2002-2005.[19]Li R, He H, Wang R, et al. TrajMesa: A Distributed NoSQL-Based Trajectory Data Management System[J]. IEEE Transactions on Knowledge and Data Engineering, 2021.[20]Li R, Bao J, He H, et al. Discovering Real-Time Reachable Area Using Trajectory Connections[C]//International Conference on Database Systems for Advanced Applications. Springer, Cham, 2020: 36-53.