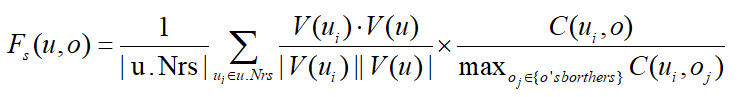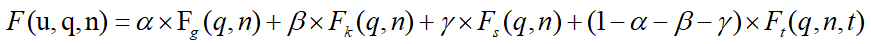随着社交媒体的蓬勃发展和地理定位技术的进步,基于位置的社交网络(LBSNs)近年来不断发展。LBSN服务中有着大量包括空间位置、文本、签到信息和社会关系的数据。由于用户更倾向于去那些朋友推荐的或者是相似爱好的用户去的地方,所以用户访问的场所可能会进一步受到他们的社会关系的影响。此外,根据用户的签到记录,我们可以知道不同的场所有不同的适合访问时间。例如,酒吧和夜总会在白天可能不那么有吸引力,相反,一些艺术博物馆在晚上不开放。因此可以利用这些社交网络中的信息可以在空间关键字查询中精确获取用户需求、分析用户偏好。
然而,当同时考虑时间信息和社会关系时,空间关键字查询变得越来越复杂。因此,迫切需要一个能够很好地聚合空间、时间和社会信息的框架来处理基于社会的时间感知空间关键字查询(STSKQ)。近年来,人们设计了各种方法来支持空间关键词查询,这些方法主要集中在关键词和空间位置上。但是如果忽略时间和社会信息,空间关键字查询不能满足用户的需求。本次为大家介绍发表在ICWS 2021上的论文:《NETR-Tree: An
Efficient Framework for Social-Based Time-Aware Spatial Keyword Query》论文探索了基于社会的时间感知空间关键字查询(STSKQ),它返回一组综合考虑地理空间、文本、时间、社会得分的前k个对象。针对现有框架的局限性,论文设计了一种新的空间关键字查询索引——网络嵌入时间感知R-tree(NETR-Tree)及其相应的查询处理算法。1. 提出了基于社会的时间感知空间关键字查询(STSKQ)问题,它同时考虑了地理空间得分、关键词相似度、访问时间得分和社会关系效应,以返回预期的top-k结果。2. 设计了一个混合索引结构,即NETR-Tree,它利用网络嵌入和相应的有效剪枝策略来处理STSKQ。虽然聚合了额外的时间信息和社会关系,且NETR-Tree与基本空间关键词查询相比但仍然具有较高的效率。3. 进行了大量的实验来验证该方法的高效性和有效性。在两个真实世界的基准数据集上的结果表明,论文的框架在处理STSKQ方面显著优于最先进的算法。对于一个时空对象数据集D={o1,o2,o3....},D中的一个对象o用<o.l,o.W,o.T>表示,其中o.l是由经纬度组成的空间信息,o.W是一组关键词,o.T是对象o的签到时间分布集。一个有时间感知的查询q被表示为<q.u,q.l,q.W,q.t>,其中q.u,q.l,和q.W分别表示一个用户、该用户的位置和一组所需的关键字,q.t是发出查询的查询时间戳。一个用户被表示为一个<V,Nrs,C>,其中V表示通过网络嵌入策略获得的嵌入向量。对于一个用户u,Nrs (u)是u的邻居的集合,C(u)是用户u的签到记录的集合。那么STSKQ问题定义如下:
给定一个空间对象集D,LBSN中的用户u,以及u发布的基于社会的时间感知空间关键字查询q,查询返回一个结果集TOPk(u,q),其中TOPk(u,q)⊂D , |TOPk(u,q)|=k,且∀oi,oj : oi ∈TOPk(u,q),oj∈D-TOPk(u,q)有F(u,q,oi)≥F(u,q,oj),F是得分函数。
论文所提出的索引NETR-Tree如图一所示。首先分别从用户层和位置层获取输入,构建由网络嵌入和时间感知R-Tree(TR-tree)两部分组成的索引。在网络嵌入部分,NETR-Tree根据用户的社会关系网络结构将用户嵌入到嵌入向量中。在一种新的邻居选择方法的支持下,用户u的邻居的社会效应可以通过他们的嵌入向量和邻居历史签到的相似度来计算。在TR-tree部分,每个内部节点记录空间文本信息以及签到时间分布。TR-tree在查询处理过程中剔除了与空间、文本和时间无关的对象。因此,NETR-Tree可以高效地解决STSKQ问题。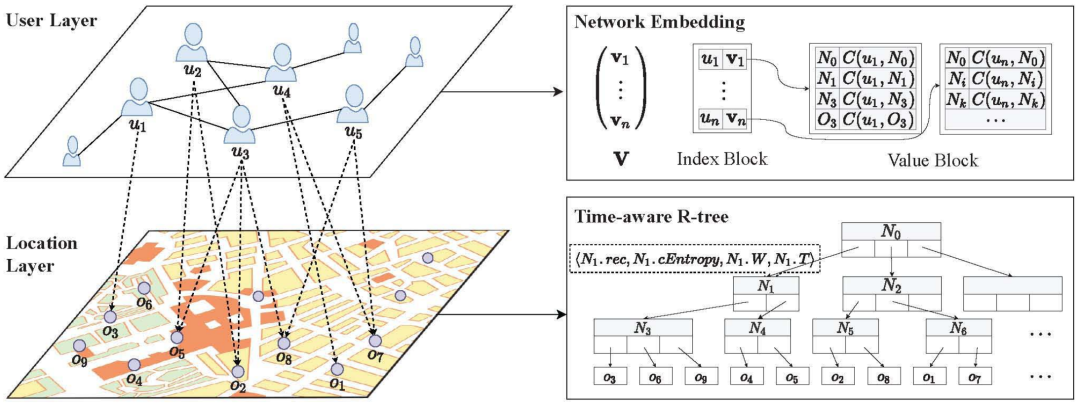
为了处理时间信息,即用户的访问时间和对象在空间关键字查询中的签到时间分布,论文构建了一个TR-tree。TR-tree是建立在具有时间信息的IR-tree之上的,它的结构如图一的右下角所示,TR-tree中的每个叶节点都与一个空间对象o相关联,o表示为<o.l,o.c,o.W,o.T>,其中的信息包括了该对象的位置(o.l)、类别(o.c)、关键字权重(o.W)和签到时间分布(o.T)。非叶节点N表示为<N.rec,N.cEntropy,N.W,N.T>,其中N.rec是TR-tree的最小边界矩形(MBR),N.W是一个IF-IDF权值集,包含N的子节点关键字的所有IF-IDF权值,N.T是N的签到时间分布,N.cEntropy则为该结点的类别熵。类别熵是论文添加了一个新的特性,用来测量区域的场地类别的异质性。这是因为在现实世界中,提供各种服务的商业街更受欢迎。例如,一个男人可能在吃完饭后唱卡拉ok,也有可能在购物后看电影。论文通过邻居选择方法、网络嵌入策略、用户倒排存储方案等步骤来测量用户之间的社会关系效应。在这项工作中,首先需要充分利用用户的历史签到记录,提取出用户偏好的以下特征:签到区域、签到时间、签到场所类别。然后对于这三个特征使用余弦相似度来计算用户之间的签到偏好相似度。然后,给定一个目标用户u,可以通过多维优化天际线算法来确定对于用户偏好有影响的用户。在这种情况下,如果Vi在所有相似性维度上都不小于Vj,并且至少在一个维度上优于Vj(Vk是uk对应的嵌入向量),则认为用户ui对另一个用户uj的决定有影响(将ui称为非支配用户)。我们认为,非支配用户是对目标用户影响最大的邻居的一部分。此外,对于目标用户u,我们将u的非支配用户和u的朋友合并,成为u的最终邻居。NETR-Tree要求用户和邻居之间存在相似性。如图一右上角所示,在TR-tree的顶部,我们利用LINE从用户的关系网络结构中学习一个网络嵌入。利用社会关系网络(U,E)(U是顶点集,每个顶点在LBSN中表示一个用户,E是顶点之间的边集,每个顶点表示两个用户之间的关系)作为LINE的输入图,经过(U,E)的结构特征训练后,LINE学习到一个由所有用户表示的向量组成的n x d矩阵V(图一),其中n为用户数,d为嵌入的维数。然后,对于一对相邻的ui和uj,我们计算它们对应的嵌入向量V(ui)和V(uj)的余弦相似度来衡量社会关系效应。然后计算用户u访问NETR-Tree叶节点o的社会关系效应函数Fs(u,o):u.Nrs是用户的邻居集合,C(ui,oj)是用户在oj的历史签到次数,因此对于每个用户u,应当可以访问u的历史签到记录。为了优化处理时间和空间消耗,论文提出了用户倒排存储方案。图一的右上角显示了论文的用户倒排存储方案,即Network-Embedding中的Value Block模块。这些块基于TR-tree进行维护,它有两个部分,即索引块和值块。与倒排文件类似,用户在用户签到文件中等价于关键字。因此,索引块包含U个条目。用户u的每个条目都包含其相应的嵌入向量V,并指向一个包含用户历史签到的块。在用户u的值块内有一个列表,记录了u在TR-tree节点中的对象的签到次数。综上所述,为了实现NETR-Tree中的用户社会关系网络嵌入模块,首先要通过LINE方法获得用户的网络嵌入矩阵,对每个用户u采用自底而上的更新策略,从叶节点到根节点保持用户签到记录,以提高检索效率。然后,计算用户u在节点n上的社会关系效应函数Fs(u,n),最后返回社会关系网络嵌入模块。为了处理为用户u和查询q并返回一个TOP-k(U,q)集合的STSKQ,论文利用最佳优先遍历,在堆中搜索得分最大的条目。当在空间关键字查询中考虑时间信息和社会信息时,需要一个复杂的排序评分函数。论文为NETR-Tree中的节点n设计的排序评分函数定义为: 其中Fg(q,n)代表空间得分,Fk(q,n)代表关键字相似性得分,Fs(q,n)代表社会关系效应,Ft(q,n,t)代表访问时间得分。STSKQ处理中使用最大堆来保证索引节点和对象按其分数的降序排序。如果堆中的第一个条目是一个对象,则它是堆中最好的一个对象,并将被插入到结果集TOP-k(U,q)中。对于时间t时的任何节点n,如果n.T (t)为0,则表示在n所包含的区域内的所有对象在t时刻关闭,因此无需访问n的子节点。此外,位于搜索半径之外的对象和节点、不包含所有查询关键字或得分小于堆中TOP-k的对象被剪枝。最后,它将返回top-k个符合要求的对象。论文系统地评估了所提出的索引和算法的性能,并与最先进的方法进行了比较。所有的索引和算法都是用Python实现的,并在具有2.1 GHz Intel Xeon处理器和64GB内存的Linux服务器上运行,使用的是两个真实世界的数据集,Yelp1和Weeplace,这两个数据集都包含地理位置、关键字、签到时间和关系信息。为了进行全面的比较,论文实现了三个基线框架,包括一个具有代表性的基线框架IR-tree,一个目前最先进的基于树的框架Routing R-tree ,以及一个非基于树的框架SKB-Inv索引,然后进行了一组实验来评估NETR-Tree在两个不同的真实LBSNs数据集中的索引构建和STSKQ处理的效率,并与不同基线算法进行了比较。从结果对象的数量、查询关键词的数量、不同搜索半径的影响几个方面来评估STSKQ处理查询的效率。对于每一组实验,论文评估了100个随机查询,测量平均处理时间和平均磁盘I/O访问次数(即节点访问的次数),所有实验重复5次并记录平均结果。首先在两个数据集Yelp和weePlace上使用三种基线算法评估NETR-Tree的构建时间和索引大小。如图二所示,Routing R-tree和SKB-Inv索引在两个数据集的时间和空间上都有很大的高成本,这是因为Routing R-tree为每个时间间隔维护一个R-tree,而一个对象可以同时存在于许多不同的R-tree中。对于SKB-Inv索引,它为每个时间间隔、关键字和用户的签入记录维护一个倒排列表。这两种方法都会导致极高的冗余度。相比之下,由于缺乏时间和社会信息,IR-tree是构建效率最高的。尽管考虑了所有的信息,如果排除IR-tree,NETR-Tree是建设成本中最有效和轻量级的。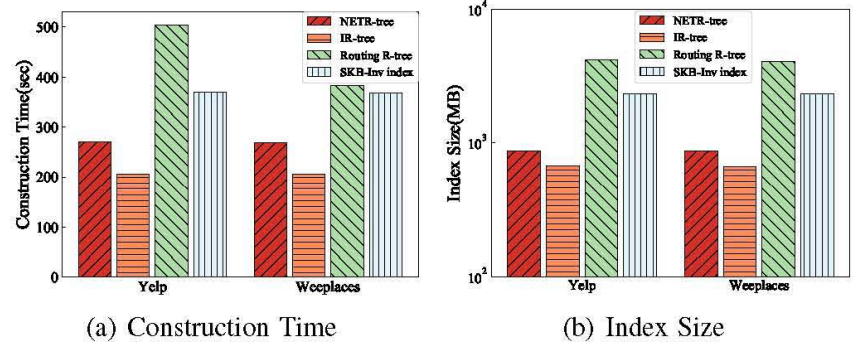
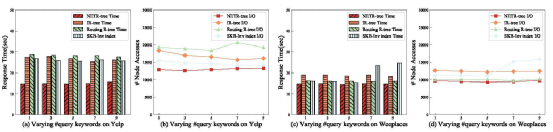
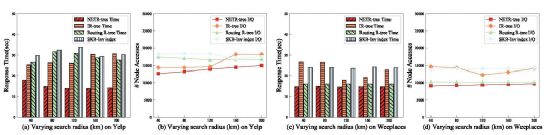
接下来,论文研究了不同的k(即返回的对象的数量)对处理时间和I/O成本的影响。结果如图三所示,NETR-Tree的效果远远超过了其他算法。此外,所有算法在Weeplace上的性能都优于Yelp,特别是对于Routing R-tree和SKB-Inv索引。原因是Weeplace中所包含的的社会关系信息比Yelp少得多,这减轻了处理社会信息的负担。从图三.(c)(d)可以发现IR-tree在没有对时间和社会信息进行适当处理的情况下,会在候选对象中检索大量的错误对象,而对这些对象再次进行过滤的操作会导致较高的时间成本。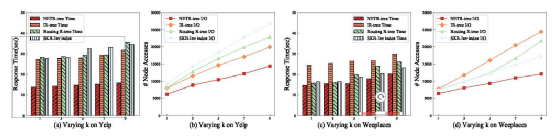 如图四所示。显然,NETR-Tree在处理时间和I/O成本上优于其他算法。另外,从图四(c)(d)可以看出,SKB-Inv索引的运行成本随着关键字个数的增长而上升。WI,因为SKB-Inv索引需要扫描更多的对象组和更多的关键字请求。在处理时间方面,,Routing R-tree在Weeplaces中表现良好,而在Yelp中表现较差。同样,后者的原因是Yelp在处理社会关系信息方面的负担要重得多。在Weeplaces中,Routing R-tree和NETR-Tree的良好性能主要是由于它们的时间段方案和时间信息。作为回报,Routing R-tree在构建成本上做出了牺牲,而NETR - Tree在构建和查询处理之间进行了有效的权衡。最后论文还比较了不同大小的空间搜索半径在不同方法上的效率,如图五所示,由于时间和社会信息有助于剔除许多不相关的对象,NETR-Tree再次表现最佳。此外,如图5(c)(d)所示,由于时间段方案的原因,NETR-Tree和Routing R-tree的处理时间保持稳定,而其他算法的性能则随搜索半径的变化而变化。论文在考虑空间约束、时间信息和社会关系的基础上,提出了基于社会的时间感知空间关键字查询(STSKQ)。为此,文章提出了一种新的索引结构——网络嵌入时间感知R-tree (NETR-Tree)。为了有效地解决STSKQ问题,设计了两层方案和查询处理算法。为了处理海量的用户关系网络,NETR-Tree利用网络嵌入策略来衡量用户发出查询时的社会效应。因此,NETR-Tree可以根据地理空间评分、关键词相似度、访问时间评分和社会关系效应给出top-k结果对象。最后,在两个真实数据集上进行了大量的实验,验证了NETR-Tree的效率和有效性。
如图四所示。显然,NETR-Tree在处理时间和I/O成本上优于其他算法。另外,从图四(c)(d)可以看出,SKB-Inv索引的运行成本随着关键字个数的增长而上升。WI,因为SKB-Inv索引需要扫描更多的对象组和更多的关键字请求。在处理时间方面,,Routing R-tree在Weeplaces中表现良好,而在Yelp中表现较差。同样,后者的原因是Yelp在处理社会关系信息方面的负担要重得多。在Weeplaces中,Routing R-tree和NETR-Tree的良好性能主要是由于它们的时间段方案和时间信息。作为回报,Routing R-tree在构建成本上做出了牺牲,而NETR - Tree在构建和查询处理之间进行了有效的权衡。最后论文还比较了不同大小的空间搜索半径在不同方法上的效率,如图五所示,由于时间和社会信息有助于剔除许多不相关的对象,NETR-Tree再次表现最佳。此外,如图5(c)(d)所示,由于时间段方案的原因,NETR-Tree和Routing R-tree的处理时间保持稳定,而其他算法的性能则随搜索半径的变化而变化。论文在考虑空间约束、时间信息和社会关系的基础上,提出了基于社会的时间感知空间关键字查询(STSKQ)。为此,文章提出了一种新的索引结构——网络嵌入时间感知R-tree (NETR-Tree)。为了有效地解决STSKQ问题,设计了两层方案和查询处理算法。为了处理海量的用户关系网络,NETR-Tree利用网络嵌入策略来衡量用户发出查询时的社会效应。因此,NETR-Tree可以根据地理空间评分、关键词相似度、访问时间评分和社会关系效应给出top-k结果对象。最后,在两个真实数据集上进行了大量的实验,验证了NETR-Tree的效率和有效性。孙莹莹
重庆大学计算机科学与技术专业大三在读学生,重庆大学START团队成员。
主要研究方向:时空数据管理 | |
时空艺术团队(START,Spatio-Temporal Art)来自重庆大学时空实验室,旨在发挥企业和高校的优势,深入探索时空数据收集、存储、管理、挖掘、可视化相关技术,并积极推进学术成果在产业界的落地!年度有2~3名研究生名额,欢迎计算机、GIS等相关专业的学生报考!