




获取人们的出行意图对于理解人类移动行为和发展相关的智能服务都至关重要。然而在真实世界中,乘客的出行意图是复杂多样的,且可用的数据源以及标签信息通常是有限的。因此,训练出能进行大规模出行意图预测的高性能模型极为困难。为此,我们提出了一个半监督的深度嵌入框架,来使能大规模的细粒度的出行意图预测。该框架首先从车辆GPS轨迹和公共POI签到数据中得到多种增强的出行情境,并将POI情境转换成图结构,然后建立了一个带有自动编码器结构的双注意力图嵌入网络模型(DAGE-A: Dual-Attention Graph Embedding Network with Autoencoder architecture),来同时完成预测和重构任务。具体地,该模型使用图注意力网络来对上/下车点的POI语义建模,并从无标签的出行数据中提取补充知识;然后使用soft-attention聚合不同的出行语义以进行最终的预测。该工作在北京和上海的数据集上进行了充分的实验,结果表明我们的方法取得了最优的性能,并且可以将标记工作减少多达 20%。本文介绍的是重庆大学陈超老师团队发表在CCF-B类期刊IEEE Transactions on Intelligent Transportation Systems上的论文《Enriching Large-Scale Trips with Fine-Grained Travel Purposes: A Semi-Supervised Deep Graph Embedding Framework.》
(全文链接:https://ieeexplore.ieee.org/document/9894369)
一、背景介绍
获取人们的出行意图有助于理解人类移动行为,并且有助于发展出行相关的智能服务。例如,获取单个乘客的出行意图可以实现更具个性化的车载广告;获取全市范围的出行意图可以帮助制定公共交通计划(例如,为大量“工作”意图的出行地点设置新的公交路线)。
然而现实中的出行意图往往无法通过传感设备自动收集,需要借助有效的预测模型。由于人类移动行为的复杂性,要实现准确的出行意图预测是极具挑战的。一方面是因为人类在现实世界中的活动是多种多样的并且极具个性化,乘客的出行带有很大的不确定性;另一方面,城市中乘客的出行意图或活动,常常被很多因素所影响(例如,时间,地点,或者周边的功能区分布),因此出行意图的预测是很复杂的。
近年来随着信息通信技术和物联网的繁荣发展,人类活动的方方面面都可以被记录在信息空间中。因此出行意图预测的一种可行方案是根据多种来源的信息去理解乘客的活动语义。相关的工作可以达到超过90%的预测准确率。但许多相关工作都依赖一些敏感的信息去对用户的偏好进行建模,例如乘客职业、活动持续时间长等等。随着数据保护相关法律法规的出台,这些技术是否还能在实际中应用还有待商榷。更糟糕的是,这些方法都主要应用在小规模出行数据集中,并且返回相对粗粒度的出行意图。
为了实现更加普适和隐私友好的服务,本文提出一种情境感知的预测方法,能够在大规模数据集中自动预测细粒度的出行意图。本文具体的目标应用场景是出租车等日常乘车服务,面临着两大关键挑战:用于描述活动语义的有用信息非常有限,同时人工标注的成本非常高且质量不可控。因此在大多数情况下,可供预测算法学习的带标签出行数据非常有限。
本文提出一种新颖的半监督深度嵌入框架(DAGE-A),用于以情境感知的方式来实现细粒度的出行意图预测,通过整合车辆轨迹数据和POI签到数据来得到出行情境的语义,建立一个具有自动编码器架构的双注意图嵌入网络,同时完成预测和重构,通过结合来自无标签出行数据的补充知识来提高性能。
二、问题定义
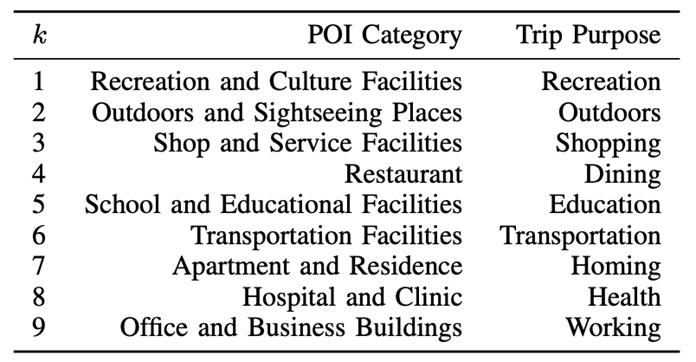
本文中,出行意图的预测问题可以被视作半监督学习的分类问题。具体来说,给定城市中的两个出行数据集合(有标签和无标签数据集TRl和TRu),城市公开POIs集合和对应的签到数据集CI,以及一组出行意图候选集合,使用已标注和未标注的数据训练一个半监督预测模型,对于未知的出行tr预测每一个意图候选的概率: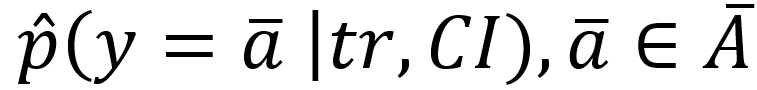 。表1展示了9种POI类别和对应的出行意图。
。表1展示了9种POI类别和对应的出行意图。
表 1:9种POI类别和对应的出行意图
三、方法介绍
1.总体框架
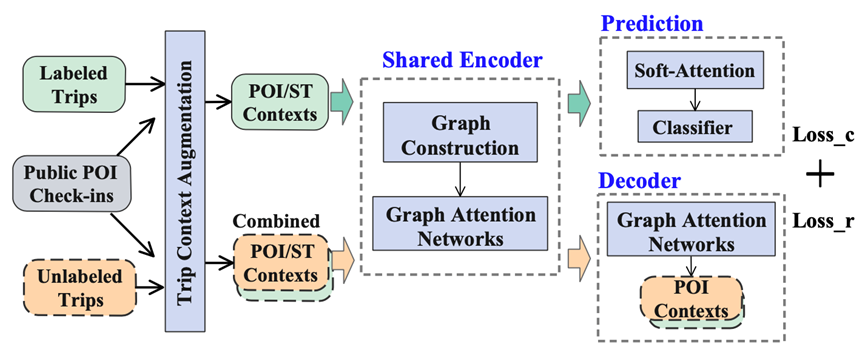
图 1:半监督出行意图预测框架
图1展示了本文所提出的半监督出行意图预测框架。第一阶段为出行情境增强,在此阶段,公开的POI签到数据集将和有标签和无标签的出行数据分别聚合,从而得到增强的出行情境,包括上/下车点的POI情境(OD POI contexts)和时空情境(spatiotemporal context)。
第二阶段为含有自动编码器结构的双注意力神经网络(三个虚线框所示)。简言之,该阶段含有两个并行任务,一个是利用有标签的出行数据进行有监督预测,另一个是利用有标签和无标签的联合数据集进行无监督重构。其中,Encoder组件首先将增强的POI情境转换为图结构,然后使用图注意网络来提取上/下车点活动的语义。有标签的数据被送入Prediction组件中,使用软注意力机制(soft-attention)和分类器来聚合活动语义并计算预测损失Loss_C。联合数据集则被送入Decoder组件中,使用解码器网络计算重建损失Loss_R。最终结合以上两种损失来一起训练整个半监督神经网络模型。
2. 出行情境增强
1)时空情境
对一次出行tr,我们从GPS轨迹数据中提取四类特征作为时空情境:工作日/非工作日TYP(tr),上/下车时间H(to),H(td),出行耗时td - to,及上下车点之间的距离ld - lo。时空情境如下表示:
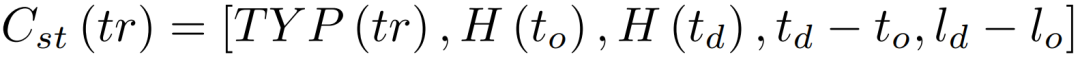
2)POI情境
我们分别为上/下车点周边250米以内的每个POI类别,提取了静态特征和动态特征来表示上/下车点附近人们的活动情况,并将其作为增强后的POI情境。其中静态特征为“距离”和“唯一性”,分别表示,该类POI点与上/下车点间的最近距离和该POI类别在上/下车点附近的唯一程度:
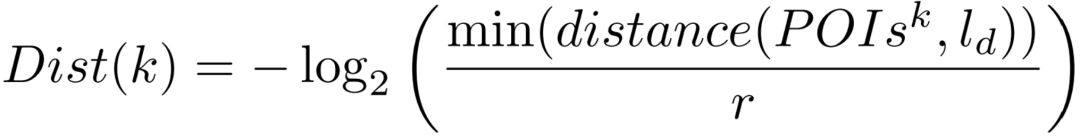
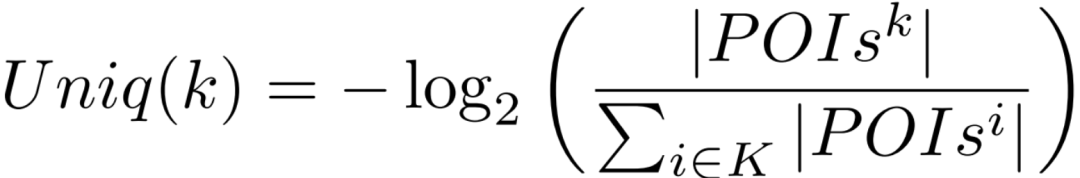
动态特征为“时段流行度”,即对应乘客上/下车时间段内该类POI 签到信息的统计:
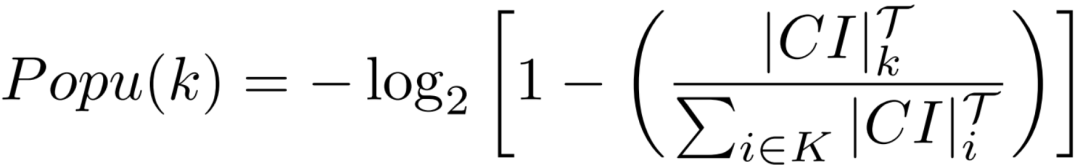
3.半监督图嵌入模型
我们利用图嵌入网络为乘客活动语义建模,并且利用自动编码器将大量无标签数据整合进模型的训练中。这种半监督的方式可以帮助模型捕获更加完整的数据分布信息,从而改善模型的性能。
1)图嵌入自动编码器:
人类的活动先后顺序通常存在某些关联,例如“吃饭”与“购物”。因此我们从POI 情境中提取活动语义时,应当考虑到不同POI类别之间的潜在关系。POI 情境中的POI类别类似于图的节点,POI特征类似于节点特征,POI不同类型间的相关性类似图结构中的边。因此我们首先将上/下车周边的POI 情境转换成图结构,然后使用图注意力网络为每个POI类别提取邻居活动语义。
图构建
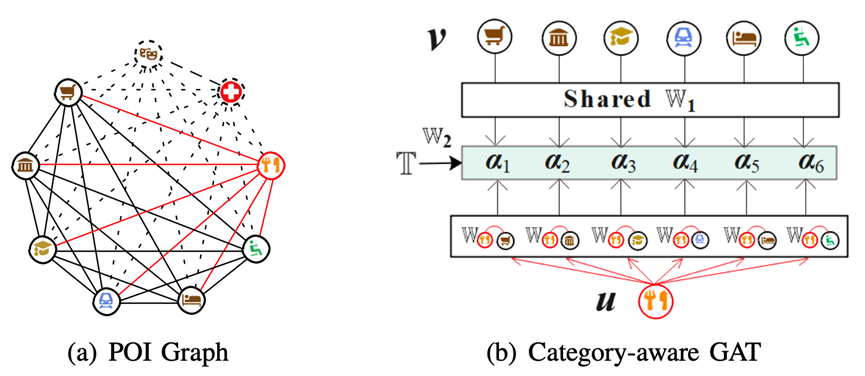
图 2:图构建和节点相关性计算示意图
我们使用无向完全图来表示上/下车点的POI 情境。图2(a)展示了为某地点生成的POI图,节点表示9种POI类型,边表示不同POI类型间的关联关系。由于在现实世界中,某些地点附近并不含有所有POI类型,因此在图结构中某些不存在的POI类型的节点和关系用虚线示意。图中每个节点包含三种增强的特征(即“距离”,“唯一性”,和“时段流行度”)。最终,上/下车点的POI 情境可以分别用图Go和Gd来表示。
编码器--POI语义提取
我们使用图注意力网络(GAT)来建模不同POI类别之间的相关性,并提取高级POI语义。首先计算POI图中每个节点与邻居节点间的相关性,即注意力系数。传统GAT对于一个中心节点,其与每个邻居的注意力系数是由相同的参数计算所得。然而人类活动中不同的POI类别间往往存在不同程度的关联,例如“用餐”和“娱乐”之前的相关性比它与“健康”之前的相关性更强。
与传统GAT不同,我们提出一种新的类别感知(category-aware)的GAT来提取节点的邻居语义。不仅如此,因为不同活动之间的相关性可能与时间相关,我们还在计算中考虑了时间的特征 (即日期类型和上/下车时间)。图2(b)展示了图2(a)中“Dining”节点与其邻居节点的相关性的计算,具体计算方式如下:
(即日期类型和上/下车时间)。图2(b)展示了图2(a)中“Dining”节点与其邻居节点的相关性的计算,具体计算方式如下:
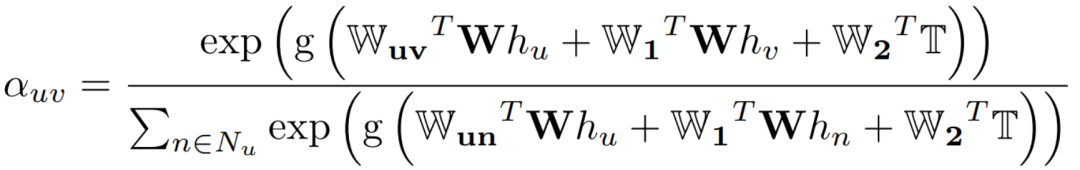
我们采用多头机制通过注意力系数来计算节点u的邻居特征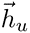 。
。
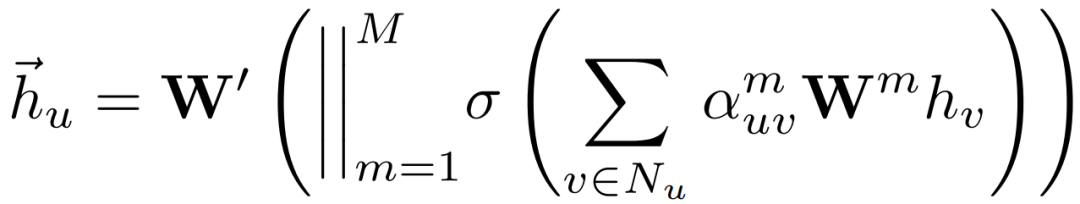
在图嵌入网络中,我们采用两个多头类别感知的GAT来增强学习能力。从而获得带有邻居活动语义的高级OD POI情境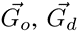 ,我们进一步将每个节点自身的增强特征和它的邻居特征聚合,得到G'o,G'd。
,我们进一步将每个节点自身的增强特征和它的邻居特征聚合,得到G'o,G'd。
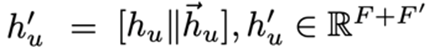
解码器--重构
解码器进行编码器的反向操作,来重构POI情境的原始特征。由于编码器主要采用GAT来提取POI情境的邻居特征,我们采用一组新的带有逆特征的GAT来作为解码器。重构的损失函数用平方欧氏距离来表示。
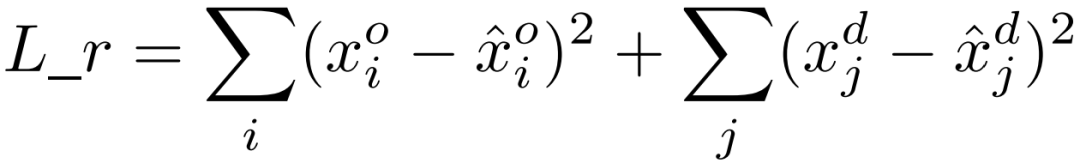
重构的损失和预测的损失将用于训练编码器中的语义提取模型。以这种方式,编码器可以捕获大规模出行数据(包括有标签数据和无标签数据)的数据分布来提升性能。
2)预测:
软注意力--出行语义聚合
软注意力(soft-attention)可以被描述成将一个query和一组key-value映射到一个输出。输出是value的加权和,而权重是由query和特定的key通过适应度函数(compatibility function)计算所得。在本研究中乘客在终点的意图(活动),可以视为是对一种query(特定时间和起点的出行)的response。
因此,我们采用soft-attention机制,将起始点的POI情境G'o和时空情境Cst作为query, 终点的每一类POI语义作为keys和values。
我们首先将G'o和Cst通过一个全连接层组合,成为一个query: host,然后建立一个多头soft-attention和前馈网络,作为自适应函数,最后计算目的地POI情境中一类POI点u(u∈G'd)的系数和出行活动语义。
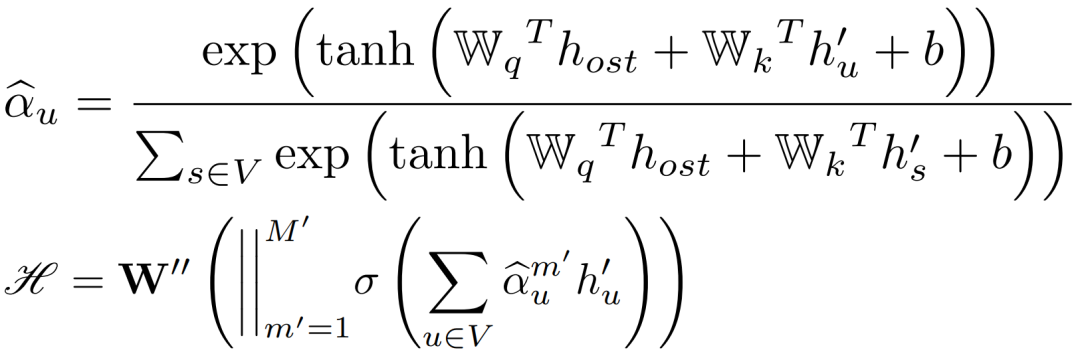
分类器
在分类阶段,我们构建了一个全连接层与softmax函数组合的分类器,基于所提取的乘客活动语义,计算出每一类出行意图的概率值,并选出最大概率的结果作为输出。计算过程如下:
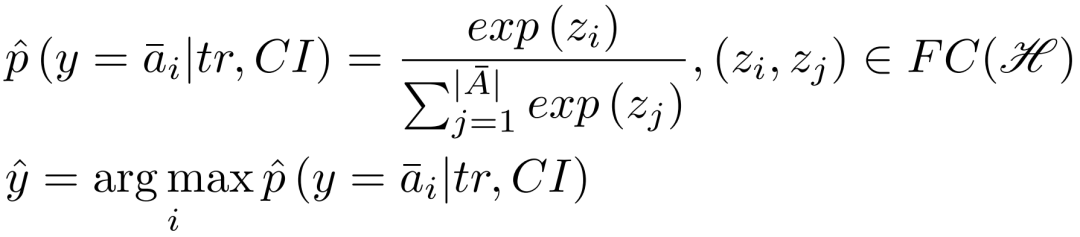
预测的损失函数基于cross entropy如下计算:
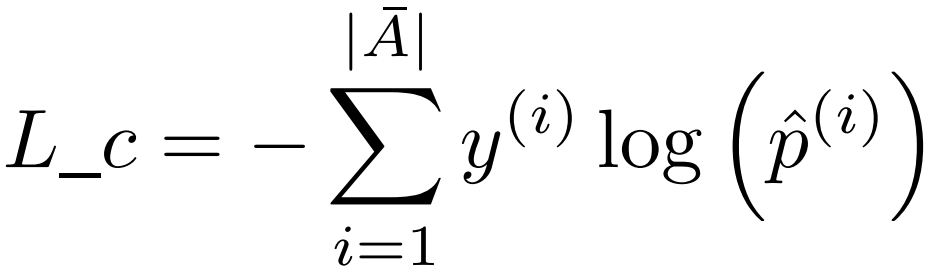
最后,全局的损失函数由重构损失和预测损失的加权和表示。
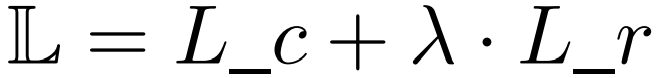
四、实验结果
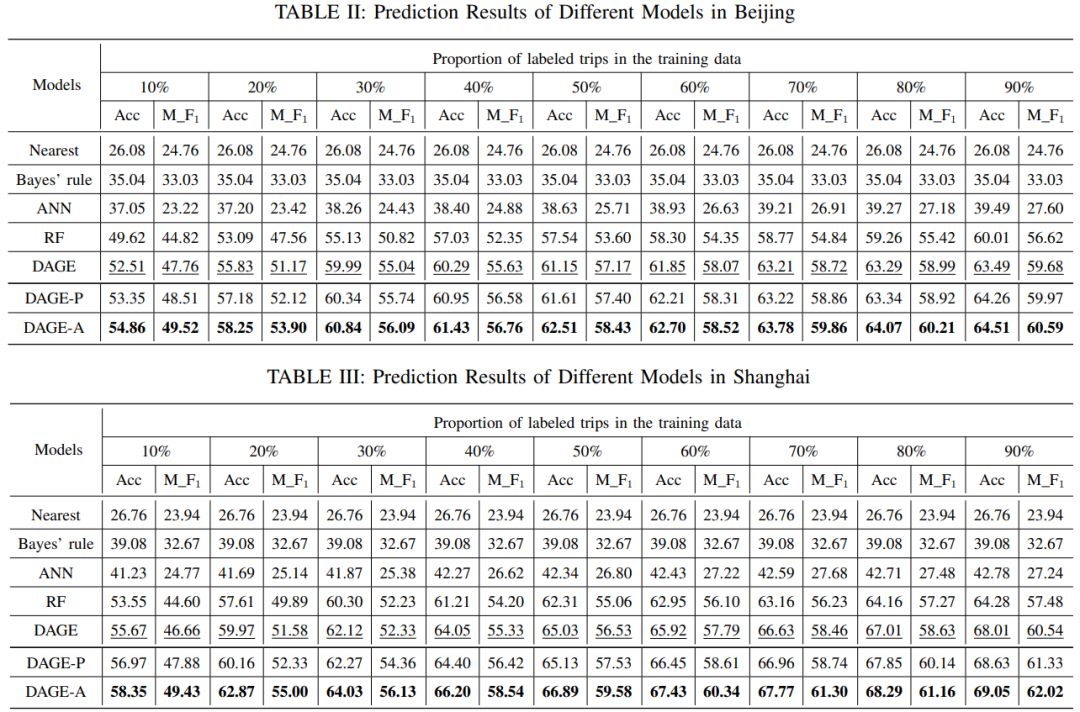
实验采用了2015年北京和上海的专车数据集,包括北京五环内有出行意图标注的366783条出行记录,和上海中心城区有标注的270943条出行记录。同时我们采用街旁POI签到数据集,包含北京的511133条记录和上海的712305条记录。实验中我们进行了9类出行意图的预测,对比实验包含了现有意图预测研究中的Nearst, Bayes’s Rule, ANN, RF四种基线模型,此外还使用了DAGE-A的两种变体DAGE和DAGE-P,以评估我们的半监督框架在预测出行意图和减少人工标注量中的有效性。
表2分别展示了在北京和上海的数据集中的出行意图预测结果,可以看出DAGE-A算法的表现非常出色,超越了其他baseline的表现;相对其他学习方式,半监督学习框架的表现普遍更加优秀,而我们所提出的半监督框架性能最优。
表 2:不同模型在北京和上海数据集上的预测结果
除了评估整体效率外,我们还研究了模型在特定出行意图上的性能。图3展示了在北京数据集上的9类POI的预测结果。可以看出,不同类别的POI预测难度存在差异。例如在较少标签信息(10%)情况下,“Recreation”和“Outdoors”比“Working”和“Health”更加难以预测。并且当标签数据的比例增大时,各类POI的准确度提升也不同,“Dining”的提升高达20%,而“working”的提升不足10%。
图3还可以看出,当标签数据比例增加至70%之后,DAGE-A的提升虽不显著,却仍然优于DAGE在100%标签数据上的表现。因此,从现实世界的角度来说,使用我们的半监督学习框架,利用含70%标签数据训练模型就可以达到有效的准确度,节约了人工标注成本。
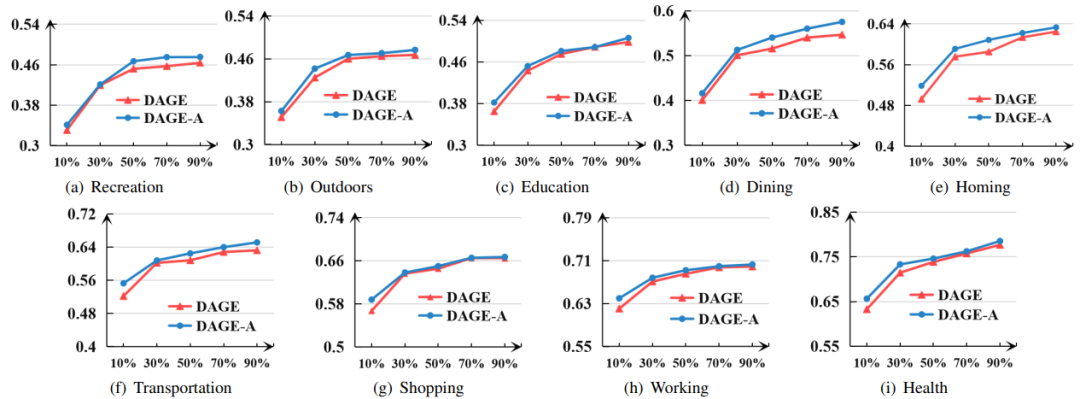
图 3:DAGE和DAGE-A在不同POI类别上的预测表现
此外,文章也从不同的时间维度和空间维度解读了我们模型的准确性。实验结果如下图。
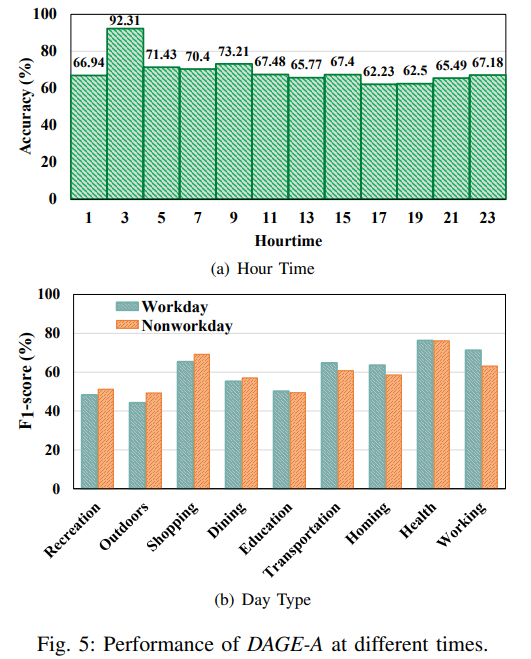
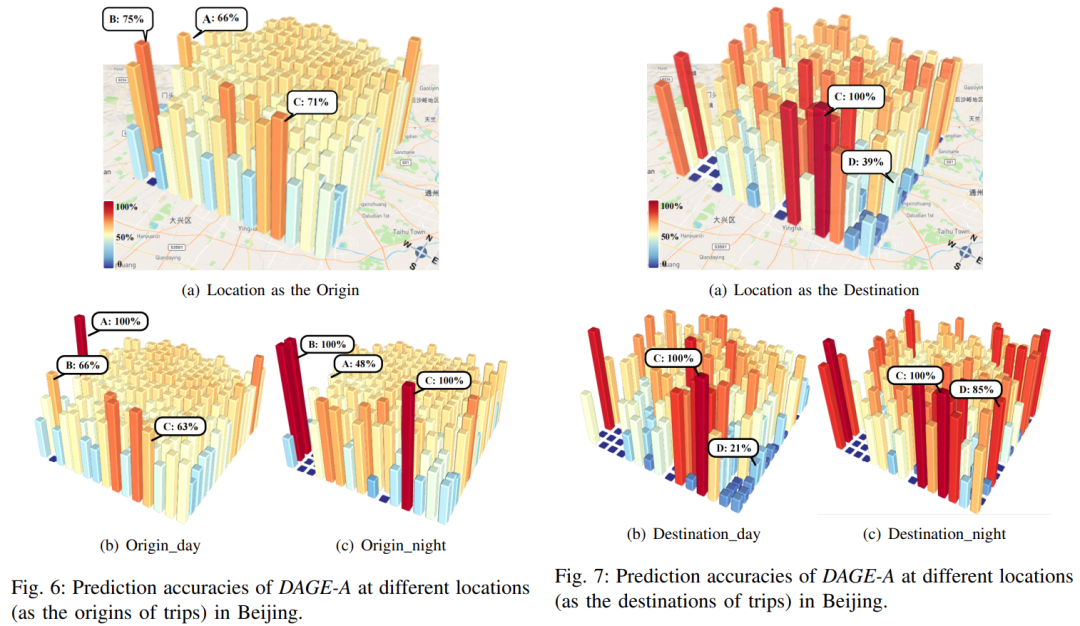
五、总结
在本文中,我们提出了一个新颖的半监督框架DAGE-A,以预测大规模细粒度的出行意图。它基于普适的数据源,并且在标签数据有限的情况下仍然有效,更加适用于现实世界中的应用场景。具体而言,我们采用车辆的GPS轨迹和公开的POI签到数据来表示不同的出行情境,然后提出具有自动编码器结构的双注意力图嵌入网络提取高级活动语义,从而预测出行意图。此外,该半监督框架还通过结合大量无标签数据的补充知识来改善模型的性能。大量的实验结果验证了模型的有效性和先进性。未来,我们将继续拓展和深入这项工作,探索更多的城市数据源以丰富出行语义。
-End-
