





轨迹建模
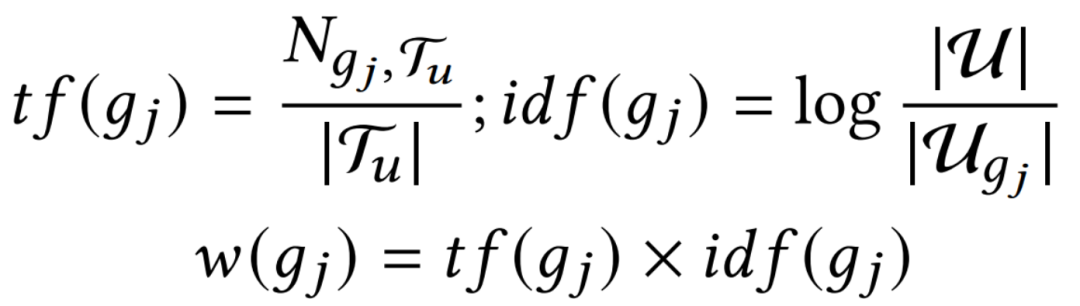
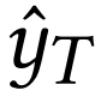 :
: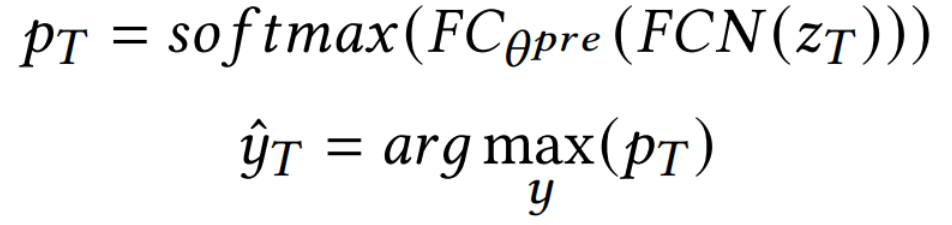
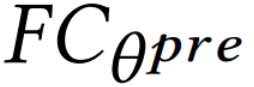 是预测层,将由FCN获得的向量映射到参数θpre的概率分布;是预测结果。
是预测层,将由FCN获得的向量映射到参数θpre的概率分布;是预测结果。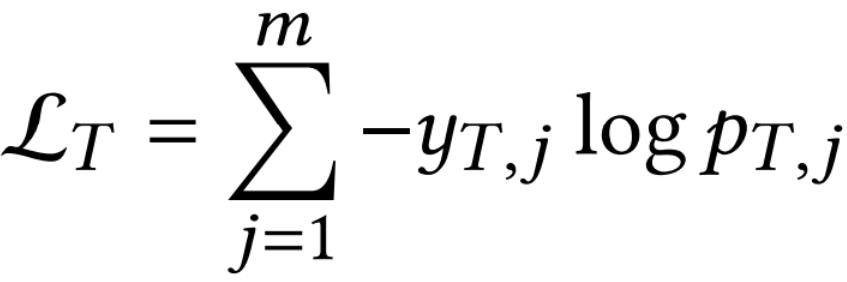
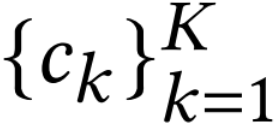 的相似度
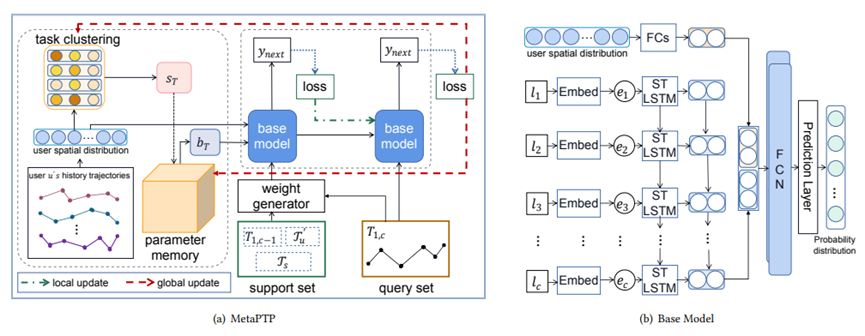
的相似度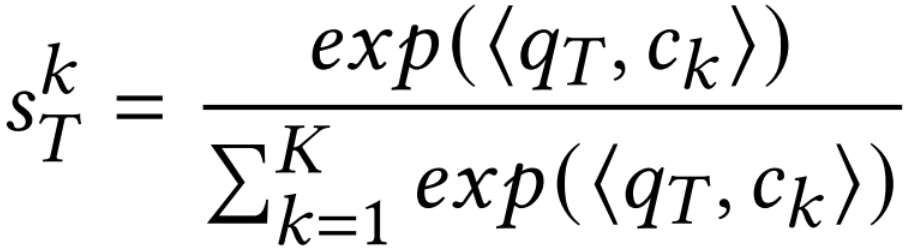 ,其中 <qk, ck>是查询向量qT和聚类中心的余弦相似度,K是聚类的数量。值得注意的是,所有集群的聚类中心在训练前是随机初始化,并在训练期间不断更新。,以实现在具有相似旅行偏好的用户之间共享知识以及在初始化步骤中提供个性化的网络参数。从MP中读取网络参数bT:bT = (sT)T ⋅MP,bT是个性化偏差项。因此,轨迹可以在广义的基础上学习每个集群中的共享知识,得到个性化的预测层参数θpre:θpre =
ϕpre - τbT,其中ϕpre是预测层的全局参数,参数τ控制个性化比率,即控制bT被考虑的占比。最后,再更新MP:
,其中 <qk, ck>是查询向量qT和聚类中心的余弦相似度,K是聚类的数量。值得注意的是,所有集群的聚类中心在训练前是随机初始化,并在训练期间不断更新。,以实现在具有相似旅行偏好的用户之间共享知识以及在初始化步骤中提供个性化的网络参数。从MP中读取网络参数bT:bT = (sT)T ⋅MP,bT是个性化偏差项。因此,轨迹可以在广义的基础上学习每个集群中的共享知识,得到个性化的预测层参数θpre:θpre =
ϕpre - τbT,其中ϕpre是预测层的全局参数,参数τ控制个性化比率,即控制bT被考虑的占比。最后,再更新MP: 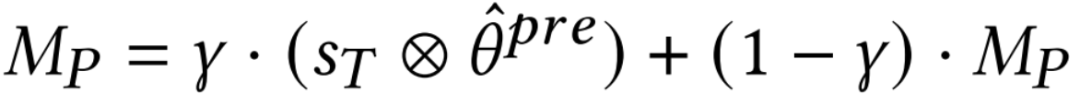 ,其中
,其中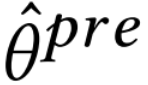 学习后支持集上预测层的参数,𝛾控制MP的更新率,即添加多少新信息。
学习后支持集上预测层的参数,𝛾控制MP的更新率,即添加多少新信息。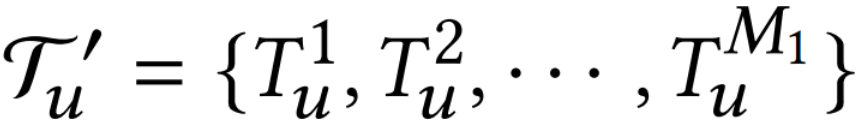 进行微调,其中相似度利用与T1,c的最长公共子序列(LCSS)进行评估获得:
进行微调,其中相似度利用与T1,c的最长公共子序列(LCSS)进行评估获得: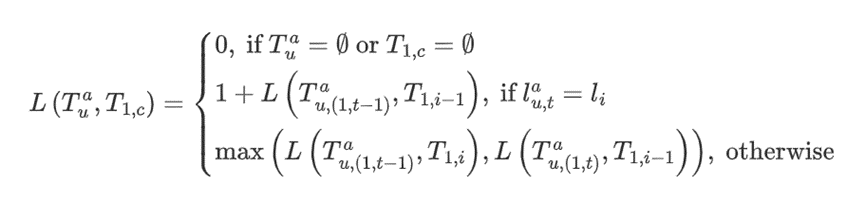
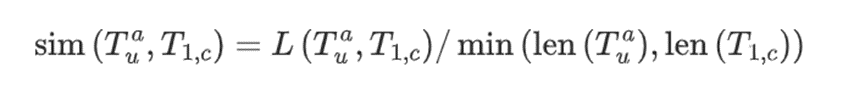
 进行微调,相关度用
进行微调,相关度用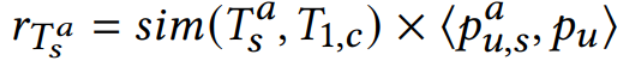 来衡量,其中
来衡量,其中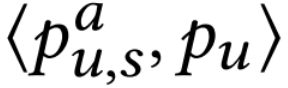 是余弦相似度。
是余弦相似度。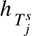 和用户偏好表示
和用户偏好表示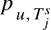 得到
得到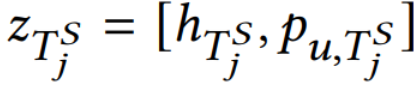 。然后,通过余弦相似度计算轨迹之间的相关性,再利用全连接层获得权重。
。然后,通过余弦相似度计算轨迹之间的相关性,再利用全连接层获得权重。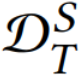 微调初始网络以适应每个任务。
微调初始网络以适应每个任务。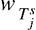 并使得损失函数
并使得损失函数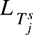 最小。
最小。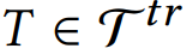 的查询集
的查询集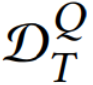 的损失总和最小:
的损失总和最小: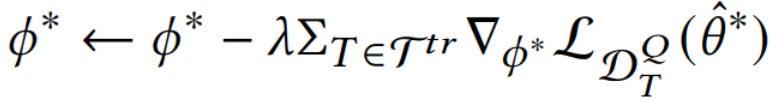
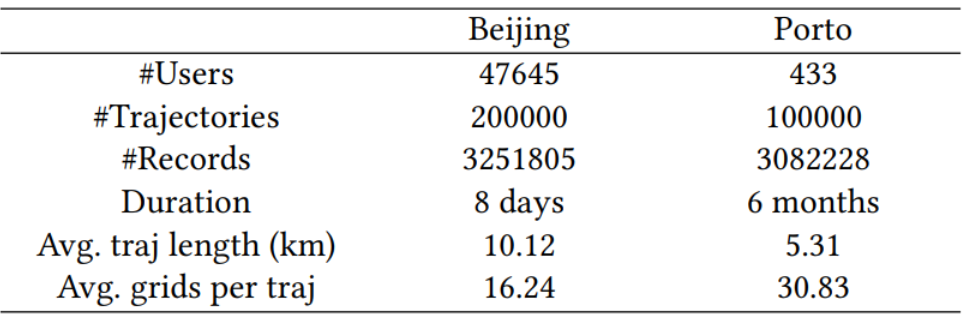
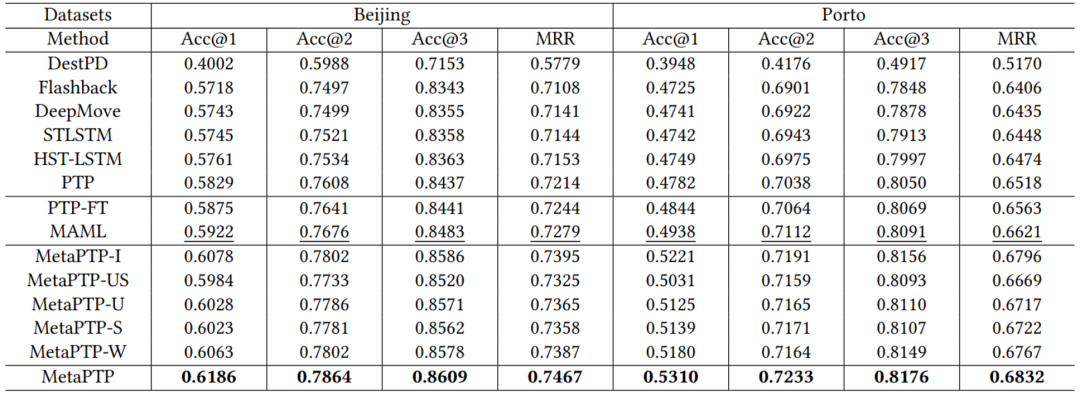

本文作者
吴怡
重庆大学计算机科学与技术(卓越)专业在读大三学生,重庆大学CUST团队成员,主要研究方向:时空数据管理与挖掘。
文章转载自时空实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
