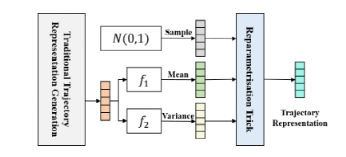
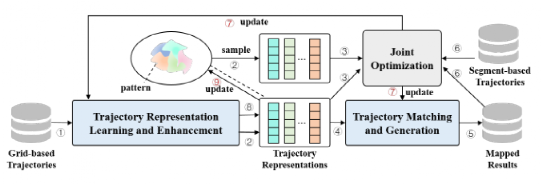
地图匹配是一个基础研究课题,其目标是将 GPS 轨迹与道路网络上的路径对齐。然而,受恶劣环境的影响,原始 GPS 轨迹数据往往存在三个关键问题,即噪声、低频和不均匀性,导致定位不精确和不确定。现有地图匹配模型无法从低质量(即噪声、低频和不均匀)轨迹数据取得令人满意的性能。本文带来了由重庆大学陈超老师团队发表在国际顶级数据挖掘领域期刊TKDD 2022上的论文:《L2MM: Learning to Map Matching with Deep Models for Low-Quality GPS Trajectory Data》随着GPS等位置获取技术的普及和应用,海量的GPS轨迹数据被采集并广泛应用于各个领域。原始 GPS 轨迹数据往往存在三个关键问题,即噪声、低频和不均匀性。例如,城市环境中的高层建筑遮挡了多颗 GPS 卫星,导致 GPS 定位误差;有限的能量和传输带宽限制了 GPS 位置只能以低频进行采样;不同的 GPS 设备设置和不可预知的通信故障可能会产生不均匀的采样时间间隔。因此,提出了地图匹配来解决将原始GPS轨迹捕捉到道路网络以识别运动物体的真实运动路径和真实位置的问题。地图匹配的任务对于许多应用程序具有重要意义。例如导航、行程时间估计、路线优化等。然而,对于低质量的轨迹,地图匹配模型很难达到令人满意的性能。在本文中我们设计了一个通用的、鲁棒的基于深度学习的模型来解决低质量GPS轨迹的地图匹配问题。它对低采样率、非均匀采样率和噪声具有更强的鲁棒性。而且,即使使用少量的训练数据,它也能达到相当好的性能。此外我们开发了一种模式识别方法,基于学习到的表示来探索隐藏在历史轨迹中的模式,并通过使用联合优化方案将它们明确地纳入到地图匹配中。值得注意的是,这是首次尝试将模式识别作为地图匹配任务的重要组成部分,以提高所提模型的泛化能力。地图匹配问题的一般目标是识别基于段的轨迹,因此我们需要将GPS的原始轨迹集{TP},通过一个映射函数f映射到段的轨迹集{TS}中,即实现f(TP)->TS的过程,在此过程中我们需要克服噪声、低频、和不均匀以及一些主观因素等诸多因素。最后将空间向量解码回路网上的具体地点实现规划过程。如图所示,本方法主要由四个部分组成:1)轨迹表示学习与增强,这部分主要利用了高质量轨迹增强和利用数据分布增强、2)模式识别与表示,这个部分我们挖掘轨迹中隐藏的模式,并将其进一步引入到地图匹配之中、3)轨迹匹配与生成,这个部分中我们主要对轨迹向量进行解码,并且将解码后的向量映射到地理空间、4)联合优化,最后这个部分主要共同优化前面所提到的三个组分。L2MM 有两个工作阶段,包括离线训练和在线推理。在离线训练阶段,这四个组件协同工作,训练深度学习模型进行地图匹配。离线训练阶段的流程,可以参考图1中带箭头的实线。而在在线推理阶段,使用现成的深度模型,只有轨迹表示学习和增强、轨迹匹配和生成两个组件参与工作并返回基于给定测试点的映射结果轨迹。可以将高频或低频的基于点的轨迹连续输入L2MM以进行驾驶路线推断。在线推理阶段的过程如图 1 中带箭头的虚线所示。轨迹表示学习是将物理空间中的原始轨迹转换为潜在空间中的表示向量,对于低质量的基于点的轨迹来说,包含的真实驾驶路径的信息很少,导致语义表示模棱两可,而且有限的轨迹数据削弱了表示的泛化能力,所以提出了高频轨迹的增强以及增强数据分布。高频轨迹的增强。高频轨迹包含了车辆运动的更多细节,这可以很好地去弥补低频轨迹的信息有限的缺点。所以我们结合高频轨迹的信息来增强低频轨迹的潜在表示。我们选用seq2seq模型自动学习高质量的轨迹表示。在我们的模型中将低频轨迹作为输入序列,相应的高频轨迹作为目标序列,如下图所示,它主要由编码器和解码器两个模块组成,前者可以将可变长度的输入序列映射到一个固定维的上下文向量一个单元嵌入层、一个循环神经网络 (RNN) 层和一个全连接层实现。我们使用𝒉𝑖 = GRU (𝒉𝑖−1, 𝑔𝑖)来更新隐藏状态。为了增强特征提取能力,我们特意采用了双向GRU作为基本单元,从前后两个方向捕捉其中复杂信息。后者从高维空间的上下文向量来生成恢复的轨迹。由RNN 层、全连接层和 softmax 层三层组成。我们利用配对的高频基于点的轨迹𝑇𝑝𝐻导出的相应的基于网格的轨迹来减少恢复的轨迹 𝑇𝑔𝐻′ 和预期轨迹𝑇𝑔𝐻之间的损失。通过这种方式,可以学习到高频轨迹的丰富细节并将其纳入上下文向量,从而增强其表达能力。增强数据分布。学习从轨迹到相应路径的映射是由大量的训练数据驱动的。然而,由于采样成本和存储限制,训练数据有限甚至不足。训练数据的有限大小严重降低了基于学习的模型的性能。在这里,我们通过利用潜在空间中表示向量的分布来增强轨迹表示。通过 seq2seq 模型进行预处理后,低频轨迹被编码为固定维度的上下文向量。它们是分散在高维潜在空间中的点。一旦解码和重建,每个点都可以对应于基于分段的轨迹。由于训练轨迹的大小有限,它们稀疏地分布在潜在空间中,在提供关于通往看不见轨迹的真实驾驶路径的有效线索方面表现不佳。直觉上,这些点的分布应该有一定的规律性。首先,相似的轨迹输入应该被编码为相邻点。其次,解码到相同基于分段的轨迹的点应该在潜在空间中尽可能接近。我们通过添加正则项来规范潜在空间的组织。使用这个正则化项,我们鼓励数据分布接近并保证满足预期的规律性。这种正则化项表示为数据分布和标准高斯分布之间的Kulback Leibler (KL)散度,它强制数据分布接近标准高斯分布。具体来说,采用公式z ∼𝑞𝛼 (z|𝑇𝑔) = 𝑁 (𝝁𝑇𝑔, 𝝈2𝑇𝑔I)推断出z的数据分布,其中𝑞𝛼(z|𝑇𝑔)表示给定轨迹𝑇𝑔从编码器导出的潜在表示,I是单位矩阵,𝝁𝑇𝑔∈R𝐷和𝝈𝑇𝑔∈R𝐷分别是均值和标准差向量。如图 3 所示,𝝈𝑇𝑔= 𝑓1(𝒉𝑛) 和 𝝈2𝑇𝑔 = 𝑓2 (𝒉𝑛), 其中𝑓1和𝑓2是要学习的两个完全连接的前馈神经网络,𝒉𝑛表示生成的轨迹上下文向量𝑇𝑔。轨迹数据记录了用户在城市路网中的出行情况,包含了用户在城市中的出行规律,如常见路线、不同用户群体的偏好等。同时,也隐含了城市道路网络的布局。例如,市内有专用高速公路、环城高速公路和机场高速公路。这种知识已经被含蓄地证明是提高地图匹配质量的有效方法。因此,我们打算识别典型模式,并进一步将其引入到地图匹配中。轨迹可以反映用户在地理空间中的移动模式和道路布局。它们被编码为高维潜在空间中的点。在潜在空间中,相同规律的轨迹对应的点也应具有相同的规律性。假设轨迹数据中隐藏有种𝐾模式,则潜在空间中也会有𝐾种相同规律的类别。我们使用高斯混合分布作为潜在空间上的预期表示分布。它让我们有机会将我们的潜在空间分成多个类,每个类对应一个模式。具体过程如下: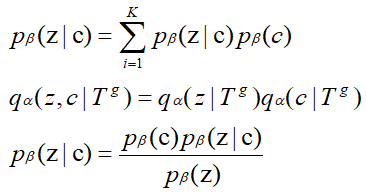
通过下文联合优化方法对模型进行适当的训练,就可以确定潜在表示的高斯混合分布,即找到轨迹中隐藏的潜在模式。同时,轨迹表示在潜在空间的分布被识别的模式规格化。通过这种方式,我们将模式的知识融入到地图匹配中。轨迹匹配与生成是将轨迹表示解码,并将解码后的向量映射到地理空间,依次生成匹配的基于路段的轨迹。如图4所示我们首先从Start Of Sequence输入到End Of Sequence,我们的解码器由RNN 层,注意力层、全连接层和 softmax 层组成,首先利用一个单向GRU对最后标识进行编码,为了提高解码器的性能,注意力层也用于搜索最相关的表示向量,生成自适应上下文向量。然后传输到全连接层以确保正确的形状。最后传输到softmax层来识别匹配的路段,通过具体函数来实现段轨迹到实际地图的映射过程。为了训练L2MM,我们的目标是共同优化L2MM中的三个组成部分,即轨迹表示学习和增强、模式识别和表示以及轨迹匹配和生成。最终我们可以得到最后一个组件可以正确地生成具有潜在表示的基于分段的轨迹,该潜在表示是从通过第一个组件的基于稀疏点的轨迹导出的。同时,对潜在轨迹分布进行正则化和确定,并在潜在空间中发现轨迹背后的模式。我们分别a,b,q来表示三个组件中的参数,之后我们可以将下界写成:目标即为让下式最大化。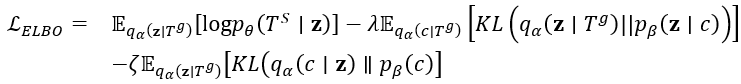
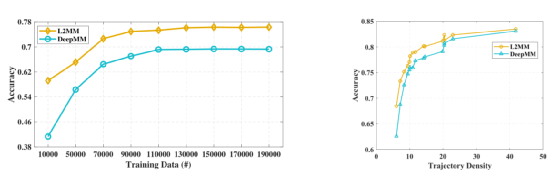
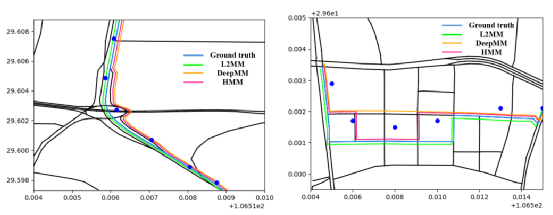
首先我们在不同的数据集上比较L2MM、HMM[2]和DeepMM[1]。三种方法的总体性能如图所示:如图6所示,与 HMM 和 DeepMM 相比,当采样时间间隔超过 60 秒时,L2MM 总体上实现了最佳性能。HMM 的性能急剧下降,而我们的方法性能要好得多,尤其是当采样时间间隔大于 90 秒时。原因是两个连续 GPS 点之间的距离在低频下(例如,采样时间间隔为 135 秒)可能为数公里,导致 HMM 在寻找真实行车路径时存在很大的不确定性。在深度学习模型的帮助下,DeepMM 可以将稀疏的轨迹映射到驾驶路径。当采样时间间隔增加时,所有三个模型的准确度都会下降。尽管如此,与其他两种模型相比,L2MM 的变化要小得多。具体来说,当采样时间间隔从 30s 增加到 135s 时,L2MM 的准确率仅下降了 7%,而 HMM 和 DeepMM 的准确率分别下降了 24% 和 7.6%。该结果验证了 L2MM 对频率降低的表现更加稳健。模型在Porto数据集上的匹配精度优于重庆数据集。这可能是由于不同的噪声水平对两个数据集的影响。如前所述,重庆数据集中的轨迹由粗略的位置估计组成,平均定位误差为 26.7 米。特别是在30s的采样时间间隔下,L2MM和DeepMM的准确率分别降低了6.5%和7.5%,而HMM的准确率降低了10.8%。而且L2MM模型对训练数据的大小更加稳健,在精度方面页具有更强的鲁棒性。如图7所示图7 不同训练数据量下的准确性,不同轨迹密度精度图为了进一步探索L2MM在复杂情况下处理映射匹配的能力,我们以重庆为例,使用两个代表性案例来直观地展示它如何优于基线方法,包括HMM和DeepMM。需要注意的是,路网用黑线表示,原始轨迹用一系列GPS点用蓝色表示,三种地图匹配算法的匹配结果用不同的颜色表示。可以看出我们学习了基于相应高频轨迹的L2MM的高质量轨迹表示。它有助于在这种复杂的情况下找到正确的行驶路径。本文提出了一种基于深度学习的地图匹配模型L2MM,旨在高效地映射低质量的轨迹数据。解决此类低质量GPS轨迹的地图匹配问题对许多应用具有直接而深远的意义。此外,L2MM显式识别潜在空间中的典型移动模式,以探索更一般的启发式提示,并巧妙地将识别的模式合并到地图匹配任务中,以便利用这些提示来促进地图匹配。我们基于一系列数据集进行了大量实验,结果不仅证明了L2MM在精度和效率方面的优势,而且验证了高质量轨迹表示和移动模式的重要性。参考文献
[1]Jie Feng, Yong Li, Kai Zhao, Zhao Xu, Tong Xia, Jinglin Zhang, and Depeng Jin. 2020. DeepMM: Deep Learning Based Map Matching with Data Augmentation. IEEE Transactions on Mobile Computing (2020), 1–13.
[2]Paul Newson and John Krumm. 2009. Hidden Markov Map Matching through Noise and Sparseness (GIS ’09). Association for Computing Machinery, New York, NY, USA, 336–343.
[3]Zhihao Shen, Wan Du, Xi Zhao, and Jianhua Zou. 2020. DMM: Fast Map Matching for Cellular Data. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking (MobiCom ’20). Association for Computing Machinery, New York, NY, USA, Article 60, 14 pages.
[4]George R. Jagadeesh and Thambipillai Srikanthan. 2017. Online Map-Matching of Noisy and Sparse Location Data With Hidden Markov and Route Choice Models. IEEE Transactions on Intelligent Transportation Systems 18, 9 (2017), 2423–2434.
开源Github代码:GitHub - JiangLinLi/L2MM