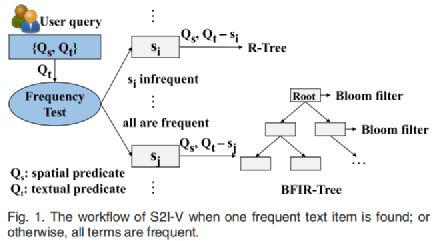
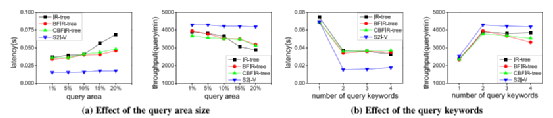
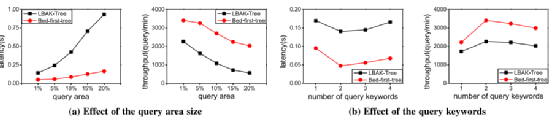
近年来,随着基于位置分析的服务的快速发展,空间关键字查询引起了人们的广泛关注。随着移动电话和基于位置的服务(LBS)的快速发展,每时每刻都在产生大量的空间文本数据,而提供服务的公司则希望能够在海量数据的情况下实现快速响应用户需求。然而,目前的空间关键字技术都是基于磁盘的,因而难以实现低延迟,同时集中式的环境也不能满足高吞吐量要求。故随着数据规模的激增,人们倾向于在分布式内存环境中处理数据,以利用分布式内存技术来实现这些特性(即低延迟、高吞吐量和可伸缩性)。本次为大家介绍发表在CCF A类期刊TKDE上的论文:Xu Y , Yao B , Wang Z J , et al. Skia: Scalable and Efficient In-Memory Analytics for Big Spatial-Textual Data[J]. IEEE Transactions on Knowledge and Data Engineering, 2019, PP(99):1-1.本文提出了一种分布式解决方案,即Skia(空间关键字内存分析)系统,为空间文本分析提供了一个可扩展的支撑。本文重点关注四种空间关键字查询,其定义如下:1. 精确布尔范围查询eBRQ:检索其文本内容包含查询区域中的所有关键字的点。例如检索文本描述准确包含关键字“relish”和“coffee”且位置在查询位置5公里以内的位置。2. 精确的布尔kNN查询eBKQ:检索给定点t的k个最近邻点并得到文本内容覆盖Qt的结果。例如检索k个最接近查询位置的位置,且其查询位置的文本描述完全包含关键字“relish”和“coffee”。3. 近似布尔范围查询aBRQ:检索其文本描述包含类似于“relish”和“coffee”的关键字(例如“rakish”和“bake”),且其位置在查询位置5公里以内的地方。4. 近似布尔kNN查询aBKQ:检索k个最接近查询位置的位置,其文本描述包含类似于“relish”和“cake”的关键字。Skia采用一个两级索引框架来有效地处理常见的空间关键字查询。具体来说,本文提出了新的全局索引(即BFR-Tree和GR-Tree)。所提出的BFIR-Tree将Bloom过滤器与空间索引结构(例如R-Tree)相结合,以支持空间关键字查询,并避免在R-Tree的每层上执行精确的关键字匹配。而动态CBFIR-Tree,它可以在继承BFIR-Tree的强大优点的同时实现增量维护。此外,以往的工作并没有利用不常用关键词的剪枝能力,但其实不常见的关键字可以大大减少对具有多个关键字查询的搜索空间。在此基础上,本文进一步提出了S2I-V索引结构。由于文本数据分析实际上在大多数场景中占主导地位,故文本优先索引在工作中表现出更好的性能,这促使本文提出Bed-first-Tree,这是一个文本优先的索引结构。与以往的文本优先结构相比,Bed-first-Tree能同时利用空间过滤器和文本过滤器的剪枝能力。基于大规模数据集的实验结果表明,Bed-first-Tree比最先进的解决方案具有更好的性能。一、BFIR-TreeIR-Tree是一种通用和有效的用于精确的空间关键字查询结构,它为IR-Tree中的每个节点维护一个倒排文件,并将关键字映射到相应的子节点中,以此利用倒排文件来过滤不相关的子节点,从而减少时间成本。但IR-Tree的每层都使用倒排文件,导致每个关键字将被存储多次,需要巨大的空间成本;其次它在每层都执行精确的文本匹配,但这实际上是不必要的。因此一种集合了IR-Tree和Bloom过滤器的新的索引结构BFIR-Tree被提出,它能在时间和空间上都达到了很高的效率。1. 结构BFIR-Tree的结构类似于R-tree,但是它有两种类型的节点:(1)B-Node是非叶子节点,它维护一个Bloom过滤器的索引,过滤器中抽象出了子节点中对应的文本信息。如果此节点传递空间谓词,我们将使用Bloom过滤器来近似检查该节点是否包含查询关键字。如果没有找到其中任何一个查询关键字,则不会进一步搜索该节点及其相应的子树。(2)I-Node是叶子节点,它存储一个将每个关键字映射到关键字空间对象的倒排列表。基于倒排列表,我们可以验证对象是否满足文本谓词,然后通过计算到查询点的距离来获得最终结果。2. 查询算法对于eBRQ问题Q ={QS= (τ,κ),Qt}(这里的Qt是一组关键字)。在B-Node中,首先检查该节点是否满足Qs,即空间条件。如果它在查询区域中,那么对于Qt中的每个关键字我们都检查它是否在节点的Bloom过滤器中。如果其中一个关键字不被包含在该节点中,则会对节点进行修剪。否则,我们将递归地向下查询。在此过程中,如果它最终到达一个叶节点,便得到一个反向列表,根据反向列表我们就可以取出对应的对象。对于eBKQ问题,可以通过修改基于R-Tree的kNN算法来实现,我们设置一个优先级队列,它通过对象到查询位置的距离从小到大进行排序。但是现在只将传递文本谓词的对象添加到队列中,同时不断将对象退出队列并判断是否符合查询条件,直到最终得到k个结果,或者队列变为空。当我们访问R-Tree的节点时,BFIR-Tree能避免执行精确的文本匹配。本质上,它首先删除不符合条件的子节点,并使用精确匹配验证剩余的候选节点,因此效率较高。此外,它避免了存储冗余的文本信息,从而减少了大量的空间成本。二、CBFIR-Tree上述BFIR-Tree具有较高的空间和时间效率,但它是一个静态结构,因为Bloom过滤器不能处理删除操作。为了解决这一困境,我们使用了计数Bloom过滤器(counting Bloom filter,CBF),并基于此开发了CBFIR-Tree(称为基于CBF的IR-Tree),它可以被视为BFIR-Tree的动态版本。CBFIR-Tree类似于BFIR-Tree,但它增加了一个计数过滤器因此允许我们有效地处理更新,并保留了BFIR-Tree的优势由于CBFIR-Tree和BFIR-Tree之间的相似性,我们只讨论在其中更新信息的算法。增量维护算法给定对象o = (p, γ),我们首先通过R-Tree的选择叶算法(Choose Leaf algorithm)找到要插入的叶节点s。那么则有两种情况:(1)如果s有足够空间插入新对象,那么直接将o插入到s中,并自底向上传递关键字集γ。在传递过程中,对于一个叶节点,我们通过将γ中的每个关键字的映射添加到新条目来重构它的倒排文件。对于非叶节点,我们只需将γ中的每个项插入到相应的计数Bloom过滤器中。(2)如果s没有空间插入新的对象,则需要在叶节点中进行节点分裂,即将插入新对象后的该叶节点分裂成两个节点。我们将重新计算两个新节点的反向列表,并在这两个节点的父节点P中添加一个新条目。如果父节点P不需要分割,我们只需将γ中的每个项插入相应的计数Bloom过滤器中,并自下而向上传递γ。否则,我们将把节点P分成P1和P2。P1和P2的CBF可以从它们的子节点的倒排列表中重建。如果需要分割P的父节点(或更高层次的节点),我们可以通过组合其子节点的CBF来快速重建计数Bloom过滤器。三、S2I-V文本优先结构可以发现上述两种结构都是空间优先结构。而事实上文本数据分析在大多数场景中占主导地位,且空间优先结构利用字符串匹配来修剪不相关的节点,这在遇到频繁出现的文本项(以下简称频繁项)时会导致效率底下,因为我们必须检索许多节点(注意频繁项通常由许多节点拥有)。因此本文提出了一个新的文本优先结构,命名为S2I-V(空间倒排索引变体)。具体地说,S2I-V将频繁出现的关键字项映射到BFIR-Tree,将不频繁项映射到R-Tree(注意频率阈值是手动设置的)。S2I-V用一个Bloom过滤器来确定一个关键字是否频繁。图1显示了S2I-V的工作流程。对于eBRQQ= {QS= (τ,k),Qt},首先使用Bloom过滤器在Qt中找到一个不常见的关键字,然后使用相应的R-Tree来处理新的查询Qnew = {QS= (τ,k),Qremaining}。由于不常见的关键字只属于少数对象,因此可以快速处理新的查询。虽然每个不常见的关键字都映射到自己的R-Tree,但它的空间文本对象数量有限,因此其空间部分的空间代价不是很大。接下来,我们将分别讨论如何处理单个和多个关键字查询。1.单关键字查询。对于单个关键字m,我们直接将m映射到相应的R-Tree(如果m不频繁)或BFIR-Tree(m频繁)。请注意,这里我们只使用空间部分。然后,我们使用在R-Tree执行上圆范围算法和kNN算法来得到结果。2.多个关键字查询对于多个关键字Qt = {μ1...... μn},我们首先寻找一个罕见的关键字μi,如果找到则在该μi的R-Tree中处理新的查询。对于一个eBRQ问题,我们首先使用空间条件Qs来获得候选对象,然后验证这些对象是否包含剩余的关键字。对于eBKQ问题,我们用一个按距离排序的优先级队列来得到包含该罕见查询关键字的k个结果。否则(例如如果没有找到),我们将使用第一个关键字对应的BFIR-Tree来进行查询。四、Bed-first-Tree最新的近似空间关键字查询解决方案都是基于空间的结构。而在大多数情况下,文本数据主导着空间数据,因此基于文本的索引拥有更好的性能。基于此,本文开发了一种新的索引结构,称为Bed-first-Tree。它将频繁关键字映射到R-Tree,以组织包含该关键字的空间文本对象,并将非频繁关键字映射到定位列表(posting list,即包含该关键字的记录列表)。在构造过程中,对于叶节点中的对象,我们计算最小边界矩形(MBR)来表示其空间区域。对于一个非叶节点h,我们将其子节点的MBRs组成一个更大的MBR。如图2所示,Bed-first-Tree是一种结合了空间邻近性和字符串匹配的混合索引结构。通过这种方式,Bed-first-Tree可以避免许多不必要的字符串匹配,与现有的基于文本的字符串匹配相比,这进一步节省了成本。1.aBRQ问题对于aBRQ问题,首先访问Bed-first-Tree以检索每个查询关键字的候选项,在检索过程中,对于非叶节点,我们首先计算从查询点到该点MBR的距离以此确定它是否在查询区域内,然后,我们利用字符串匹配的剪枝能力来选择可能的子节点。如果到达叶节点,则访问相应的发布列表或匹配字符串的R-Trees来运行范围测试来得到结果。通过计算每个查询关键字的中间结果的交集便可以得到最终的结果。2.aBKQ问题对于该问题,如果只有单个关键字,我们可以首先找到其每个相似关键字(如{K1;K2;……;Kn})的k个最近点集。然后,我们在{K1;K2;……;Kn}的并集中搜索kNN集。对于多个关键字,由于一个特定关键字的k个最近点可能不包含其他查询的关键字,则该情况更加复杂。为了更好地支持多个关键字的查询,我们利用LBAK-Tree来处理多个关键字的情况。由于LBAK-Tree是R-Tree的变体,我们可以使用优先队列对对象排序,这些对象在LBAK-Tree中通过文本过滤。这类似于我们通过BFIR-Tree处理精确布尔kNN查询问题的方式。五、实验本文在实验中使用了两个真实的数据集:(1)OSM数据集,包含3000万条记录。空间部分从OSM项目中获得,由二维坐标组成。每个点都使用从SNAP收集的文档中提取的字符串进行扩充。(2)TX-CA数据集,包含2600万点,这些点代表了德克萨斯州和加州真实的路网和街道。我们将每个点与它的州、县和镇名称作为关联字符串。我们主要关注两个指标来评估性能,即吞吐量和延迟。延迟是通过启动10个线程,连续地发出查询,每次共测试500个查询,计算平均延迟所得。吞吐量是通过每分钟处理的请求数来衡量的。对于查询生成,我们从给定的数据集中随机选择一条记录,并使用该点作为查询位置。索引结构之间的比较为了比较本文提出的索引结构在分布式环境中的性能,首先,我们为精确空间关键字查询改变查询参数,并观察每个索引结构的性能。然后,我们对近似空间关键字查询进行比较。1. eBRQ查询图3a显示了改变查询区域占整个区域百分比时效果。这四种结构的性能都出现了相当缓慢的下降,较大的查询区域带来了更高的成本,但由于字符串谓词的额外剪枝能力,成本只会略有增加。此外我们提出的索引比IR-Tree具有更好的可扩展性和性能,且S2I-V结构实验发现,查询区域大小对查询效率影响较小。图3b说明了查询关键字个数的影响。BFIR-Tree的性能和IR-Tree一样好,但它在空间开销上优于IR-Tree。此外,当关键字数量增加时,S2I-V表现最好,这是因为S2I-V可以利用对不频繁项剪枝来提高效率。图3.TX-CA数据集上eBRQ索引结构的比较2. eBKQ查询图4显示了eBKQ查询的性能。我们将k从1变化到20,发现随着k增加四种索引结构的性能都略有下降,但相比IR-Tree性能都有一定提升。图4. TX-CA数据集上eBKQ索引结构的比较3. aBRQ查询图5a显示了查询区域大小的影响。可以看出当查询区域很小时,Bed-first-Tree的性能优于LBAK-Tree。而当查询区域扩大时,Bed-first-Tree更具扩展性和稳定性。图5b显示了查询关键字多少的影响。随着查询关键字数量的增加,两者的性能首先不断增长,然后又不断下降。这可能是因为,查询会检索更多只分配一个查询关键字的结果。当分配了两个查询关键字时,一些节点变得不相关,因此访问次数减少,从而导致成本更小。然而,当查询关键字的大小继续增加时,近似字符串搜索的成本将成为主要问题。因此,当关键词个数大于2时,性能有下降的趋势。图5.OSM数据集上aBRQ索引结构的比较。结果表明,与最先进的技术相比,本文提出的索引和分布式解决方案实现了优越的性能。思考本文尝试使用Bloom过滤器在Qt中找到一个罕见的关键字并执行查询,由于不常见的关键字只属于少数对象,因此可以快速处理新的查询。但是不同的空间范围下关键字出现的频率肯定是不一样的,而本文中是以整个空间出现的频率作为判断的标准,但可能整个空间中出现次数少的在查询空间内相对于其它关键字可能反而比较频繁,因此可以优化的一点是分不同区域判断相应出现频率较小的关键字。