




今天下午的北京风和日丽,正当本人陷入无限的报表需求中不可自拔时,叮的一声,打断了我的思绪。一位开发leader发来消息,有个SQL需要紧急优化,由于该SQL影响的服务波及到同步支付数据业务,优先级直接拉到MAX!
进入正题,以下是SQL:
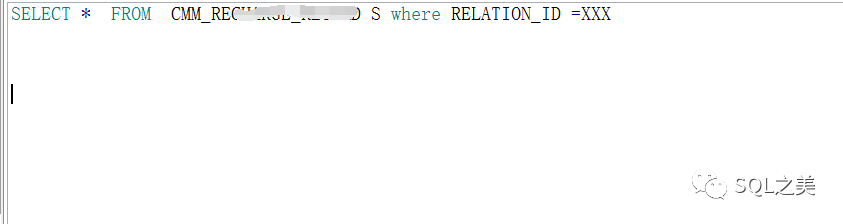
非常之简单,这位leader还是有些经验的,直接就要给RELATION_ID字段建立索引,那当然不能这么鲁莽。 这种时候进入咱们日常第一步:
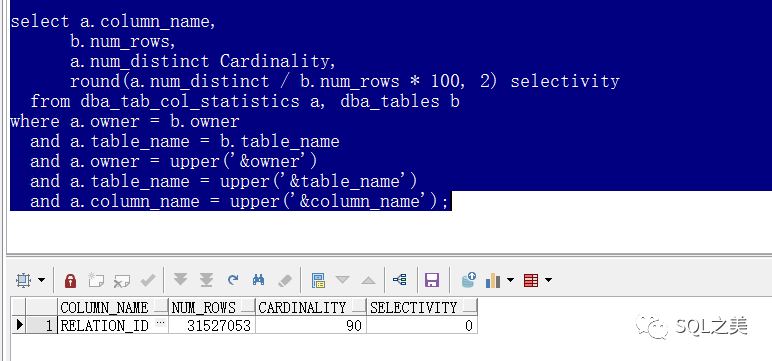
什么!3000W+的大表,才90个不同值,选择率近乎为0,这怎么能建立索引呢?
果断拒绝了leader的建议,并直说 这一个字段对应结果集几百万,就是这么慢,无法优化,想快必须加条件减少结果集!
然而,leader告诉我不会,一个relation_Id只对应一条数据
那不能够,现在只有两个可能,1统计信息不准,2研发骗我。。鉴于这些可能性,咳咳 我进行了以下测试:
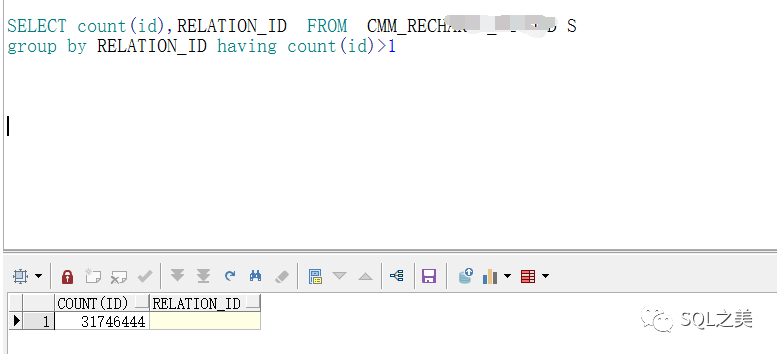
大意了啊!竟然存在3000多万空值,果然不能太经验主义,进一步确认需求,这个字段以前是空的,最近开始加入数据,历史的不管,新数据都会有对应的值,跟主键一一对应:
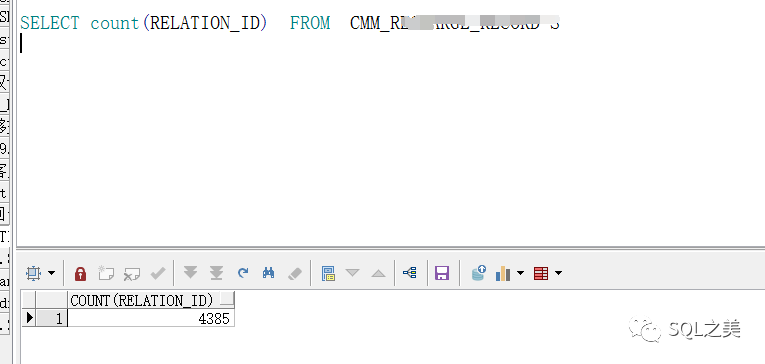
这个字段累计有值的只有4385条。那么得出结论:
可以建立索引,然后习惯性建立索引:

本以为就这样OVER了,然而又一次失误。。这里他有时候还是会用到查询RELATION_ID字段为空的数据,然后3000多万字段空值回表,直接给程序卡死了。。大意了,再次进行调优,去掉0
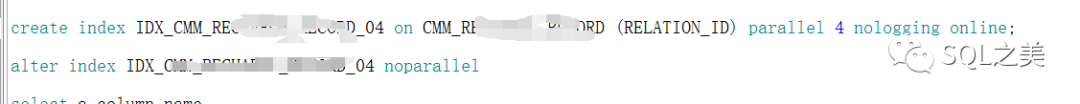
同时 去掉并行
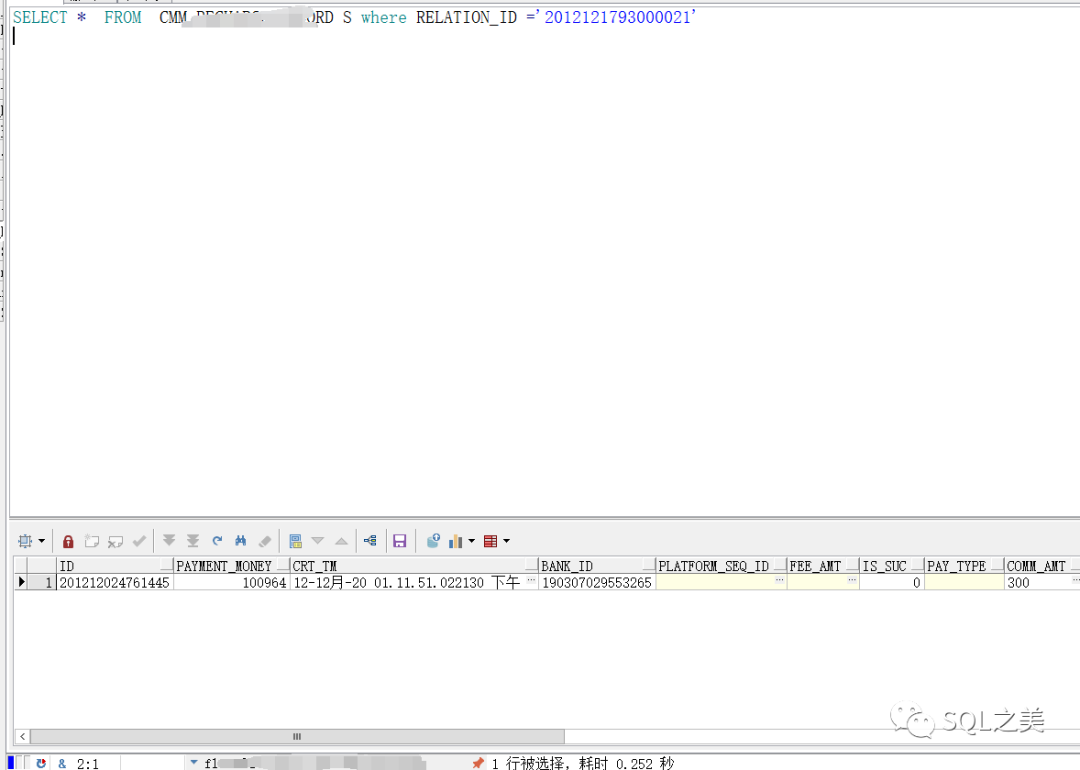
如此之完美,利用oracle 正常索引 null值不走索引 有值走索引的特性,顺利完成本次优化,成功挽救自己之前武断的失误之处。
附加效果:经历这次有波折的优化过程,leader同学对我的形象有了一点增大效果,真是 自古好感难自增,唯有套路得人心。
文章转载自SQL之美,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
