




一 什么是 词云图
词云图可以看作是文本数据的视觉表示,由词汇组成类似云的彩色图形。相对其它诸多用来显示数值数据的图表,词云图的独特之处在于,可以展示大量文本数据。文本数据中每个词的重要性以字体大小或颜色显示,因此词云可以很好地表明每个单词在特定文本体中被提及的频率(即词频分布),通过使用不同的颜色和大小来表示不同级别的相对显着性。
本文将介绍如何用python代码制作中文的词云图。基本原理就是利用分词工具将文章/目标文件进行分词,以此作为输入,然后利用词云工具库,比如 wordcloud 对高频词进行统计加工,去掉干扰词汇,将结果绘制一张图片。
二 使用 python 代码实现
2.1 首先下载相关的库
基于上面的原理,我们需要借助开源的库,
jieba 负责分词
wordcloud 负责对分词的结果做统计生成图片
matplotlib 用于显示图片
想了解关于词云的详细信息可以去看 https://github.com/amueller/word_cloud
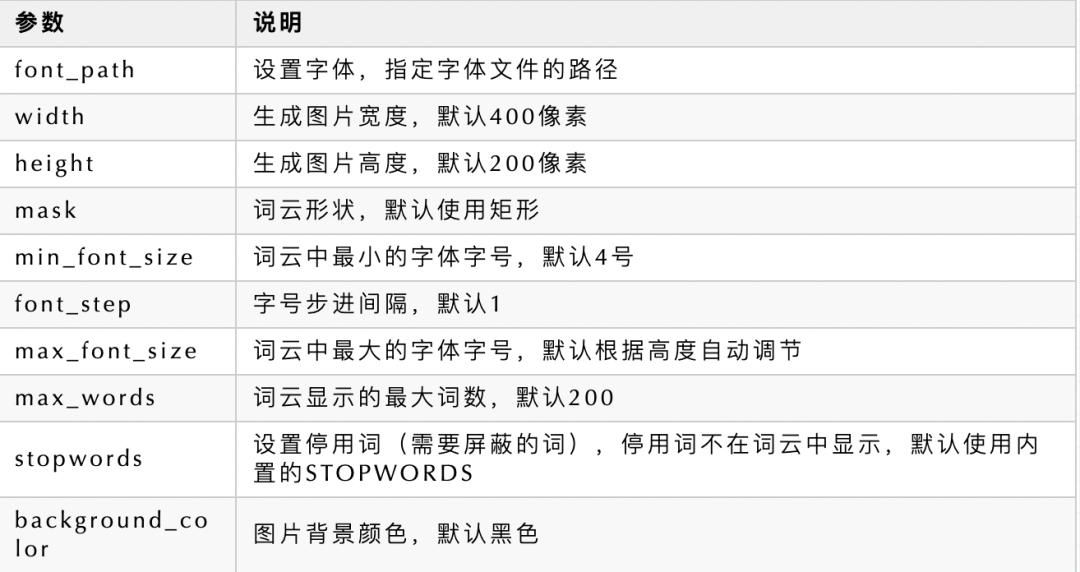
WordCloud对象常用参数
wordcloud是主要是针对 英语字符的,我们的素材是中文,所以还需要 jieba 这款比较优秀的中文分词工具。
2.2 安装使用
构造python开发环境并安装依赖
virtualenv word_cloud
source ~/python/py_game/bin/activate
cd python_cloud
**推荐使用如下命令下线所需要的依赖**
pip3 install numpy matplotlib pillow wordcloud imageio jieba snownlp itchat -i https://pypi.tuna.tsinghua.edu.cn/simple
2.3 代码实现
import jieba
import collections
import imageio.v2 as imageio
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
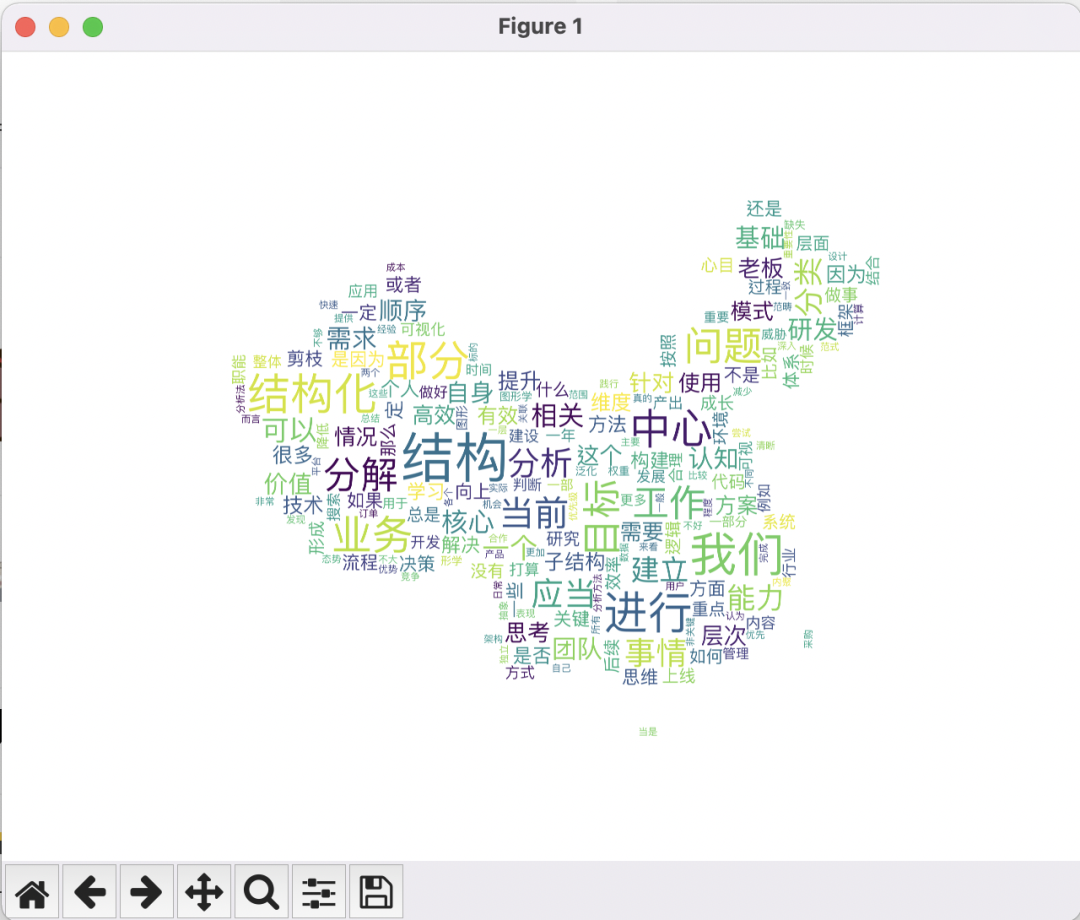
## 选取一张中国的矢量图片
mk = imageio.imread("china.png")
w = WordCloud(mask=mk)
## data.txt 是中文文本 ,二十大的部分报告
with open('data.txt') as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('stop_words.txt', encoding='utf-8') as f:
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
# 设置停用词并去除单个词
if word not in stop_words and len(word) > 1:
result_list.append(word)
#print(result_list)
# 筛选后统计
word_counts = collections.Counter(result_list)
# 获取前100最高频的词
word_counts_top100 = word_counts.most_common(250)
#print(word_counts_top100)
# 绘制词云
my_cloud = WordCloud(
background_color='white', # 设置背景颜色 默认是black
width=1000,
height=800,
max_words=200, # 词云显示的最大词语数量
font_path='PingFang.ttc', # 设置字体 显示中文
max_font_size=90, # 设置字体最大值
min_font_size=16, # 设置子图最小值
random_state=50, # 设置随机生成状态,即多少种配色方案
mask=mk,
scale=15
).generate_from_frequencies(word_counts)
# 显示生成的词云图片
plt.imshow(my_cloud, interpolation='bilinear')
# 显示设置词云图中无坐标轴
plt.axis('off')
plt.show()
其中 stop_words.txt 是过滤词汇,比如: 强调,所以,进一步,的 ,指出 这些无业务逻辑含义的词汇。
其实这里的图片和文字可以换成其他的人像 ,某些人的演讲稿,大家可以基于代码丰富自己的测试案例。
2.4 测试结果

文章转载自yangyidba,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
