




背景
某医院客户频繁反馈一个异常现象,就是用于同步业务数据库Oracle数据的Flink CDC作业经常因异常自动重启。虽然开启chekpoint能够确保数据一致性,但是会造成很大的数据延时。
问题分析
客户现场属于内网环境,没有远程操作的权限,仅提供异常日志照片。

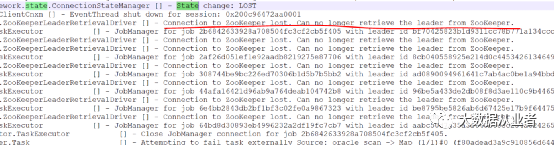
以上两张图可以看出,JobManager与Zookeeper之间的连接状态发生变更,由正常情况下的CONNECTED状态变成SUSPENDED/LOST。通过源码中查找上述红线日志,可以定位到
flink\flink-runtime\src\main\java\org\apache\flink\runtime\leaderretrieval\ZooKeeperLeaderRetrievalDriver.java
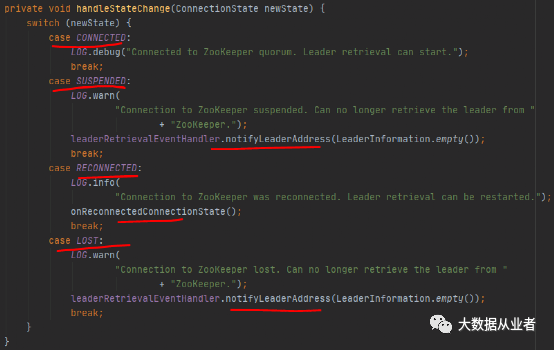
以上代码可以看出Flink处理Zookeper连接的四种状态(CONNECTED、SUSPENDED、RECONNECTED、LOST)。其中,SUSPENDED和LOST状态均被认为是连接不可用、主动触发Leader信息变更、主动重启task任务。
我们知道,Flink通过flink-shaded项目的子项目flink-shaded-zookeepr与Zookeeper进行交互。而flink-shaded-zookeepr项目又通过apache curator项目实现与Zookeeper的交互。
Curator源码ConnectionState定义了上述状态枚举类型。
curator\curator-framework\src\main\java\org\apache\curator\framework\state\ConnectionState.java
其中,SUSPENDED和LOST的描述信息如下:
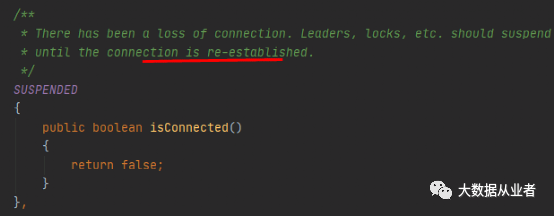
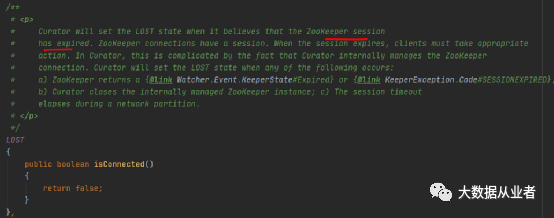
以上两图可以看出,SUSPENDED状态是短暂连接不可用、能够自动重连恢复;而LOST状态是连接不可用。所以,LOST状态触发leader信息变更通知、重启task作业,无可厚非。但是,SUSPENDED状态这么处理就有些不合适,尤其是网络状况不那么理想的场景;连接明明可以自行恢复不影响task执行,没必要触发leader信息变更通知、重启task作业。
尤其是作业task实时性要求高的场景,总是在SUSPENDED状态重启task会造成实时处理延迟增加,更有甚者,task不停的重启,几乎不干活。
注意:curator中定义的这四种状态并不是直接来自于zookeeper watcher KeeperState枚举类;而是curator自身抽象设计而来。至于两者之间的映射关系,这里不再继续深究。
解决方法
根据上述问题分析的结果,解决措施简单粗暴:直接删除SUSPENDED逻辑
leaderRetrievalEventHandler.notifyLeaderAddress(LeaderInformation.empty());
毫无疑问,修改后的flink-dist_2.12-1.13.6.jar更新到现场,世界都安静了。
后续
关于这个问题,Flink master分支也给出类似的修改方案。不过,不是直接删除。而是通过新增一个配置参数,将选择权丢给用户,由用户自行决定是否需要SUSPENDED状态重启作业。
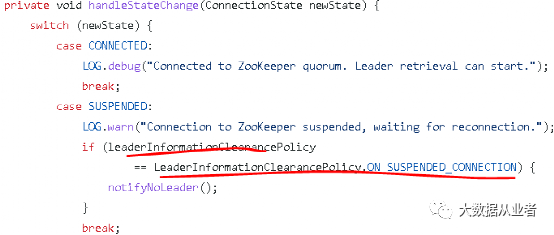
配置参数:
high-availability.zookeeper.client.tolerate-suspended-connections
参数描述:
Defines whether a suspended ZooKeeper connection will be treated as an error that causes the leader information to be invalidated or not.In case you set this option to true, Flink will wait until a ZooKeeper connection is marked as lost before it revokes the leadership of components.This has the effect that Flink is more resilient against temporary connection instabilities at the cost of running more likely into timing issues with ZooKeeper.
