




背景
Kafka社区终于完成开发KRaft替换Zookeeper的大特性,该特性耗时三年、历经14个版本,终于在3.3.1版本具备生产可用的级别。秉着知其然知其所以然的精神,本文对其追根溯源、一探究竟!
为什么干掉Zookeeper?
我们知道Kafka集群由多个broker节点组成,每个集群都会从broker节点选出一个controller节点。Controller节点通过创建Zookeeper临时节点及watcher监听机制选取,该节点不仅要与其他broker节点一样去保存数据logs文件、处理topic生产/消费请求,还要维护集群元数据,如:broker IDs、机架信息、topic/partition/leader/isr信息、集群级别和Topic级别的配置信息、安全认证相关凭据等等。如下图所示:上述集群元数据信息都由controller节点与Zookeeper交互完成。
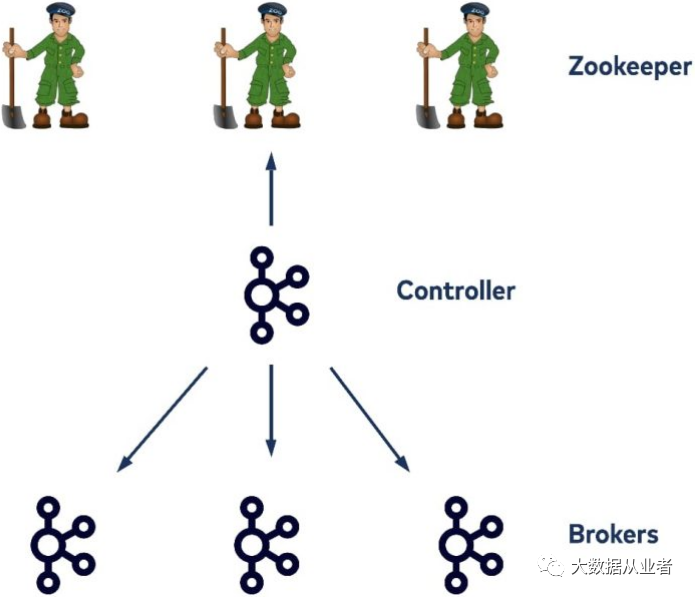
当然上图并不是十分精确,除了controller节点直接与Zookeeper交互,非controller节点也会时不时的直接与Zookeeper交互,比如当非controller节点上的leader更新ISR列表。简单总结如下:controller节点通过注册Zookeeper watchers监听所有集群元数据变更;而元数据的变更是由controller节点、非controller节点、client触发的。一旦controller节点监听到变更的元数据信息,会将其广播给所有的非controller节点。
熟悉Kafka早期版本的用户可能知道,当时消费者可以直接与Zookeeper交互(如读写offset),如今已经被直接与broker节点交互所替换。这么做的主要目的就是为了减少Zookeeper的读写负载。
但是,即便现在大多数场景只有controller与Zookeeper交互,随着Kafka集群Topic、Partition数量的增加,Zookeeper的读写性能仍然会成为controller水平扩展不可逾越的性能瓶颈。具体限制因素可以详看如下三个小节:
1.限制Broker停止过程
假设一个Topic(单分区、三副本、副本均ISR)。如下图所示,最左边的broker节点为该分区的leader节点,该节点现在需要停止,它会发送request请求给controller节点。Controller节点需要确认该broker节点当前管理的topic/partition信息、需要为partition选取出新的leader节点、需要更新集群元数据信息持久化到Zookeeper、需要将新的集群元数据信息广播发送给所有broker节点。所以,controller节点有两种类型request请求:UpdateMetadata(广播新的集群元数据)、LeaderAndISR(更新特定partition的新leader和ISR列表)。
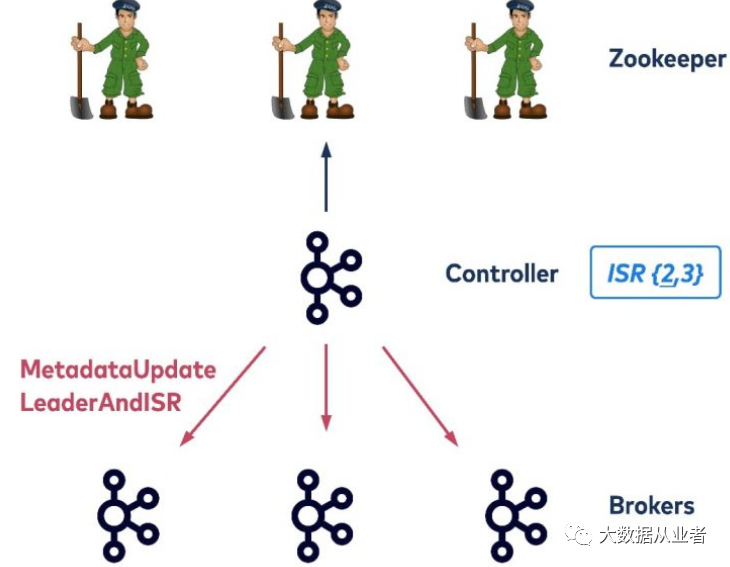
只有controller节点将该broker节点持有的所有topic/partition转移完成,才允许该broker退出。上述例子该broker节点只有一个partition。但是,实际情况需要停止的broker节点可能持有数千个partition;相应地,controller节点需要更新数千个partition变更更新集群元数据信息到Zookeeper,耗时达到数秒甚至更长。另外,controller节点需要广播发送给所有broker节点数千次partition分区的leader和isr信息。这些都可能造成client生产和消费请求超时。
2.限制Controller恢复过程
假如controller节点异常退出(机器宕机/网络不可达/磁盘故障等),注册在Zookeeper来的临时节点会删除,相应的watcher监听会触发,其他所有broker节点会被通知。一旦收到通知,其他所有broker节点都将尝试在Zookeeper创建临时节点以竞选controller。新的controller节点首先从Zookeeper拉取集群元数据信息,然后更新已退出节点所持有的topic/partition信息,并重新持久化到Zookeeper,最后广播集群元数据信息给所有broker节点。
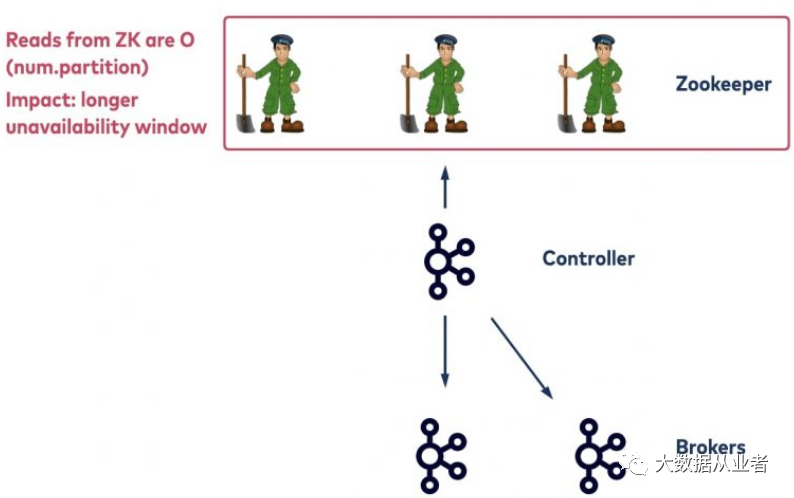
上述过程的瓶颈在于新controller从Zookeeper读取集群元数据信息的耗时时间,该耗时时间与当前集群所有的topic/partition数量成线性关系(数量越大、耗时越长)。这段时间之内,新controller不能处理任何admin request请求,如分区均衡。这意味着集群长时间不可用。
3.其他限制
除了上述较大数量topic/partition造成读写Zookeeper耗时长之外,也有其他的限制因素:Zookeeper node大小、Zookeeper watcher数量等;还有就是安全性、升级方便、调试简单等方面。简化一个分布式系统的架构,也有利于系统自身的稳定性和长久性。
总结
本文作为Kafka为什么使用Kraft替换Zookeeper主题的第一篇文章,主要介绍kafka为什么要替换Zookeeper。至于为什么要用Kraft替换呢?详见下一篇文章。
