




1.数值类型及其解释
| 类型名称 | 存储尺寸 | 描述 | 范围 |
|---|---|---|---|
| smallint | 2 字节 | 小整型 | -2的15次方 至 2的15次方-1 |
| integer | 4 字节 | 整型 | -2的31次方至2的31次方-1 |
| bigint | 8 字节 | 长整型 | -2的63次方 ~ 2的63次方-1 |
| decimal | 变长 | 用户指定精度,精确 | 小数点前131072位,到小数点后16383位 |
| numeric | 变长 | 用户指定精度,精确 | 小数点前131072位,到小数点后16383位 |
| real | 4 字节 | 可变精度,不精确 | 6位十进制精度 |
| double precision | 8 字节 | 可变精度,不精确 | 15位十进制精度 |
| smallserial | 2 字节 | 小范围自增整数 | 1至32767 |
| serial | 4 字节 | 自增整数 | 1 ~ 2的31次方 -1 |
| bigserial | 8 字节 | 大范围自增整数 | 1 ~ 2的63次方-1 |
1.1.整数类型
整数类型分三种:smallint、int、bigint。
Postgresql中最常用的是int类型,它提供了在范围,存储空间、性能之间的平衡。一般磁盘紧张会使用smallint,在int范围不足时用bigint类型。
SQL语句中 int、integer和int4是等效的,smallint和int2是等效的,bigint和int8是等效的,也就是说在创建表时,指定字段的类型可以用简写表示,便于编写SQL语句。
1.2.精确的小数类型
精确的小数类型可以用numeric、numeric(m)、numeric(m,n)表示。
numeric和decimal是等效的。可以存储1000位精度的数字,它的语法是:
numeric(precision, scale)
precision必须位正数,规定了小数点前有几位。
scale可以是零或者正数,规定了小数点后有几位。
numeric(m)表示了scale是0,与numeric(m,0)的含义相同。
而numeric表示precision和scale没有指定,可以存储任意精度和标度的数值。
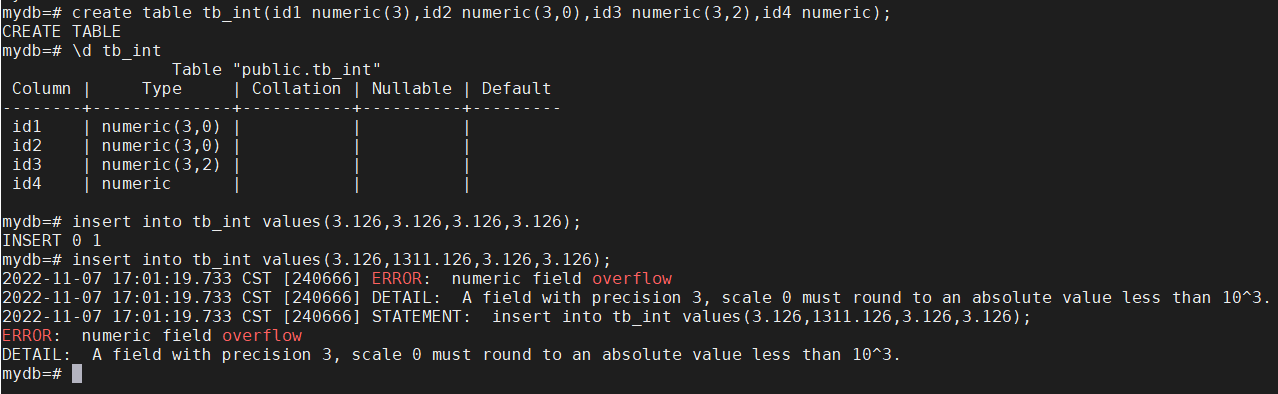
声明了精度(precision)没有声明标度(scale),超出精度的会按照四舍五入取值。同样,声明了标度时,超出标度的会按照四舍五入取值
1.3.浮点数类型
数据类型real和double precision 是不精确的、变精度的数字类型。
对于浮点数,需要注意:
(1)如果需要精确计算,应用numeric类型。
(2)两个浮点数类型的值做比较时,结果可能不是所想象的那样运行。
(3)infinity、-infinity、NaN分别表示正无穷大、负无穷大、非数字。
1.4.序列类型
序列类型中,serial和bigserial与MySQL中的自增字段是同样性质,在Postgresql中是通过序列(sequence)来实现的。
mydb=# create table tb_serial(id serial);
CREATE TABLE
mydb=# \d+ tb_serial
Table "public.tb_serial"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
--------+---------+-----------+----------+---------------------------------------+---------+-------------+--------------+-------------
id | integer | | not null | nextval('tb_serial_id_seq'::regclass) | plain | | |
Access method: heap
例子中创建了一个表 tb_serial ,它的id列位serial类型,创建后查询表属性,显示id默认的是通过序列赋值,并且可以看到除了表之外还同时创建了一个名字位tb_serial_id_seq的序列。
所以create语句就相当于一下几个语句同时执行:
create sequence tb_serial_id_seq;
create table tb_serial(
id integer NOT NULL DEFAULT nextval('tb_serial_id_seq')
);
alter sequence tb_serial_id_seq OWNED BY tb_serial.id;1.5.货币类型
货币类型(money type)可以存储固定小数的货币数目,精度准确。查询时输出的格式跟数据库中的参数:lc_monetary的设置有关,不同国家的货币输出的格式时不一样的。
mydb=# show lc_monetary;
lc_monetary
-------------
en_US.UTF-8
(1 row)
mydb=# select '2233.13'::money;
money
-----------
$2,233.13
(1 row)
mydb=# set lc_monetary='zh_CN.UTF-8';
SET
mydb=# select '2233.13'::money;
money
------------
¥2,233.13
(1 row)2.数据库字符串类型
| 类型 | 描述 |
|---|---|
| character varying(n) 或 varchar(n) | 变长字符串类型,最大空间1GB,存储空间4+实际的字符串长度。与MySQL中的varchar(n)或text(n),以及Oracle中的varchar2(n)类似,但是在MySQL中varchar最多只有64KB,Oracle中的varchar2最多只有4000字节。 |
| character(n)或char(n) | 定长字符串类型,不足空白补充。最大1GB,存储空间4+n |
| text | 变长字符串类型。无长度限制,与MySQL中的LONGTEXT类似 |
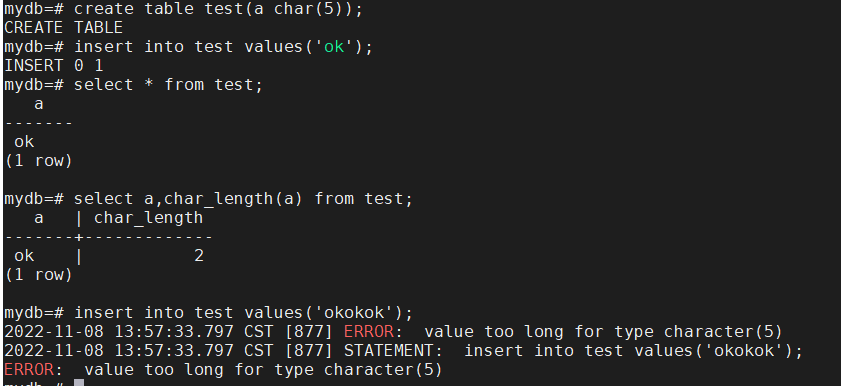
varchar(n) 在没有指定 n 的值时,表示可以接受1GB内的任何长度的字符串,建议加上 n
char(n) 在没有指定 n 值时,表示 char(1) ,
不管varchar还是char类型最小存储空间时4字节。而在Postgresql数据库中varchar和char指定长度过长时,实际在字段中存储的可能只是一个指针,具体内容会存储在toast表中,指针便于对字段值的快速访问。
在一些其他种类的数据库中定长的char有一定的优势。但是在postgresql中没有什么差别。大多数还是会用varchar或text。
3.二进制类型
| 名字 | 存储尺寸 | 描述 |
|---|---|---|
bytea | 1或4字节外加真正的二进制串 | 变长二进制串 |
二进制串是一个八位位组(或字节)的序列。 二进制串和字符串的区别有两个:
首先,二进制串明确允许存储零值的字节以及其它“不可打印的”字节(通常是位于十进制范围32到126之外的字节)。 字符串不允许零字节,并且也不允许那些对于数据库的选定字符集编码是非法的任何其它字节值或者字节值序列。
第二,对二进制串的操作会处理实际上的字节,而字符串的处理和取决于区域设置。
简单说,二进制字串适用于存储那些程序员认为是“裸字节”的数据,而字符串适合存储文本。
4.日期/时间类型
| 名字 | 存储空间 | 描述 | 例子 |
|---|---|---|---|
timestamp [ (p) ] [ without time zone ] | 8字节 | 显示日期加时间 | 2020-02-23 12:00:00 |
timestamp [ (p) ] with time zone | 8字节 | 显示日期、时间加时区 | |
interval [ fields ] [ (p) ] | 12字节 | 时间间隔 | |
| date | 4字节 | 只用于日期 | |
| time [ p ] [ without time zone ] | 8字节 | 只用于1日内时间,不带时区 | |
| time [ p ] with time zone | 8字节 | 只用于1日内时间,带有时区 |
4.1.日期输入
在SQL中,任何日期或时间的文本输入需要有 ’ 日期/时间 ‘ 类型加单引号包围的字符串组成,语法:
type [ ( p ) ] ’ value ’
日期和时间的输入几乎可以是任何合理的形式,在PG中有系统参数 datestyle 决定是什么格式或形式,如下:
mydb=# show datestyle;
DateStyle
-----------
ISO, MDY
(1 row)
其中 “ MDY ” 表示 月-日-年
在数据库中参数可以设置成 YMD 的形式,但在使用语句插入时,用了date转换格式输入,参数设置那种格式没有影响,都可以进行插入成功。
mydb=# show datestyle;
DateStyle
-----------
ISO, MDY
(1 row)
mydb=# create table tb_date(a timestamp);
CREATE TABLE
mydb=# insert into tb_date values(date '02-23-2020');
INSERT 0 1
mydb=# insert into tb_date values(date '2020-02-23');
INSERT 0 1
mydb=# select * from tb_date ;
a
---------------------
2020-02-23 00:00:00
2020-02-23 00:00:00
(2 rows)
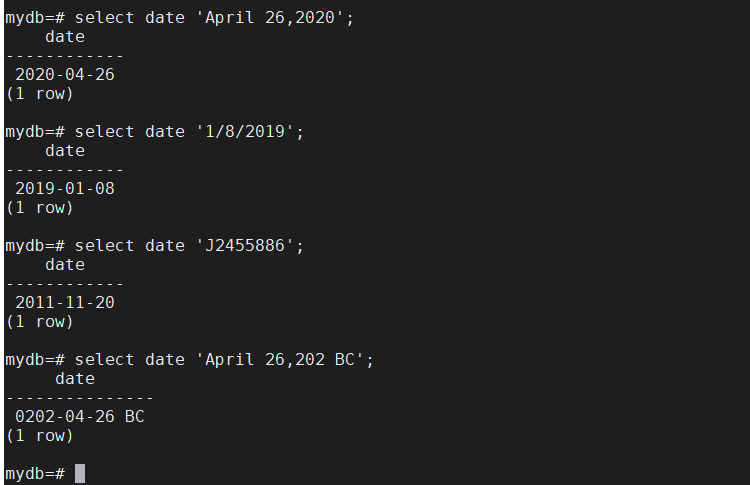
但是有时候日期输入习惯使用诸如此类 ’ 1/8/2020 ‘ 的格式,类似这种各位月或日没有0做前缀时要注意参数 datestyle 的值,防止日期混乱或者插入错误。
| 例子 | 描述 |
|---|---|
date 'April 26,202 BC' | 公元前202年4月26日 |
date 'J2455886' | 儒略日,即从公元前4713年1月1日期到今天经过的天数,多为天文学家使用,2455886天,就是2011年11月20日 |
date '1/8/2019' | 在datestyle为 MDY 时,表示2019年1月8日,在datestyle为 DMY 时,表示2019年8月1日,类似输入日期文本时没有在一位数月份或日前加前缀0的输入方式一定要注意 datestyle 参数的格式,凡是日期混乱 |
date 'April 26,2020' | 在任何datestyle参数值下都没有输入问题 |
对于国内的程序员来说,避免使用 ’/’ 进行日期的输入,,最好使用 ‘-’ 来进行日期文本分割,然后使用 YMD 也就是 年-月-日的格式输入日期。
4.2.时间输入
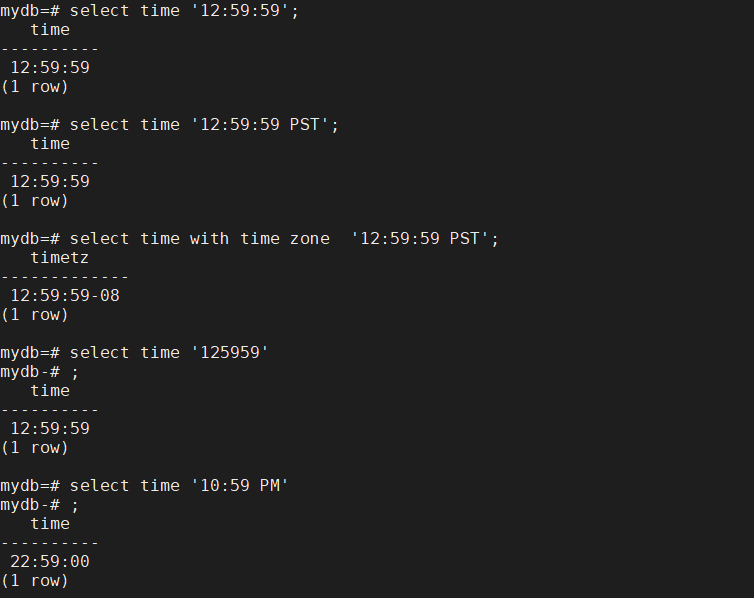
时间输入时,要注意时区的输入,time 被认为时 time without time zone 的类型,所以即使输入的字符串中有时区,也会被忽略,例如:
mydb=# select time '12:59:59';
time
----------
12:59:59
(1 row)
mydb=# select time '12:59:59 PST';
time
----------
12:59:59
(1 row)
mydb=# select time with time zone '12:59:59 PST';
timetz-------------
12:59:59-08
(1 row)
时间输入时字符串之间使用冒号作为分隔符,输入格式为: ‘ hh:mm:ss ’,如:‘ 12:59:59 ’,也可以不使用分隔符,如:‘125959’ 表示 12时59分59秒。
更多的时间输入示例如下:
| 例子 | 描述 |
|---|---|
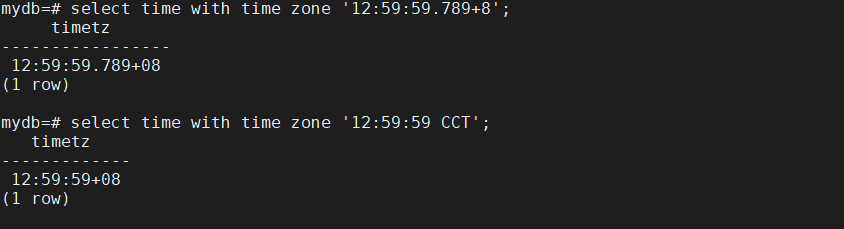
time with time zone '12:59:59 CCT' | 带有缩写的时区,北京时间12:59:59 |
time with time zone '12:59:59.789+8' | 带有时区 |
time '10:59 PM' | 使用PM时输入的小时的值小于等于12 |
time '12:59:59' | ISO 8601 |
time '12:59:59 PST' | ISO 8601 |
time '125959' | ISO 8601 |
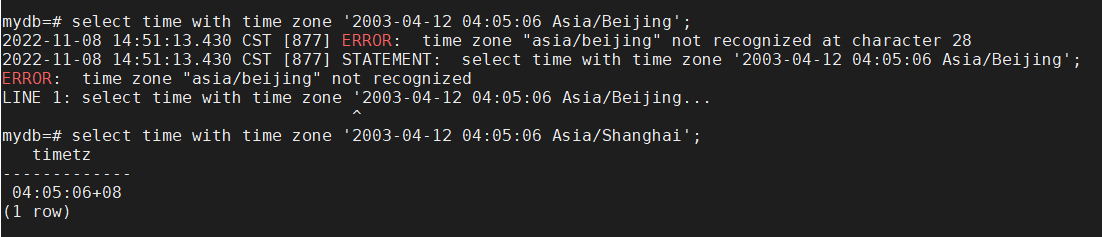
time with time zone '2003-04-12 04:05:06 Asia/Shanghai' | 用具体名字声明时区 |
建议在输入时区时不适用缩写表示,相同的缩写代表的可能时不同的时区。
4.3.特殊时间的字符串
在Postgresql中有一些特殊的字符串输入表示了特别的意义,如下:
| 输入串 | 合法类型 | 描述 |
|---|---|---|
epoch | date, timestamp | 1970-01-01 00:00:00+00(Unix 系统的零时) |
infinity | date, timestamp | 比任何其他时间戳都晚 |
-infinity | date, timestamp | 比任何其他时间戳都早 |
now | date, time, timestamp | 当前事务的开始时间 |
today | date, timestamp | 今日午夜 (00:00) |
tomorrow | date, timestamp | 明日午夜 (00:00) |
yesterday | date, timestamp | 昨日午夜 (00:00) |
allballs | time | 00:00:00.00 UTC |
5.布尔类型
在Postgresql数据库中Boolean的值除了“true”(真)、“false”(假),还有一个“unknown”(未知)状态。
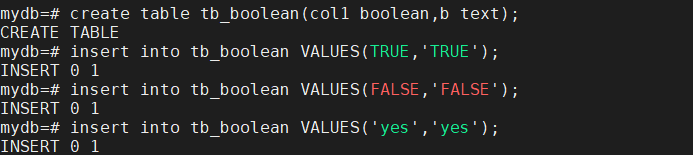
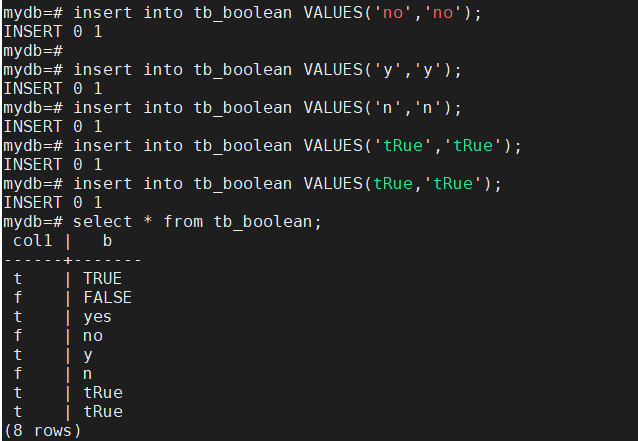
如果是unknown时用NULL表示。布尔类型在Postgresql中可以用不带引号的TRUE或FALSE表示,也可以用更多表示真和假的带引号的字符表示:
| 真 | 假 | 备注 |
|---|---|---|
| 'TRUE' | 'FALSE' | |
| TRUE | FALSE | |
| 'tRue' | 'fAlse' | 不分区大小写 |
| 't' | 'f' | 单一字符表示 |
| 'yes' | 'no' | 英文的是和否表示 |
| 'y' | 'n' | yes和no的简写表示 |
| '1' | '0' | 1表示true,0表示false |
6.枚举类型
PG数据库中的枚举类型不能直接使用,在使用前要先创建枚举类型,create type 命令创建枚举类型。
例如:
mydb=# create type week as enum('Sun','Mon','Tues','Wed','Thur','Fri','Sat');
CREATE TYPE
mydb=# create table tb_duty(person text, weekday week);
CREATE TABLE
mydb=# insert into tb_duty values('Zhang','Sun');
INSERT 0 1
mydb=# insert into tb_duty values('Li','Mon');
mydb=# select * from tb_duty ;
person | weekday
--------+---------
Zhang | Sun
Li | Mon
(2 rows)
如果插入tb_duty表的weekday列中的值没有在枚举类型week中则会报错:

枚举类型中指定的值大小写敏感!!!匹配时值必须完全一致!!
如果想查询tb_duty表中枚举类型的定义,如下:
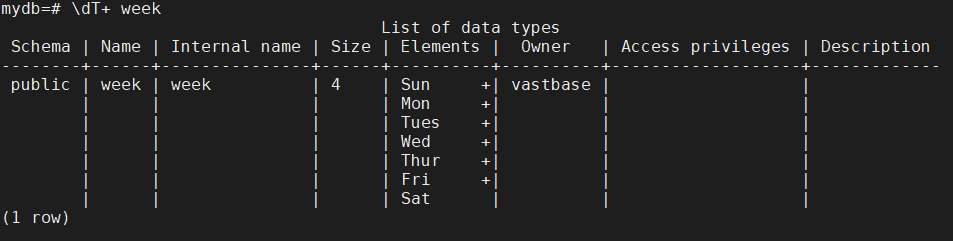
在枚举类型中,定义的值的顺序是在创建此枚举类型week时已经定义好的顺序,而标准的运算符或者相关的聚集函数都可以对枚举类型就行操作。例如:
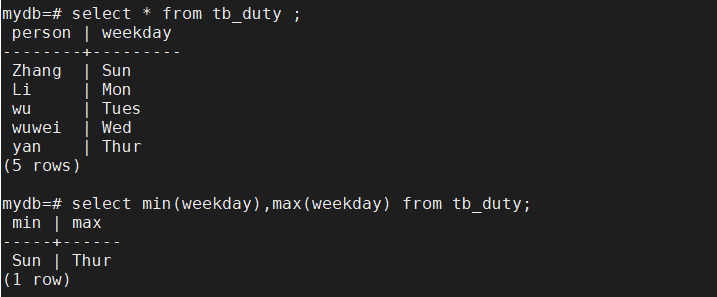
每个枚举类型都是独立存储的,一个枚举类型占4个字节。
7.几何类型
PG主要支持一些二维的几何数据类型,最基本的时 “point” ,它是其他类型的基础。
几何类型如下:
| 名字 | 存储尺寸 | 表示 | 描述 |
|---|---|---|---|
point | 16字节 | 平面上的点 | (x,y) |
line | 32字节 | 无限长的线 | {A,B,C} |
lseg | 32字节 | 有限线段 | ((x1,y1),(x2,y2)) |
box | 32字节 | 矩形框 | ((x1,y1),(x2,y2)) |
path | 16+16n字节 | 封闭路径(类似于多边形) | ((x1,y1),...) |
path | 16+16n字节 | 开放路径 | [(x1,y1),...] |
polygon | 40+16n字节 | 多边形(类似于封闭路径) | ((x1,y1),...) |
circle | 24字节 | 圆 | <(x,y),r>(中心点和半径) |
几何类型的输入
类型名称 ‘值’ 或者 ‘值’::类型名称
示例:
点:
mydb=# select point '1,2';
point
-------
(1,2)
(1 row)
mydb=# select '(1,2)'::point;
point
-------
(1,2)
(1 row)线段:
mydb=# select lseg '1,2,3,2';
lseg
---------------
[(1,2),(3,2)]
(1 row)
mydb=# select lseg '(1,2),(3,2)';
lseg
---------------
[(1,2),(3,2)]
(1 row)
mydb=# select '[(1,2),(3,2)]'::lseg;
lseg
---------------
[(1,2),(3,2)]
(1 row)
mydb=# select '((1,2),(3,2))'::lseg;
lseg
---------------
[(1,2),(3,2)]
(1 row)
矩形:
mydb=# select box '1,1,2,2';
box
-------------
(2,2),(1,1)
(1 row)
mydb=# select box '((1,1),(2,2))';
box
-------------
(2,2),(1,1)
(1 row)
注意:矩形不可以使用类似线段那种中括号输入方式,如:
mydb=# select '[(1,2),(3,2)]'::box;
2022-11-08 15:34:37.556 CST [43131] ERROR: invalid input syntax for type box: "[(1,2),(3,2)]" at character 8
2022-11-08 15:34:37.556 CST [43131] STATEMENT: select '[(1,2),(3,2)]'::box;
ERROR: invalid input syntax for type box: "[(1,2),(3,2)]"
LINE 1: select '[(1,2),(3,2)]'::box; ^
mydb=# select '((1,2),(3,2))'::box;
box
-------------
(3,2),(1,2)
(1 row)
路径:
mydb=# select path '1,1,2,2,3,3,4,4';
path
---------------------------
((1,1),(2,2),(3,3),(4,4))
(1 row)
mydb=# select path '(1,1),(2,2),(3,3),(4,4)';
path
---------------------------
((1,1),(2,2),(3,3),(4,4))
(1 row)
mydb=# select '[(1,1),(2,2),(3,3),(4,4)]'::path;
path
---------------------------
[(1,1),(2,2),(3,3),(4,4)]
(1 row)
mydb=# select '((1,1),(2,2),(3,3),(4,4))'::path;
path
---------------------------
((1,1),(2,2),(3,3),(4,4))
(1 row)
注意:路径中使用方括号 “[ ]” 表示开发路径,使用圆括号 “( )" 表示闭合路径,闭合路径指最后一个点与第一个点时连接在一起的。
多边形:
mydb=# select '((1,1),(2,2),(3,3),(4,4))'::polygon;
polygon
---------------------------
((1,1),(2,2),(3,3),(4,4))
(1 row)
mydb=# select '(1,1),(2,2),(3,3),(4,4)'::polygon;
polygon
---------------------------
((1,1),(2,2),(3,3),(4,4))
(1 row)
mydb=# select polygon '1,1,2,2,3,3,4,4';
polygon
---------------------------
((1,1),(2,2),(3,3),(4,4))
(1 row)
注意:多边形类型输入中不能使用中括号,例如:
mydb=# select '[(1,1),(2,2),(3,3),(4,4)]'::polygon;
2022-11-08 15:38:59.766 CST [43131] ERROR: invalid input syntax for type polygon: "[(1,1),(2,2),(3,3),(4,4)]" at character 8
2022-11-08 15:38:59.766 CST [43131] STATEMENT: select '[(1,1),(2,2),(3,3),(4,4)]'::polygon;
ERROR: invalid input syntax for type polygon: "[(1,1),(2,2),(3,3),(4,4)]"
LINE 1: select '[(1,1),(2,2),(3,3),(4,4)]'::polygon;
圆:
mydb=# select '(1,1),5'::circle;
circle
-----------
<(1,1),5>
(1 row)
mydb=# select circle '(1,1),5';
circle
-----------
<(1,1),5>
(1 row)
mydb=# select '((1,1)5)'::circle;
circle
-----------
<(1,1),5>
(1 row)
mydb=# select '1,1,5'::circle;
circle
-----------
<(1,1),5>
(1 row)
mydb=# select circle '1,1,5';
circle
-----------
<(1,1),5>
(1 row)
注意:圆形在pg11和pg14有区别,pg11不能使用一下输入方式:
atlasdb=# select '(1,1),5'::circle;
ERROR: invalid input syntax for type circle: "(1,1),5"
LINE 1: select '(1,1),5'::circle;
^
atlasdb=# select circle '(1,1),5';
ERROR: invalid input syntax for type circle: "(1,1),5"
LINE 1: select circle '(1,1),5';8.网络地址类型
| 名字 | 存储尺寸 | 描述 |
|---|---|---|
cidr | 7或19字节 | IPv4和IPv6网络 |
inet | 7或19字节 | IPv4和IPv6主机以及网络 |
macaddr | 6字节 | MAC地址 |
macaddr8 | 8 bytes | MAC地址(EUI-64格式) |
9.复合类型
• 复合类型是一种数据结构
• 通过声明一个类型去创建一个复合数据类型
mydb=# CREATE TYPE inventory_item AS (
mydb(# name text,
mydb(# supplier_id integer,
mydb(# price numeric
mydb(# );
CREATE TYPE
mydb=# CREATE TABLE on_hand (
mydb(# item inventory_item,
mydb(# count integer
mydb(# );
CREATE TABLE
mydb=# INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
INSERT 0 1
mydb=# select * from on_hand; item | count
------------------------+-------
("fuzzy dice",42,1.99) | 1000
(1 row)
10.数组类型
• PostgreSQL允许在各种内置的或者用户自定义的数据类型基础上创建数组类型
• 数组类型的定义是通过在数组元素类型后面添加中括号“[ ]”来实现的
• 多维数组就是使用多对中括号“[ ]”,但实际上是否为多维是取决于数据而不取决于有多少对[],所以[]与[][]的效果是一样的
• 可以在[]中写上数字,但在当前版本中并没有什么用处,也就是[ ] 与 [8]是等效的
mydb=# CREATE TABLE testarray (
mydb(# col1 integer,
mydb(# col2 integer[],
mydb(# col3 varchar[][]
mydb(# );
CREATE TABLE
mydb=# insert into testarray values (1, '{1,2,3}','{A,B,C}');
INSERT 0 1
mydb=# insert into testarray values (2, ARRAY[1,2,3,4],ARRAY['A','B','C','D']);
INSERT 0 1
mydb=# insert into testarray values (3, ARRAY[[1,2],[3,4]],ARRAY[['A','B'],['C','D']]);
INSERT 0 1
mydb=#
mydb=# insert into testarray values (4, '{{5,6},{7,8}}','{{E,F},{G,H}}');
INSERT 0 1
mydb=# select * from testarray;
col1 | col2 | col3
------+---------------+---------------
1 | {1,2,3} | {A,B,C}
2 | {1,2,3,4} | {A,B,C,D}
3 | {{1,2},{3,4}} | {{A,B},{C,D}}
4 | {{5,6},{7,8}} | {{E,F},{G,H}}
(4 rows)
mydb=# select col1,col2 from testarray where col2[1]=1;
col1 | col2
------+-----------
1 | {1,2,3}
2 | {1,2,3,4}
(2 rows)
mydb=# select col1,unnest(col2) from testarray where col2[1]=1;
col1 | unnest
------+--------
1 | 1
1 | 2
1 | 3
2 | 1
2 | 2
2 | 3
2 | 4
(7 rows)
mydb=# update testarray set col2='{{0,9},{7,8}}' where col1=4;
UPDATE 1
mydb=# update testarray set col3[1][2]='Z' where col3[2][2]='D';
UPDATE 1
mydb=# delete from testarray where col3='{{A,Z},{C,D}}';
DELETE 1
mydb=# select * from testarray;
col1 | col2 | col3
------+---------------+---------------
1 | {1,2,3} | {A,B,C}
2 | {1,2,3,4} | {A,B,C,D}
4 | {{0,9},{7,8}} | {{E,F},{G,H}}
(3 rows)
11.文档类型
| 类型 | 描述 |
| XML | XML文档 |
| json | 原文本存储的JSON文档 |
| jsonb | 经过分解的二进制方式存储的JSON文档 |
12.域类型
基于其他基础数据类型创建域类型
域是一种用户定义的数据类型,它基于另一种底层类型。根据需要,它可以有约束来限制其有效值为底层类型所允许值的一个子集。如果没有约束,它的行为就和底层类型一样 — 例如,任何适用于底层类型的操作符或函数都对该域类型有效。底层类型可以是任何内建或者用户定义的基础类型、枚举类型、数组类型、组合类型、范围类型或者另一个域。
mydb=# CREATE DOMAIN posint AS integer CHECK (VALUE > 0);
CREATE DOMAIN
mydb=# CREATE TABLE mytable (id posint);
CREATE TABLE
mydb=# INSERT INTO mytable VALUES(1); -- works
INSERT 0 1
mydb=# INSERT INTO mytable VALUES(-1); -- fails
2022-11-08 16:04:35.668 CST [57358] ERROR: value for domain posint violates check constraint "posint_check"
2022-11-08 16:04:35.668 CST [57358] STATEMENT: INSERT INTO mytable VALUES(-1);
ERROR: value for domain posint violates check constraint "posint_check"
mydb=# select * from mytable;
id
----
1
(1 row)
13.其他类型
• Pseudo-Types
伪类型不能作为表字段的定义,只能用于函数的参数或者结果类型。
• UUID(Universally Unique Identifiers)
UUID是一组128bit的二进制长度数字,在使用时是几组16进制数字格式组合
安装contrib中的uuid-ossp扩展插件可以使用UUID函数
• OIDs(Object identifiers)
用于作为系统表的唯一标识号
• pg_lsn
WAL的LSN (Log Sequence Number)标识日志位置
14.全文检索类型
* 额外extension中文分词器zhparse
| 类型 | 描述 |
| tsvector | 储存的是去重的分词后的词条 |
| tsquery | 存储用于检索的词条 |
15.范围类型
Range类型是PG 9.2之后开始出现的一种特有的类型,用于表现范围,如一个整数的范围、一个时间的范围,而范围底下的基本类型(如整数、时间)则被成为Range类型的subtype。
Range数据类型可以更快的在范围条件查询中检索到数据。
| 类型 | 描述 |
| int4range | 整形范围 |
| int8range | 长整型范围 |
| numrange | 数值范围 |
| tsrange | 时间戳范围 |
| tstzrange | 带时区时间戳范围 |
| daterange | 日期范围 |
mydb=# CREATE TABLE reservation (room int, during tsrange);
CREATE TABLE
mydb=# INSERT INTO reservation VALUES
mydb-# (1108, '[2010-01-01 14:30, 2010-01-01 15:30)');
INSERT 0 1
mydb=# select int4range(10,20) @> 3;
?column?
----------
f
(1 row)
mydb=# select int4range(10,20) @> 11;
?column?
----------
t
(1 row)
mydb=# select numrange(11.1,22.2) && numrange(20.0,30.0);
?column?
----------
t
(1 row)
mydb=# select upper(int8range(15,30));
upper
-------
30
(1 row)
mydb=# select int4range(10, 30) * int4range(15, 25);
?column?
----------
[15,25)
(1 row)
