1. 引入
作为依赖Spark的三个数据湖开源框架Delta,Hudi和Iceberg,本篇文章为这三个框架准备环境,并从Apache Spark、Hive和Presto的查询角度进行比较。主要分为三部分
准备单节点集群,包括:Hadoop,Spark,Hive,Presto和所有依赖项。
测试Delta,Hudi,Iceberg在更新,删除,时间旅行,Schema合并中的行为方式。还会检查事务日志,以及默认配置和相同数据量的大小差异。
使用Apache Hive和Presto查询。
2. 环境准备
2.1 单节点集群
版本如下
ubuntu-18.04.3-live-server-amd64
openjdk-8-jdk
scala-2.11.12
spark-2.4.4-bin-hadoop2.7
hadoop-2.7.7
apache-hive-2.3.6-bin
presto-server-329.tar
org.apache.iceberg:iceberg-spark-runtime:0.7.0-incubating
org.apache.hudi:hudi-spark-bundle:0.5.0-incubating
io.delta:delta-core_2.11:0.5.0
在Ubuntu中,我使用的是超级用户spuser,并为该用户生成hadoop所需的授权密钥。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
为Spark安装Java 1.8
#1.
sudo add-apt-repository ppa:openjdk-r/ppa
sudo apt-get update
sudo apt-get install openjdk-8-jdk
sudo update-alternatives --config java
sudo update-alternatives --config javac
确认版本为Java 1.8
#2.
spuser@acid:~$ java -version
openjdk version "1.8.0_232"
OpenJDK Runtime Environment (build 1.8.0_232-8u232-b09-0ubuntu1~16.04.1-b09)
OpenJDK 64-Bit Server VM (build 25.232-b09, mixed mode)
下载所有的依赖包
#3.
mkdir downloads
cd downloads/
wget https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.deb
wget http://apache.mirror.vu.lt/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
wget http://apache.mirror.vu.lt/apache/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.7/hadoop-2.7.7.tar.gz
wget http://apache.mirror.vu.lt/apache/hive/hive-2.3.6/apache-hive-2.3.6-bin.tar.gz
wget https://repo1.maven.org/maven2/io/prestosql/presto-cli/329/presto-cli-329-executable.jar
wget https://repo1.maven.org/maven2/io/prestosql/presto-server/329/presto-server-329.tar.gz
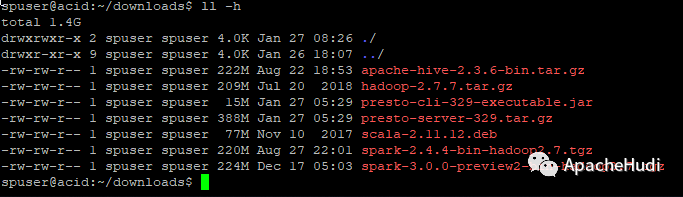
检查下载项
#4.
spuser@acid:~/downloads$ ll -h
安装Scala
#5.
sudo dpkg -i scala-2.11.12.deb
安装至/usr/local目录,对于特定版本,创建符号链接,以便将来进行更轻松的迁移
#6.
sudo tar -xzf apache-hive-2.3.6-bin.tar.gz -C /usr/local/
sudo tar -xzf hadoop-2.7.7.tar.gz -C /usr/local/
sudo tar -xzf spark-2.4.4-bin-hadoop2.7.tgz -C /usr/local/
sudo tar -xzf spark-3.0.0-preview2-bin-hadoop2.7.tgz -C /usr/local/
sudo tar -xzf presto-server-329.tar.gz -C /usr/local
sudo chown -R spuser /usr/local/apache-hive-2.3.6-bin/
sudo chown -R spuser /usr/local/hadoop-2.7.7/
sudo chown -R spuser /usr/local/spark-2.4.4-bin-hadoop2.7/
sudo chown -R spuser /usr/local/spark-3.0.0-preview2-bin-hadoop2.7/
sudo chown -R spuser /usr/local/presto-server-329/
cd /usr/local/
sudo ln -s /usr/local/apache-hive-2.3.6-bin/ usr/local/hive
sudo chown -h spuser:spuser /usr/local/hive
sudo ln -s /usr/local/hadoop-2.7.7/ /usr/local/hadoop
sudo chown -h spuser:spuser /usr/local/hadoop
sudo ln -s /usr/local/spark-2.4.4-bin-hadoop2.7 /usr/local/spark
sudo chown -h spuser:spuser /usr/local/spark
sudo ln -s /usr/local/spark-3.0.0-preview2-bin-hadoop2.7 /usr/local/spark3
sudo chown -h spuser:spuser /usr/local/spark3
sudo ln -s /usr/local/presto-server-329 /usr/local/presto
sudo chown -h spuser:spuser /usr/local/presto
为日志和HDFS创建几个文件夹。在根目录下创建一些文件夹并不是最佳做法,但可起到沙盒作用
#7.
sudo mkdir /logs
sudo chown -R spuser /logs
mkdir /logs/hadoop
#Add dir for data
sudo mkdir /hadoop
sudo chown -R spuser /hadoop
mkdir -p /hadoop/hdfs/namenode
mkdir -p /hadoop/hdfs/datanode
#create tmp hadoop dir:
mkdir -p /tmp/hadoop
更新环境变量,.bashrc
#8.
sudo nano ~/.bashrc
#Add entries in existing file:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_LOG_DIR=/logs/hadoop
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin
#Save it!
#Source it:
source ~/.bashrc
2.2 Hadoop配置
更改Hadoop配置,切换至目录
#9.
cd /usr/local/hadoop/etc/hadoop
hadoop-env.sh
#10.
#Comment existing JAVA_HOME and add new one:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
core-site.xml
#11.
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
mapred-site.xml
#12.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
hdfs-site.xml
#13.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/hdfs/datanode</value>
</property>
</configuration>
yarn-site.xml
#14.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
准备好HDFS之后,格式化并启动服务
#15.
hdfs namenode -format
start-all.sh
检查运行情况
#16.
spuser@acid:/usr/local/hadoop/etc/hadoop$ jps
9890 DataNode
10275 ResourceManager
10115 SecondaryNameNode
10613 NodeManager
9705 NameNode
10732 Jps
2.3 Hive配置
为Hive创建Hdfs目录
#17.
#Create HDFS dirs:
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir /tmp
hdfs dfs -chmod g+w /user/hive/warehouse
hdfs dfs -chmod g+w /tmp
切换至Hive conf目录
#18.
cd /usr/local/hive/conf
hive-site.xml
#19.
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=/usr/local/hive/metastore_db;create=true</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value/>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.PersistenceManagerFactoryClass</name>
<value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value>
<description>class implementing the jdo persistence</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description/>
</property>
</configuration>
hive-env.sh
#20.
# The heap size of the jvm stared by hive shell script can be controlled via:
#
export HADOOP_HEAPSIZE=512
#
# Larger heap size may be required when running queries over large number of files or partitions.
# By default hive shell scripts use a heap size of 256 (MB). Larger heap size would also be
# appropriate for hive server (hwi etc).
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/usr/local/hadoop
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/hive/conf
# Folder containing extra ibraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib/*.jar
在创建Hive metastore之前请更新hive-schema-2.3.0.derby.sql,否则iceberg将无法创建表,会有如下错误
#21.
ERROR metastore.RetryingHMSHandler: Retrying HMSHandler after 2000 ms (attempt 8 of 10) with error: javax.jdo.JDODataStoreException: Insert of object "org.apache.hadoop.hive.metastore.model.MTable@604201a0" using statement "INSERT INTO TBLS (TBL_ID,OWNER,CREATE_TIME,SD_ID,TBL_NAME,VIEW_EXPANDED_TEXT,LAST_ACCESS_TIME,DB_ID,RETENTION,VIEW_ORIGINAL_TEXT,TBL_TYPE) VALUES (?,?,?,?,?,?,?,?,?,?,?)" failed : Column 'IS_REWRITE_ENABLED' cannot accept a NULL value.
更新hive-schema-2.3.0.derby.sql
#22.
nano /usr/local/hive/scripts/metastore/upgrade/derby/hive-schema-2.3.0.derby.sql
#update statement: "APP"."TBLS"
CREATE TABLE "APP"."TBLS" ("TBL_ID" BIGINT NOT NULL, "CREATE_TIME" INTEGER NOT NULL, "DB_ID" BIGINT, "LAST_ACCESS_TIME" INTEGER NOT NULL, "OWNER" VARCHAR(767), "RETENTION" INTEGER NOT NULL, "SD_ID" BIGINT, "TBL_NAME" VARCHAR(256), "TBL_TYPE" VARCHAR(128), "VIEW_EXPANDED_TEXT" LONG VARCHAR, "VIEW_ORIGINAL_TEXT" LONG VARCHAR, "IS_REWRITE_ENABLED" CHAR(1) NOT NULL DEFAULT 'N');
更新后创建Hive metastore
#23.
schematool -initSchema -dbType derby --verbose
检查schema是否创建成功
#24.
...
beeline> Initialization script completed
schemaTool completed
通过CLI创建Hive
#25.
hive -e "show databases"

2.4 Presto配置
创建config目录
#26.
mkdir -p /usr/local/presto/etc
创建配置文件 /usr/local/presto/etc/config.properties
#27.
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=5GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=2GB
discovery-server.enabled=true
discovery.uri=http://localhost:8080
创建JVM配置文件/usr/local/presto/etc/jvm.properties
#28.
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
创建节点配置文件 /usr/local/presto/etc/node.properties
#29.
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/var/presto/data
创建相关目录
#30.
sudo mkdir -p /var/presto/data
sudo chown spuser:spuser -h /var/presto
sudo chown spuser:spuser -h /var/presto/data
创建catalog和hive配置文件 /usr/local/presto/etc/catalog/hive.properties
#31.
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:9083
2.5 Spark相关配置
检查scala版本
#32.
scala -version
#make sure that you can see something like:
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
#otherwise get back to step #5.
切换至Spark conf目录
#33.
cd /usr/local/spark/conf
spark-env.sh
#34.
#add
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_CONF_DIR=/usr/local/spark/conf
export SPARK_LOCAL_IP=127.0.0.1
拷贝hive-site.xml,以便使用Hive和Presto测试delta,hudl,iceberg行为
#35.
cp /usr/local/hive/conf/hive-site.xml /usr/local/spark/conf/
下载所有的依赖
#36.
spark-shell --packages org.apache.iceberg:iceberg-spark-runtime:0.7.0-incubating,org.apache.hudi:hudi-spark-bundle:0.5.0-incubating,io.delta:delta-core_2.11:0.5.0 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
2.6 测试三个框架
Delta
#37.
import org.apache.spark.sql.SaveMode._
spark.range(1000).toDF.write.format("delta").mode(Overwrite).save("/tmp/delta_tab01")
Hudi
#38.
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
spark.range(1000).write.format("org.apache.hudi").option(TABLE_NAME, "hudi_tab01").option(PRECOMBINE_FIELD_OPT_KEY, "id").option(RECORDKEY_FIELD_OPT_KEY, "id").mode(Overwrite).save("/tmp/hudi_tab01")
Iceberg
#39.
import org.apache.iceberg.hive.HiveCatalog
import org.apache.iceberg.catalog._
import org.apache.iceberg.Schema
import org.apache.iceberg.types.Types._
import org.apache.iceberg.PartitionSpec
import org.apache.iceberg.spark.SparkSchemaUtil
import org.apache.iceberg.hadoop.HadoopTables
val name = TableIdentifier.of("default","iceberg_tab01");
val df1=spark.range(1000).toDF.withColumn("level",lit("1"))
val df1_schema = SparkSchemaUtil.convert(df1.schema)
val partition_spec=PartitionSpec.builderFor(df1_schema).identity("level").build
val tables = new HadoopTables(spark.sessionState.newHadoopConf())
val table = tables.create(df1_schema, partition_spec, "hdfs:/tmp/iceberg_tab01")
df1.write.format("iceberg").mode("append").save("hdfs:/tmp/iceberg_tab01")
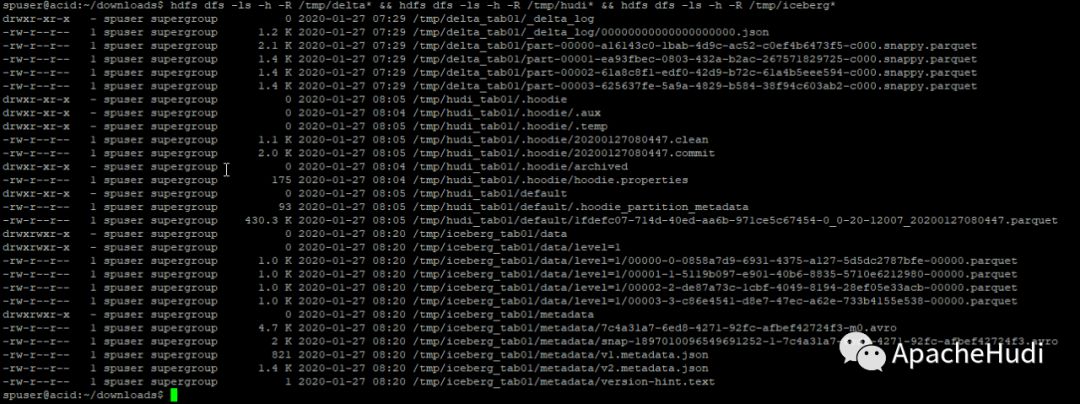
检查HDFS上结果
#40.
hdfs dfs -ls -h -R /tmp/delta* && hdfs dfs -ls -h -R /tmp/hudi* && hdfs dfs -ls -h -R /tmp/iceberg*
3. 总结
本篇文章展示了如何搭建测试三个数据湖环境所依赖的所有环境,以及进行了简单的测试,希望这对你有用。