





各位小伙伴大家好,本期的Paper Reading邀请了哈尔滨工业大学海量数据实验室的2020级博士生刘佳艺同学,刘同学主要研究方向是时序数据质量研究与分析,其将为我们带来时间序列异常检测方面的相关知识。话不多说,接下来听听刘同学的分享吧。
1. 引言
异常检测是指在数据中发现不符合预期行为的模式的问题。异常检测广泛应用于各种应用,如信用卡、保险或医疗保健欺诈检测、网络安全入侵检测、安全关键系统故障检测等。异常检测的重要性在于,数据中的异常会转化为各种应用领域中重要的、通常是关键的、可操作的信息。例如,在网络活动的数据集中,异常可能意味着入侵攻击;金融交易中的异常可能暗示金融欺诈;医疗图像中的异常可由疾病引起;航天器传感器的异常读数可能表明航天器的某些部件存在故障。
异常检测方法针对数据类型不同,方法侧重也有所不同。例如,用于检测图像中异常的算法与用于数据流的方法不同。本文主要阐述时间序列数据中的异常检测方法。
已经有许多研究多次尝试定义异常数据的性质。霍金斯将离群值定义为:“与其他观测值的偏差如此之大,以至于怀疑它是由不同的机制产生的”[1]。Barnett和Lewis给出了另一个定义,其中:“异常值是一个观察值(或观察值子集),它似乎与该组数据的其余部分不一致”[2]。
2. 异常类型
异常检测的一个重要方面是需要了解不同异常的性质。异常通常分为以下三类:
(1)点异常
在时间序列中,如果某一时刻的数据与其相邻区间的数据有显著偏差,则认为是该数据一个点异常。这是最简单的异常类型。例如,图1中红圈标注的的数据就是点异常[3],因为它不同于邻近的数据点。在现实生活中出现的点异常,可以参看信用卡欺诈检测:用户在某一天的消费支出与其平时正常的消费支出范围相比,支出金额明显高于近期消费水平,则该支出金额属于异常支出。
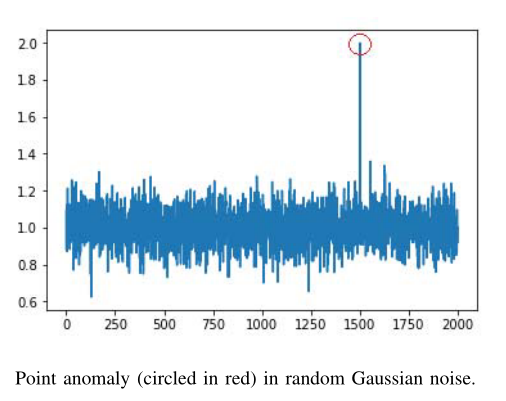
图1
(2)集合异常(子序列异常)
此异常类型包含一组以异常数据模式表示的连续点异常,此模式是不符合数据集分布。集合异常中的单个数据本身可能不是异常,但相对于其余数据它们作为一个集合一起出现是异常的。如图2所示[3]:图2是显示人体心电图输出的示例。突出显示的区域表示异常,因为相同的低值存在的时间异常长(对应于心房早搏)。注意,低值本身并不是一种异常。
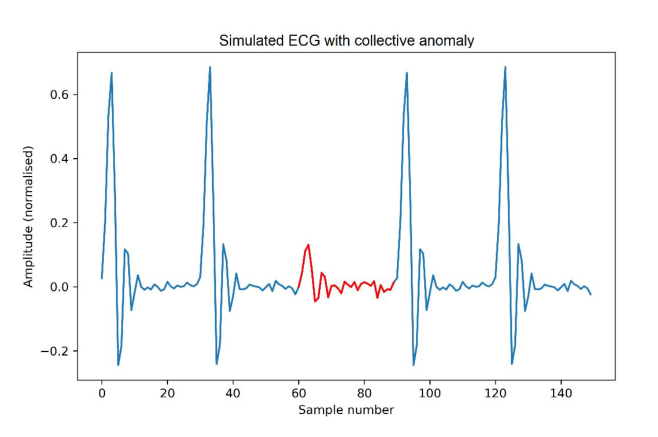
图2
(3)上下文异常
指在特定情境下可能是正常的,而在另一种环境下则被检测为异常。如图3所示[3]:该图显示了过去几年某个地区的月温度。在冬季t1处的温度可能是正常的,但在夏季相同的值(t2处)将是异常的。
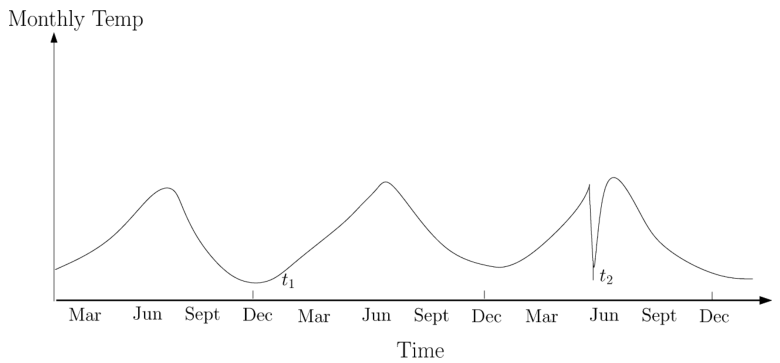
图3
3.异常检测方法分类
(1)基于统计的检测方法
基于统计的异常检测是发展最早的技术。基于统计的方法需要对数据的分布做出假定,认为不服从该假定分布的数据就是异常数据。该方法的⼀般思路是:先利用数据拟合出一个数据模型,根据得到的模型识别符合该模型概率的数据,把低概率的数据认为是异常数据,3-Sigma法则,箱型图(Boxplot) 都是常见的概率统计模型判断异常的方法。概率模型可以分为参数方法以及非参数方法,如高斯混合模型是经典的参数统计模型;非参数统计模型如HBOS算法。
优点:复杂度低、计算速度快;
缺点:强假设,效果往往不好。
(2)基于距离的方法
基于距离的方法也叫做基于近邻的方法,其主要思路是:先定义距离度量,然后根据该度量判断当前观察的数据与大多数据的距离关系,若距离很远那这个当前观察的数据就是异常。
k-最近邻[4]:最简单的定义方法是利用数据对象与其最近的k个点的距离之和作为评分标准。很明显,与k个最近邻的距离之和越小,则异常分越低;与k个最近邻的距离之和越大,异常分越大。然后根据设定的阈值,当异常分高于阈值,则该数据就是异常点。关于距离的计算可以用不同的方法,例如欧氏距离用于连续属性。
优点:易于计算;
缺点:对参数k和阈值敏感。
(3)基于密度的方法
与基于距离的方法类似,基于密度的方法是计算当前观察的数据周围密度和其近邻点的周围密度。它的直观思想是:正常点与其近邻点的密度是相近的,而异常点的密度和其近邻点存在较大差异,即异常点位于密度较低的邻域中,而正常点位于密度较高的区域中[5]。
Local Outlier Factor(LOF局部异常因子)[6]:对于给定的数据实例,异常得分是其k个最近邻居的平均局部密度与局部密度本身的比率。
近年来学者通过对 LOF 进行扩展,提出了若干新颖的异常检测方法,例如:基于连接的异常因子( connectivity-based outlier factor,COF)、局部相关积分 ( local correlation integral method,LOCI)、局部距离因子( local distance-based outlier factor,LDOF) 、局部异常概率( local outlier pobabilities,LoOP)、INFLO(influenced outlierness)等。
优点:面对分布不均匀的数据有很好的检测结果;
缺点:计算复杂度高,对参数敏感。
(4)基于聚类的方法
聚类可以把相似的或是相关的数据分到一类,而由于异常一定是少数的,可见在聚类时异常要么不属于任何一类,要么异常数据聚类的簇十分稀疏或者远离中心。那基于以上的想法就可以利用聚类的方法进行异常检测。常见的聚类方法如k-means、DBSCAN等都可以运用到时序异常检测。比如在[7]中,作者将每一条时间序列都会被按天切分成很多子序列(subsequence),然后对子序列利用DBSCAN进行聚类,把相似的时间序列放在一类,不相似的放在另外一类。
优点:适用高维;
缺点:对参数敏感。
(5)基于划分的方法
基于划分的方法最典型的就是孤立森林(Isolation Forest)[8]。所谓“孤立”就是把异常数据从正常的数据中孤立出来,这是因为异常数据通常分布的比较稀疏,也就是他们离正常的数据比较远,并且异常数据占比少且与正常数据差距大所以可以借助一些手段将他们“孤立”出来。它的主要思想是:假设我们用一个随机超平面来切割数据空间,切一次可以生成两个子空间。之后我们再继续用一个随机超平面来切割每个子空间,循环下去,直到每子空间里面只有一个数据点为止。直观上来讲,我们可以发现那些密度很高的簇是可以被切很多次才会停止切割,但是那些密度很低的点很容易很早的就停到一个子空间了。
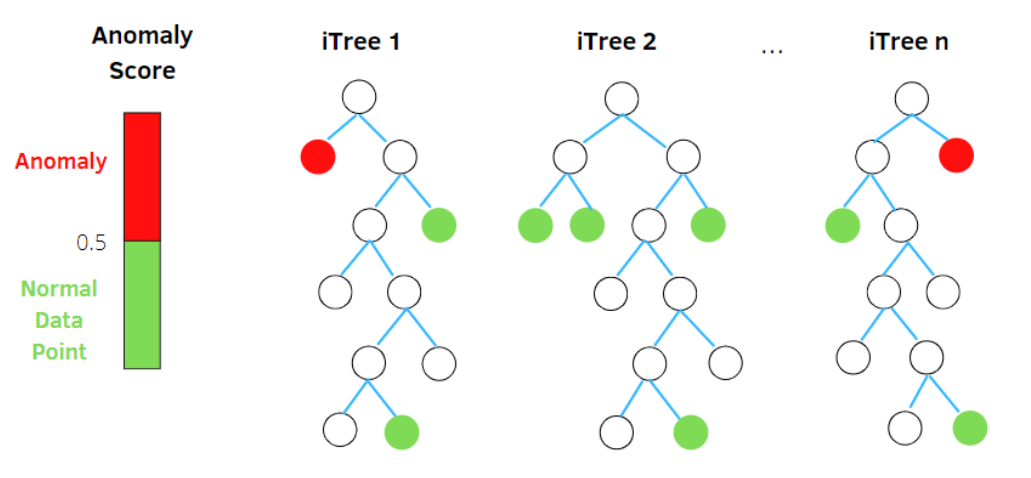
图4
通过从原始数据中抽取部分样本,选取部分特征,构建一颗二叉树,利用集成学习的思想,多次抽取样本和特征,最后构建出森林。从图4[16]可以看出,异常样本更容易快速落入叶子结点或者说,异常样本在决策树上,距离根节点更近。
优点:适合分布式计算、速度快;
缺点:只适用于异常点较少的情况。
(6)基于分类的方法
我们可以把异常检测看成二分类问题,也就是正常数据分为一类,异常数据为另一类。分类技术就是是根据训练集 建立分类器,确定对象属于哪个目标类的过程,由此可以借鉴分类技术来进行异常检测。
支持向量机( SVM) 主要从数据的空间分布来构造最优分类面,以实现两类数据的划分。目前 SVM已经广泛用于异常检测当中。例如,基于一类SVM( one-class SVM,OCSVM )和支持向量数据描述 ( support vector data description,SVDD)方法。
OCSVM [9]:找到一个超平面将训练数据中的正例圈出,然后利用找到的超平面做出分类决策,若数据划分到圈内的则认为是正例,圈外则为负样例即异常数据。
缺点:数据分布不平衡时效果差。
(7)基于预测的方法
根据系统的近期和长期趋势生成回归模型,预测未来某个时间的预期值。当接收到一个新的观测值时,将其与这些预测值进行比较,并评估该预测的准确性,如果观测值和预测值相差很大,则该观测值被标记为异常。可利用的预测模型方法:ARIMA、指数平滑预测模型以及Facebook开源算法Prophet等等。
(8)基于深度学习模型
最近几年,利用深度学习生成模型来做异常检测的算法越来越多,而且在效果上都有很好的表现。常见模型有生成对抗网络GAN、变分自编码器VAE等。例如,GANs[13、14、15]通过重构的信息进行异常检测并作为对抗性规则化执行。从2018年开始利用VAE进行时序异常检测的研究越来越主流,VAE的原理大致可以理解为:VAE 希望训练一个生成模型,使得这个模型能够将采样后的概率分布映射到训练集的概率分布。目前基于VAE的异常检测算法居多,基本思想是针对数据进行训练建模,然后通过重构误差来识别异常点,误差越大越可能是异常数据。
例如,Park等人提出了LSTM-VAE[10]模型,该模型使用LSTM进行时间建模,然后利用变分自编码器(VAE)进行重构。Su等人提出的OmniAnomaly[11]进一步扩展了具有归一化流的 LSTM-VAE 模型,然后使用重建概率进行异常检测。Li等人提出的InterFusion[12]通过具有两个随机潜在变量的分层变分自编码器VAE,同时模拟多个序列之间的相互依赖和内部依赖,从而对数据中的正常模式进行建模,最后根据重构信息进行异常检测。
参考文献
[1] D . M . H a w k i n s , Identification of Outliers, vol. 11. London, U.K.:Chapman & Hall, 1980.
[2] V . Barnett and T. Lewis, Outliers in Statistical Data. Chichester, U.K.: Wiley, 1974.
[3] Cook A A , Msrl G , Fan Z . Anomaly Detection for IoT Time-Series Data: A Survey[J]. IEEE Internet of Things Journal, 2020, 7(7):6481-6494.
[4] K. G. Mehrotra, C. K. Mohan, and H. Huang. Anomaly Detection Principles and Algorithms. Springer, 2017.
[5] V . Chandola, A. Banerjee, and V . Kumar. Anomaly detection: A survey. CSUR, 41(3):15, 2009.
[6] M. M. Breunig, H.-P . Kriegel, R. T. Ng, and J. Sander. Lof: Identifying density-based local outliers. SIGMOD Rec., 29(2):93–104, May 2000.
[7] N. Zhao et al., "Automatic and Generic Periodicity Adaptation for KPI Anomaly Detection," in IEEE Transactions on Network and Service Management, vol. 16, no. 3, pp. 1170-1183, Sept. 2019, doi: 10.1109/TNSM.2019.2919327.
[8] Liu, FT, Ting, et al. Isolation Forest[J]. IEEE DATA MINING, 2008.
[9] B. Schölkopf, R. Williamson, A. Smola, J. Shawe-Taylor, and J. Platt, “Support vector method for novelty detection,” in Advances in Neural Information Processing Systems, vol. 12. Denver, CO, USA: MIT Press, Aug./Sep. 1999, pp. 582–588.
[10] Daehyung Park, Yuuna Hoshi, and Charles C. Kemp. A multimodal anomaly detector for robotassisted feeding using an lstm-based variational autoencoder. RA-L, 2018.
[11] Ya Su, Y. Zhao, Chenhao Niu, Rong Liu, W. Sun, and Dan Pei. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. KDD, 2019.
[12] Zhihan Li, Youjian Zhao, Jiaqi Han, Ya Su, Rui Jiao, Xidao Wen, and Dan Pei. Multivariate time series anomaly detection and interpretation using hierarchical inter-metric and temporal embedding. KDD, 2021.
[13] T. Schlegl, Philipp Seeb¨ock, S. Waldstein, G. Langs, and U. Schmidt-Erfurth. f-anogan: Fast unsupervised anomaly detection with generative adversarial networks. Med. Image Anal., 2019.
[14] Dan Li, Dacheng Chen, Lei Shi, Baihong Jin, Jonathan Goh, and See-Kiong Ng. Mad-gan: Multivariate anomaly detection for time series data with generative adversarial networks. In ICANN, 2019a.
Bin Zhou, Shenghua Liu, Bryan Hooi, Xueqi Cheng, and Jing Ye.
[15] Beatgan: Anomalous rhythm detection using adversarially generated time series. In IJCAI, 2019.
[16] https://zhuanlan.zhihu.com/p/492469453
参与CnosDB社区交流群:
扫描下方二维码,加入CC进入CnosDB社区进入社区交流,CC也会在群内分享直播链接哒







🚪由此下方【阅读原文】即可传送CnosDB GitHub开源社区🔜🎟 各位爱码士🧙♂️尽情享受开源世界吧。
