





前言
云原生数据仓库产品AnalyticDB MySQL数仓版,是阿里云基于集团电商双11业务百亿次在线分析的最佳实践,推出的业界首款兼容MySQL协议,且性能全球第一(TPC-DS 10TB)的云数据仓库产品。企业只需要招一些具备SQL技能的数据分析师,搭配上一个QuickBI/DataV/自研可视化报表,就可以快速将企业的关键指标实时可视化展示,帮助企业转型成数据驱动决策的公司。
业务挑战:数据一致性和时效性较差


今年的云栖大会上(11月4日数据库分论坛),我们重磅推出了经过1年多时间沉淀和打磨的「湖仓版」,来一起看看AnalyticDB产品对于「湖仓一体」的思考和实践。
湖仓版介绍
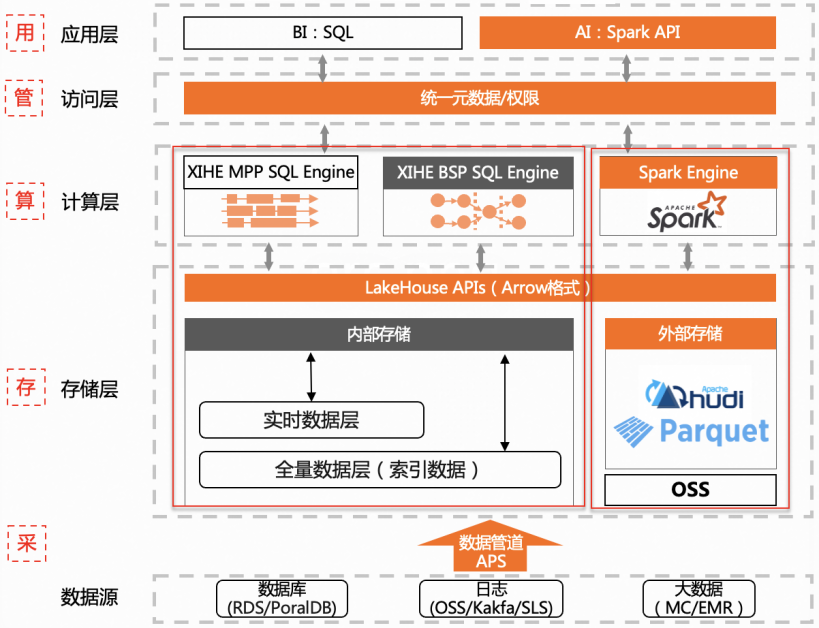
自研引擎:做强核心
存储层:只需一份全量数据,满足离线在线场景
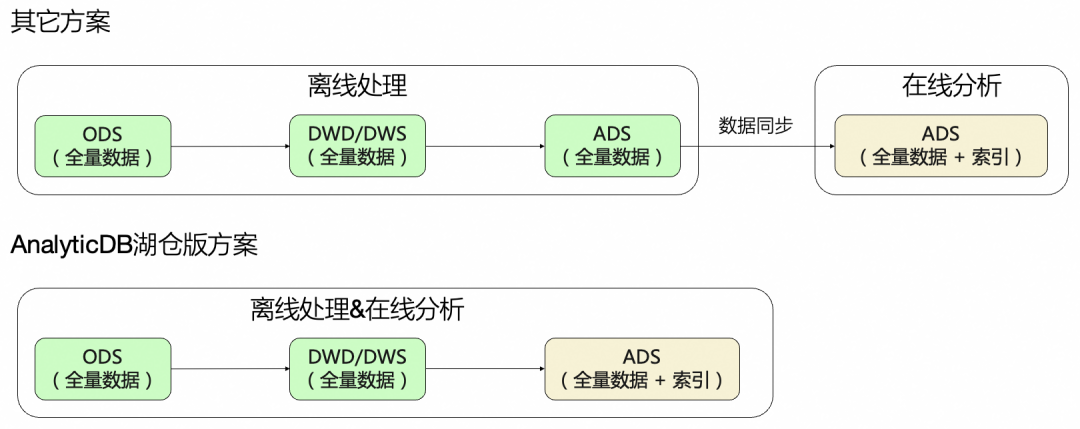
「一份数据」是指一份全量数据。这里的难点是解决既要(高性能在线分析)又要(低成本离线处理)的问题,因为本身这两种场景对于存储的诉求是比较不一致的。在线分析场景希望数据尽量在高性能存储介质上提高性能,离线处理希望数据尽量在低成本存储介质上降低存储成本。
我们给出的解决方案是,首先将一份全量数据存在低成本高吞吐存储介质上,低成本离线处理场景直接读写低成本存储介质,降低数据存储和数据IO成本,保证高吞吐。其次将实时数据存在单独的存储IO节点(EIU)上,保证「行级」的数据实时性,同时对全量数据构建索引,并通过Cache能力对数据进行加速,满足百ms级高性能在线分析场景。
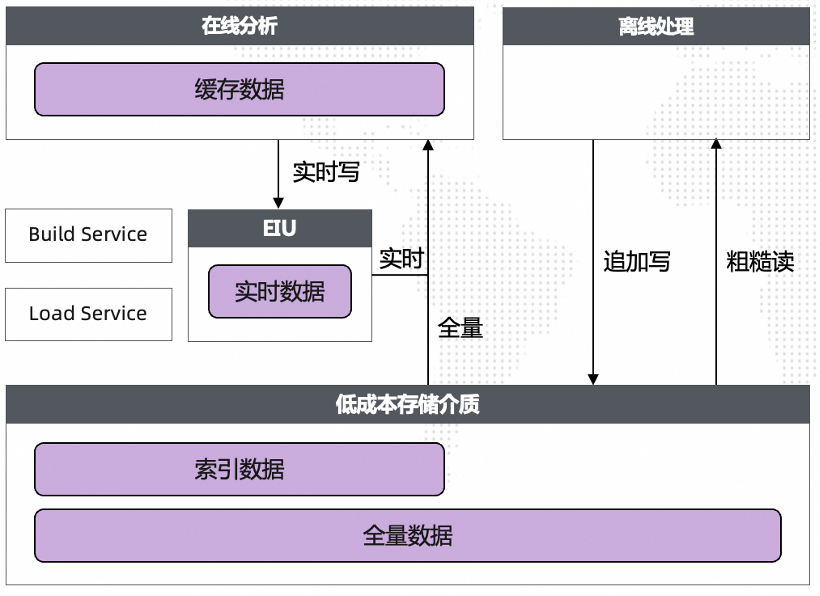
「湖仓版存储架构图」
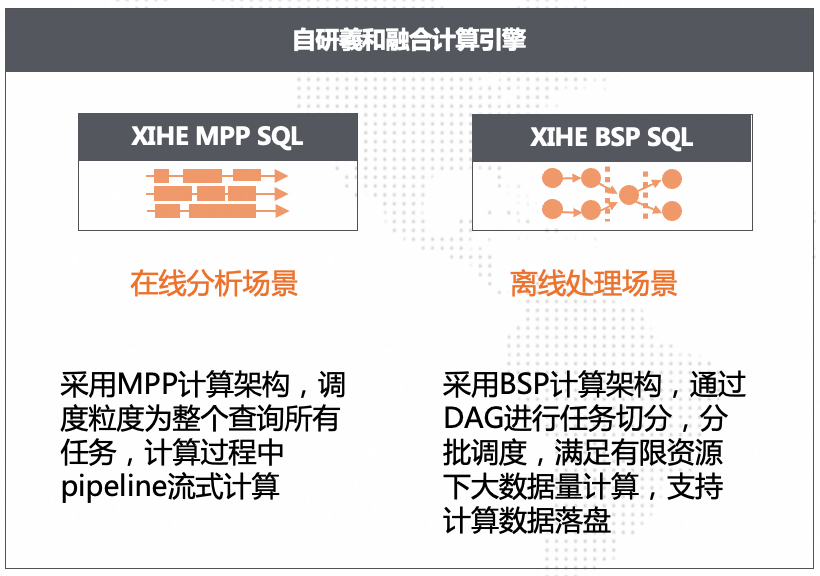
支撑高性能在线分析的背后,计算部分主要是自研的「羲和计算引擎」MPP模式,但这种流式计算模式并不适合离线处理低成本和高吞吐的特点。所以,湖仓版我们在「羲和分析计算引擎」中新增加了BSP模式,通过DAG进行任务切分,分批调度,满足有限资源下大数据量计算,支持计算数据落盘。
但我们觉得MPP模式和BSP模式对于普通用户来说,理解和学习成本太高了,所以我们把「羲和计算引擎」升级成「羲和融合计算引擎」,同时提供MPP模式和BSP模式,并提供自动切换能力。自动切换能力是指当查询使用MPP模式无法在一定耗时内完成时,系统会自动切换为BSP模式进行执行。
极致弹性:千核秒级弹性能力,完美贴合业务负载
开源集成:做精场景
自研是打造技术深度的基础,但同时我们积极拥抱开源,满足已经生长在开源生态上的客户可以更平滑地使用湖仓版。外表类型,在Parquet/ORC/JSON/CSV等append类型数据格式的基础上,新增支持批量更新的Hudi数据格式,帮助用户更好地低成本接入如CDC等数据。计算引擎,在做深「羲和融合计算引擎」的基础上,新增开源活跃度较高的Spark引擎,满足用户对于复杂离线处理和ML机器学习等需求。
优势总结

1:是指一份数据,避免数据同步带来的数据一致性、时效性、冗余等问题;
0:是指灵活弹性,用Serverless的方式贴合业务负载,保证查询性能,降低资源成本;
2:是指湖仓版同时满足低成本离线处理和高性能在线分析;
今天,我们推出了AnalyticDB MySQL湖仓版,完成了从仓到湖,打造人人可用的云原生一站式数据分析平台的第一步。未来,我们还将在以下几个方面继续打磨和增强:
云原生弹性:
存储提供Serverless单副本模式,降低存储成本,提供更好的弹性能力。
在线分析提供Mutil-Clusters弹性模式,更好地支撑高QPS场景。
自研融合计算引擎:
自适应执行框架:根据运行时信息,更精准地动态调整Plan,提升查询性能。
统一执行模型:在自适应执行框架的基础上,引入Bubble Execution Model来统一执行模型(MPP/BSP),同时Bubble的切分和调度考虑运行时的集群资源和负载特征。降低用户选择执行模型成本,提升查询性能。
Spark引擎:
提供交互式开发调试Notebook能力 提供更多的内置Connector连接更多的数据源
公测说明










 点击「阅读原文」查看 云原生数据仓库AnalyticDB 更多信息
点击「阅读原文」查看 云原生数据仓库AnalyticDB 更多信息
