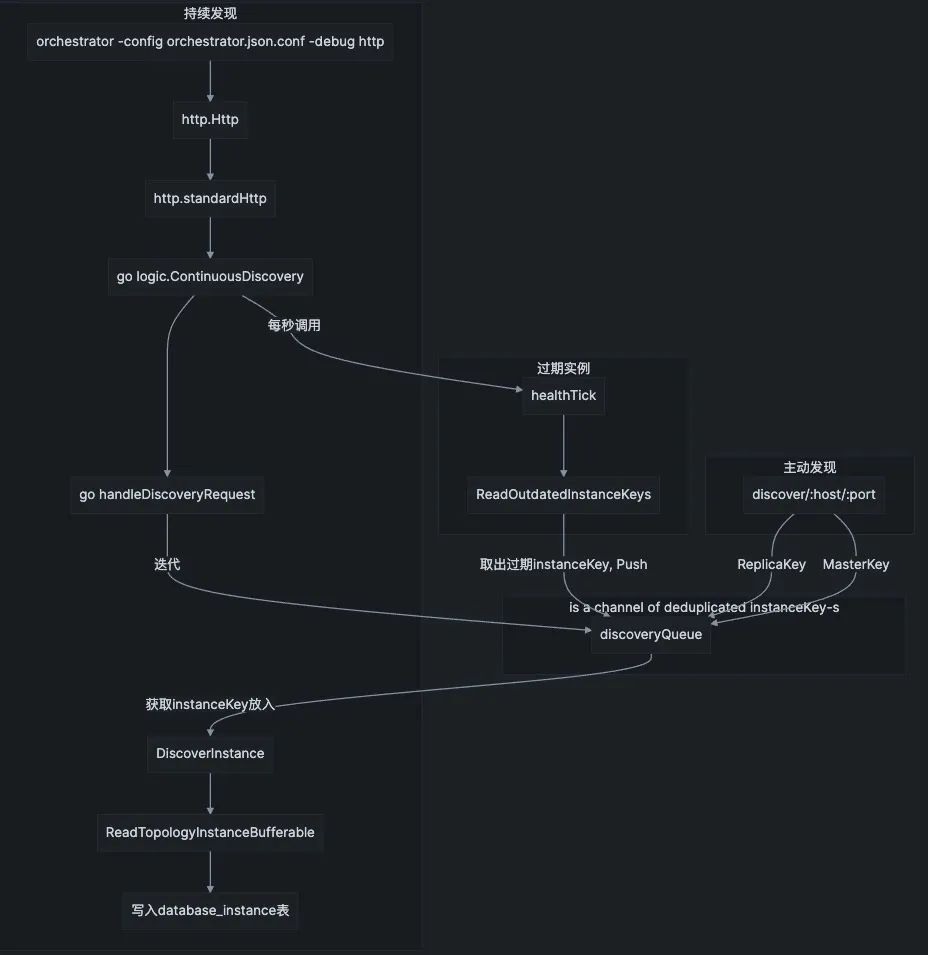
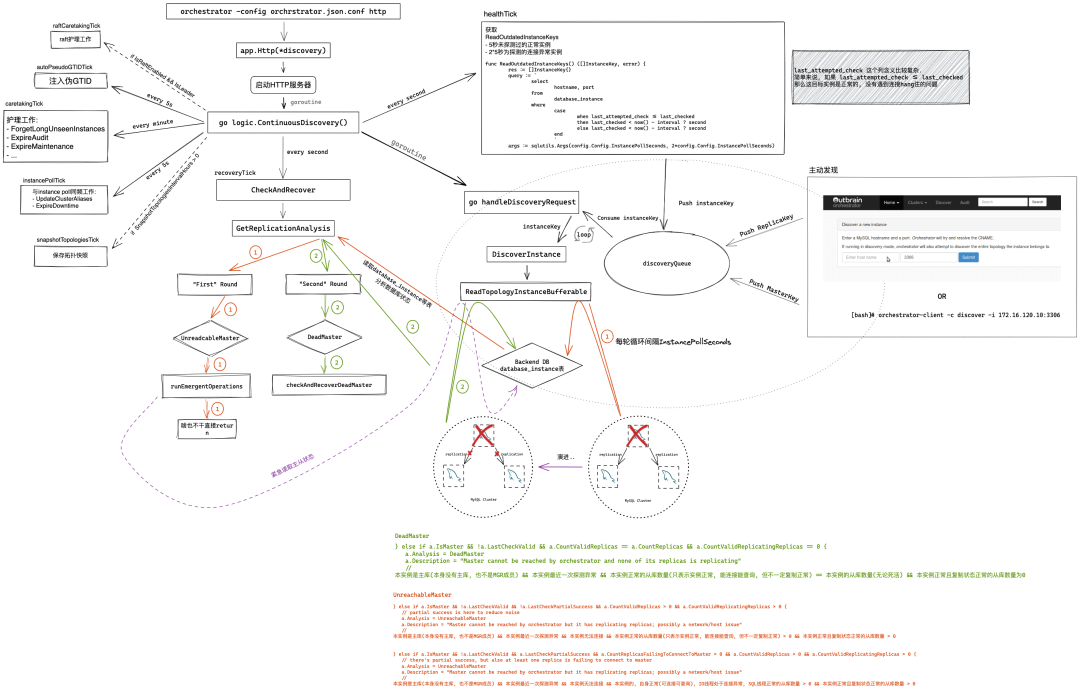
就会 http.Http -> http.standardHttp -> go logic.ContinuousDiscovery()
ContinuousDiscovery 都干了啥
持续发现
// ContinuousDiscovery starts an asynchronuous infinite discovery process where instances are // periodically investigated and their status captured, and long since unseen instances are // purged and forgotten. ContinuousDiscovery启动一个永不停止的异步"发现"过程, 在这个过程中, 实例被周期性地调查并捕获它们的状态, 长期以来不可见的实例被清除和遗忘.
这段注释中 asynchronuous 还拼写错了,应该是 asynchronous
ContinuousDiscovery 先启动一个协程
funcContinuousDiscovery() { ... go handleDiscoveryRequests()
// avoid any logging unless there's something to be done iflen(instanceKeys) > 0 { for _, instanceKey := range instanceKeys { if instanceKey.IsValid() { discoveryQueue.Push(instanceKey) } } }
for { select { ...省略部分代码 case <-instancePollTick: // 5秒一次 gofunc() { // This tick does NOT do instance poll (these are handled by the oversampling discoveryTick) // But rather should invoke such routinely operations that need to be as (or roughly as) frequent // as instance poll if IsLeaderOrActive() { go inst.UpdateClusterAliases() go inst.ExpireDowntime() go injectSeeds(&seedOnce) } }() ...省略部分代码 }
for { select { ...省略部分代码 case <-autoPseudoGTIDTick: gofunc() { if config.Config.AutoPseudoGTID && IsLeader() { go InjectPseudoGTIDOnWriters() } }() ...省略部分代码 }
Pseudo GTID ,不太重要,现在还会有人不开 GTID 吗?
护理工作
funcContinuousDiscovery() { ...省略部分代码 caretakingTick := time.Tick(time.Minute) ...省略部分代码 for { select { ...省略部分代码 case <-caretakingTick: // Various periodic internal maintenance tasks gofunc() { if IsLeaderOrActive() { go inst.RecordInstanceCoordinatesHistory() go inst.ReviewUnseenInstances() go inst.InjectUnseenMasters()
go inst.ForgetLongUnseenInstances() go inst.ForgetLongUnseenClusterAliases() go inst.ForgetUnseenInstancesDifferentlyResolved() go inst.ForgetExpiredHostnameResolves() go inst.DeleteInvalidHostnameResolves() go inst.ResolveUnknownMasterHostnameResolves() go inst.ExpireMaintenance() go inst.ExpireCandidateInstances() go inst.ExpireHostnameUnresolve() go inst.ExpireClusterDomainName() go inst.ExpireAudit() go inst.ExpireMasterPositionEquivalence() go inst.ExpirePoolInstances() go inst.FlushNontrivialResolveCacheToDatabase() go inst.ExpireInjectedPseudoGTID() go inst.ExpireStaleInstanceBinlogCoordinates() go process.ExpireNodesHistory() go process.ExpireAccessTokens() go process.ExpireAvailableNodes() go ExpireFailureDetectionHistory() go ExpireTopologyRecoveryHistory() go ExpireTopologyRecoveryStepsHistory()
if runCheckAndRecoverOperationsTimeRipe() && IsLeader() { go SubmitMastersToKvStores("", false) } } else { // Take this opportunity to refresh yourself go inst.LoadHostnameResolveCache() } }()
funcContinuousDiscovery() { raftCaretakingTick := time.Tick(10 * time.Minute) ...省略部分代码 for { select { ...省略部分代码 case <-raftCaretakingTick: if orcraft.IsRaftEnabled() && orcraft.IsLeader() { // publishDiscoverMasters will publish to raft a discovery request for all known masters. // This makes for a best-effort keep-in-sync between raft nodes, where some may have // inconsistent data due to hosts being forgotten, for example. go publishDiscoverMasters() }
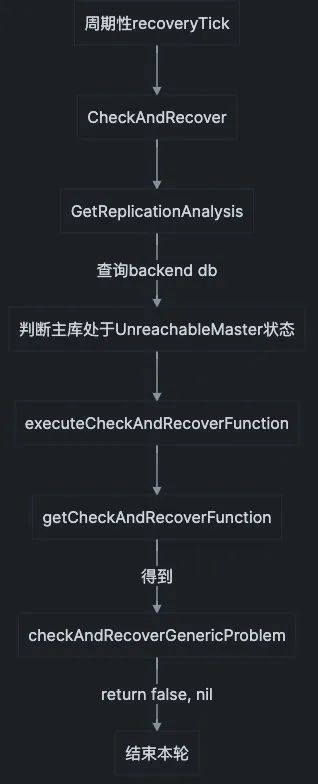
for { select { case <-recoveryTick: gofunc() { if IsLeaderOrActive() { go ClearActiveFailureDetections() go ClearActiveRecoveries() go ExpireBlockedRecoveries() go AcknowledgeCrashedRecoveries() go inst.ExpireInstanceAnalysisChangelog()
gofunc() { // This function is non re-entrant (it can only be running once at any point in time) if atomic.CompareAndSwapInt64(&recoveryEntrance, 0, 1) { // 如果返回true, 说明当时没有运行中的恢复任务 defer atomic.StoreInt64(&recoveryEntrance, 0) } else { // 否则直接return return } if runCheckAndRecoverOperationsTimeRipe() { // 从开始运行ContinuousDiscovery至今的时间 > (3 * InstancePollSeconds = 15秒) 才可以运行recover CheckAndRecover(nil, nil, false) } else { log.Debugf("Waiting for %+v seconds to pass before running failure detection/recovery", checkAndRecoverWaitPeriod.Seconds()) } }() } }()
从注释// This function is non re-entrant (it can only be running once at any point in time) 可以看出,同一时间只能有一个恢复任务运行
executeCheckAndRecoverFunction 函数注释
// executeCheckAndRecoverFunction will choose the correct check & recovery function based on analysis.
// It executes the function synchronuously
funcgetCheckAndRecoverFunction(analysisCode inst.AnalysisCode, analyzedInstanceKey *inst.InstanceKey)( checkAndRecoverFunction func(analysisEntry inst.ReplicationAnalysis, candidateInstanceKey *inst.InstanceKey, forceInstanceRecovery bool, skipProcesses bool)(recoveryAttempted bool, topologyRecovery *TopologyRecovery, err error), isActionableRecovery bool, ) { switch analysisCode { ...省略部分代码 case inst.UnreachableMaster: return checkAndRecoverGenericProblem, false ...省略部分代码 } // Right now this is mostly causing noise with no clear action. // Will revisit this in the future. // case inst.AllMasterReplicasStale: // return checkAndRecoverGenericProblem, false
funcrunEmergentOperations(analysisEntry *inst.ReplicationAnalysis) { switch analysisEntry.Analysis { ...省略部分代码 case inst.UnreachableMaster: go emergentlyReadTopologyInstance(&analysisEntry.AnalyzedInstanceKey, analysisEntry.Analysis) go emergentlyReadTopologyInstanceReplicas(&analysisEntry.AnalyzedInstanceKey, analysisEntry.Analysis)
// Force a re-read of a topology instance; this is done because we need to substantiate a suspicion // that we may have a failover scenario. we want to speed up reading the complete picture. 强制重新读取一个拓扑实例;这样做是因为我们需要证实一个怀疑,即我们可能有一个故障转移的情况。我们希望加快读取完整的图片。 // Force reading of replicas of given instance. This is because we suspect the instance is dead, and want to speed up // detection of replication failure from its replicas. 强制读取给定实例的副本。这是因为我们怀疑该实例已经死亡,并希望加快从其副本中检测复制失败。
} elseif a.IsMaster && !a.LastCheckValid && a.CountValidReplicas == a.CountReplicas && a.CountValidReplicatingReplicas == 0 { a.Analysis = DeadMaster a.Description = "Master cannot be reached by orchestrator and none of its replicas is replicating" //
} elseif a.IsMaster && !a.LastCheckValid && !a.LastCheckPartialSuccess && a.CountValidReplicas > 0 && a.CountValidReplicatingReplicas > 0 { // partial success is here to reduce noise a.Analysis = UnreachableMaster a.Description = "Master cannot be reached by orchestrator but it has replicating replicas; possibly a network/host issue" // } elseif a.IsMaster && !a.LastCheckValid && a.LastCheckPartialSuccess && a.CountReplicasFailingToConnectToMaster > 0 && a.CountValidReplicas > 0 && a.CountValidReplicatingReplicas > 0 { // there's partial success, but also at least one replica is failing to connect to master a.Analysis = UnreachableMaster a.Description = "Master cannot be reached by orchestrator but it has replicating replicas; possibly a network/host issue" //
/* To be considered a master, traditional async replication must not be present/valid AND the host should either */ /* not be a replication group member OR be the primary of the replication group */ MIN(master_instance.last_check_partial_success) as last_check_partial_success, MIN( ( master_instance.master_host IN ('', '_') OR master_instance.master_port = 0 OR substr(master_instance.master_host, 1, 2) = '//' ) AND ( master_instance.replication_group_name = '' OR master_instance.replication_group_member_role = 'PRIMARY' ) ) AS is_master,
MIN( master_instance.last_checked <= master_instance.last_seen and master_instance.last_attempted_check <= master_instance.last_seen + interval ? second ) = 1 AS is_last_check_valid
interval ? 的实际值是
// ValidSecondsFromSeenToLastAttemptedCheck returns the maximum allowed elapsed time// between last_attempted_check to last_checked before we consider the instance as invalid. funcValidSecondsFromSeenToLastAttemptedCheck()uint { return config.Config.InstancePollSeconds + config.Config.ReasonableInstanceCheckSeconds }
IFNULL( SUM( replica_instance.last_checked <= replica_instance.last_seen AND replica_instance.slave_io_running = 0 AND replica_instance.last_io_error like '%%error %%connecting to master%%' AND replica_instance.slave_sql_running = 1 ), 0 ) AS count_replicas_failing_to_connect_to_master,
再看 UnreachableMaster 和 DeadMaster
} elseif a.IsMaster && !a.LastCheckValid && a.CountValidReplicas == a.CountReplicas && a.CountValidReplicatingReplicas == 0 { a.Analysis = DeadMaster a.Description = "Master cannot be reached by orchestrator and none of its replicas is replicating" // 本实例是主库(本身没有主库, 也不是MGR成员) && 本实例最近一次探测异常 && 本实例正常的从库数量(只表示实例正常, 能连接能查询, 但不一定复制正常) == 本实例的从库数量(无论死活) && 本实例正常且复制状态正常的从库数量为0
} elseif a.IsMaster && !a.LastCheckValid && !a.LastCheckPartialSuccess && a.CountValidReplicas > 0 && a.CountValidReplicatingReplicas > 0 { // partial success is here to reduce noise a.Analysis = UnreachableMaster a.Description = "Master cannot be reached by orchestrator but it has replicating replicas; possibly a network/host issue" // 本实例是主库(本身没有主库, 也不是MGR成员) && 本实例最近一次探测异常 && 本实例无法连接 && 本实例正常的从库数量(只表示实例正常, 能连接能查询, 但不一定复制正常) > 0 && 本实例正常且复制状态正常的从库数量 > 0
} elseif a.IsMaster && !a.LastCheckValid && a.LastCheckPartialSuccess && a.CountReplicasFailingToConnectToMaster > 0 && a.CountValidReplicas > 0 && a.CountValidReplicatingReplicas > 0 { // there's partial success, but also at least one replica is failing to connect to master a.Analysis = UnreachableMaster a.Description = "Master cannot be reached by orchestrator but it has replicating replicas; possibly a network/host issue" // 本实例是主库(本身没有主库, 也不是MGR成员) && 本实例最近一次探测异常 && 本实例无法连接 && 本实例的, 自身正常(可连接可查询), IO线程处于连接异常, SQL线程正常的从库数量 > 0 && 本实例正常且复制状态正常的从库数量 > 0