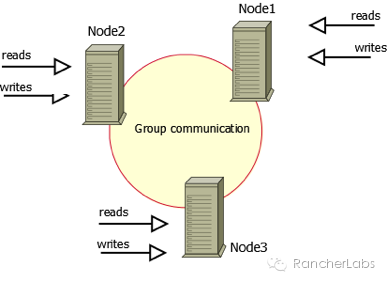
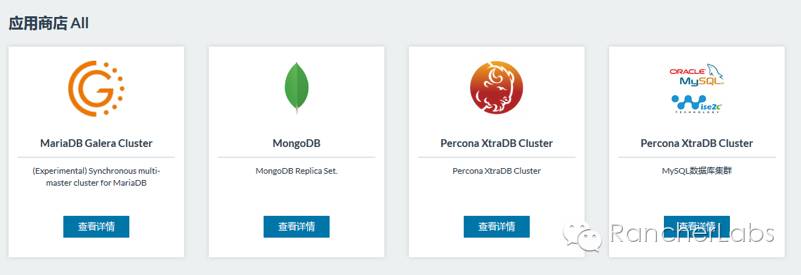
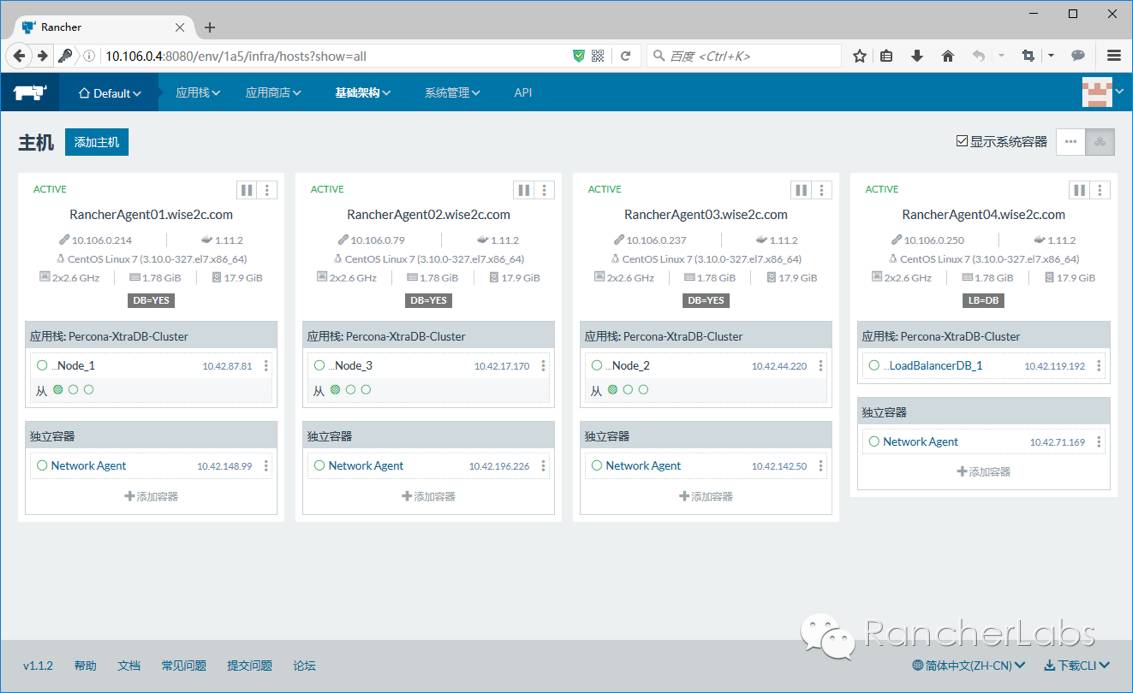
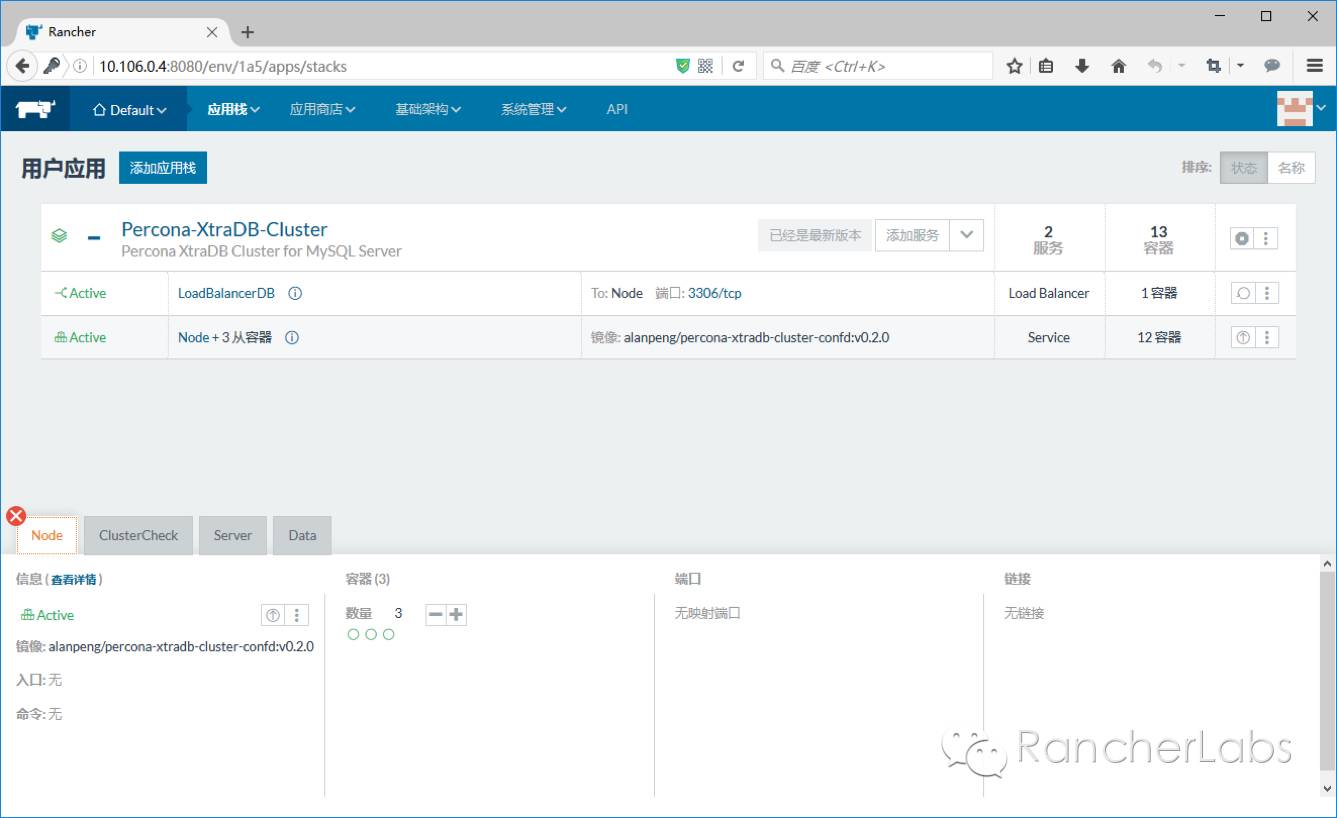
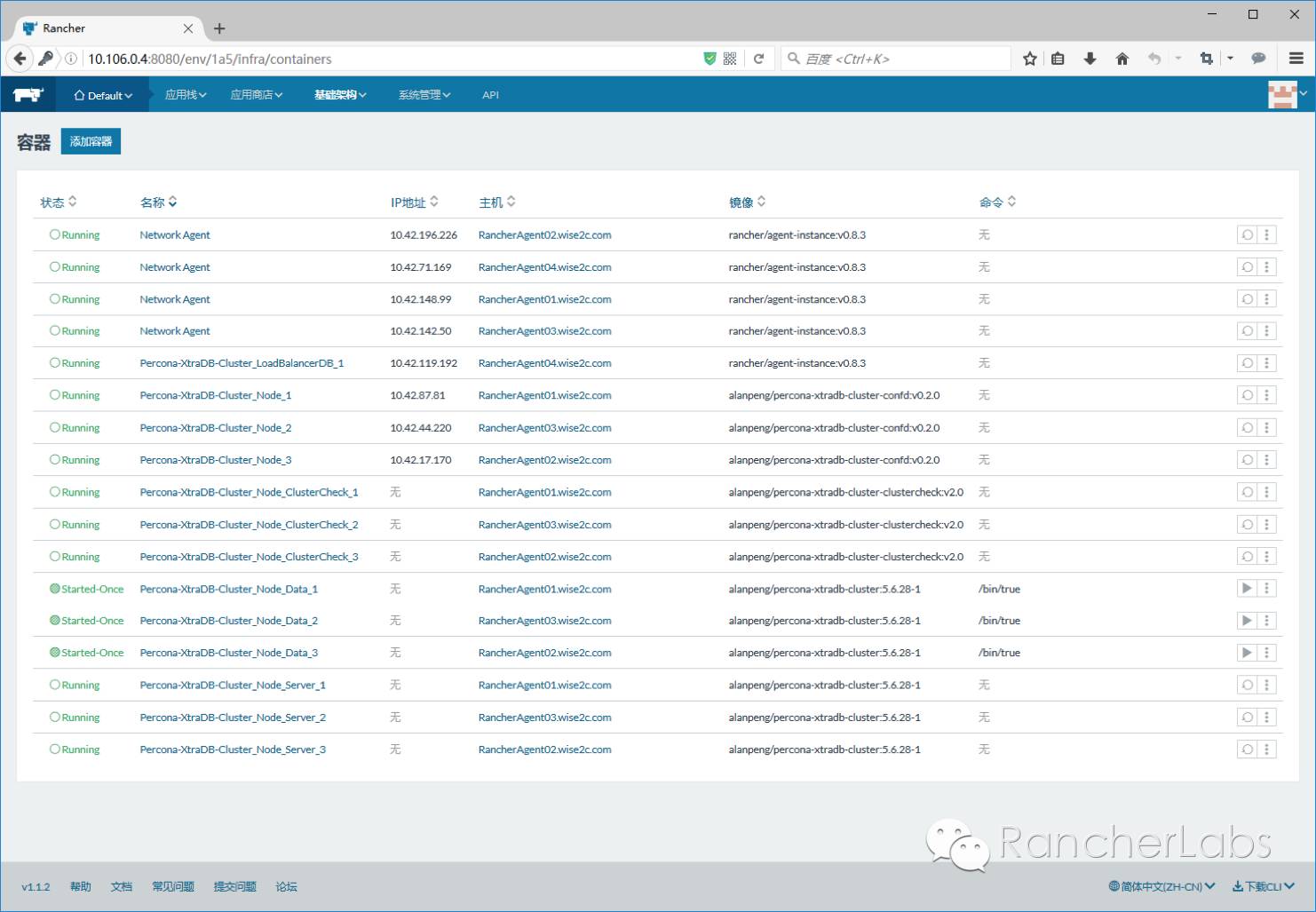
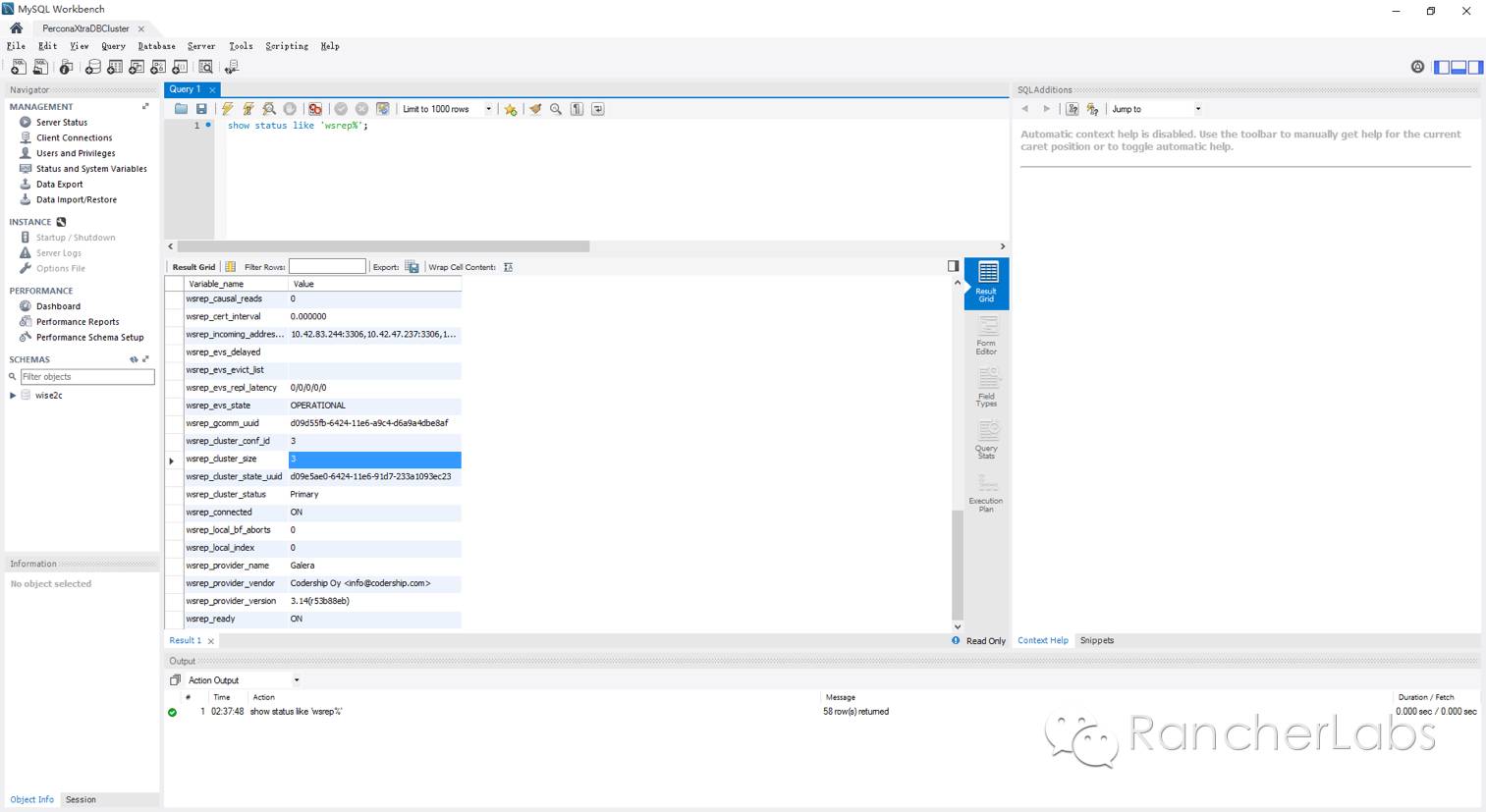
以上PXC集群运行于容器之上并被Rancher平台管理,其中的具体实现细节较多,因为我们需要这样的数据库集群满足弹性伸缩的要求,举例来说也就是可以动态的将集群节点数由3个增加至更多,那么必然每个节点的配置文件需要动态的进行更新,要做到这一点,我们可以结合confd与Rancher的metadata元数据服务来实现,当然这里涉及到数据库集群专有的技术,giddyup专有工具的结合也是必不可少的选择。https://github.com/Flowman/docker-pxc
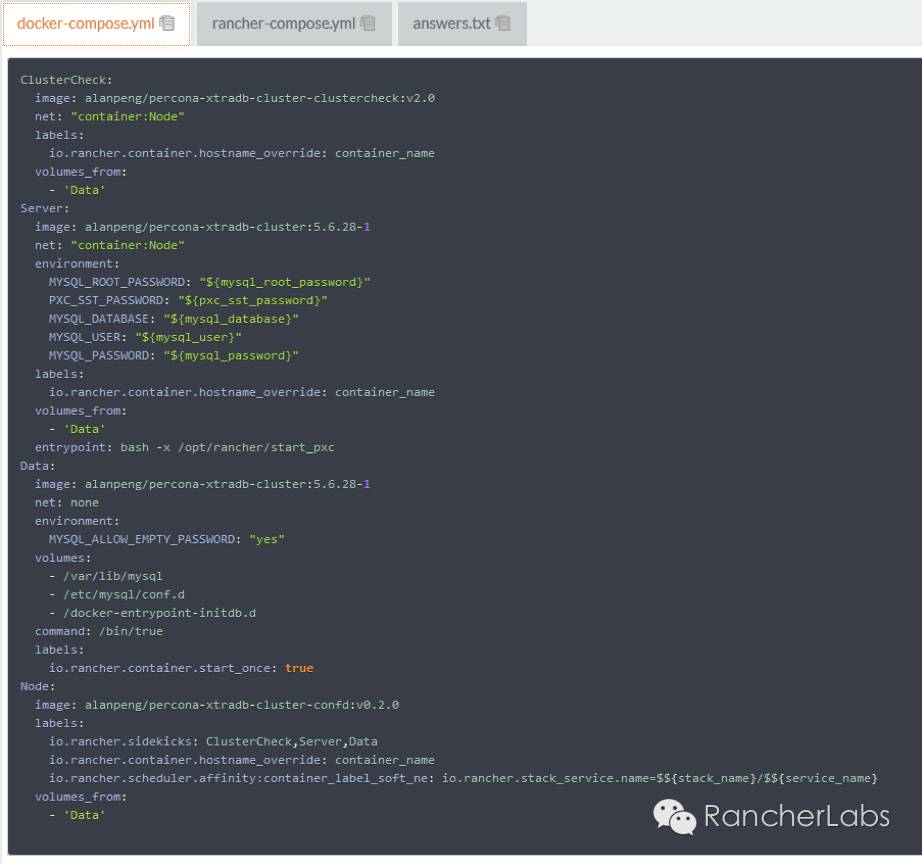
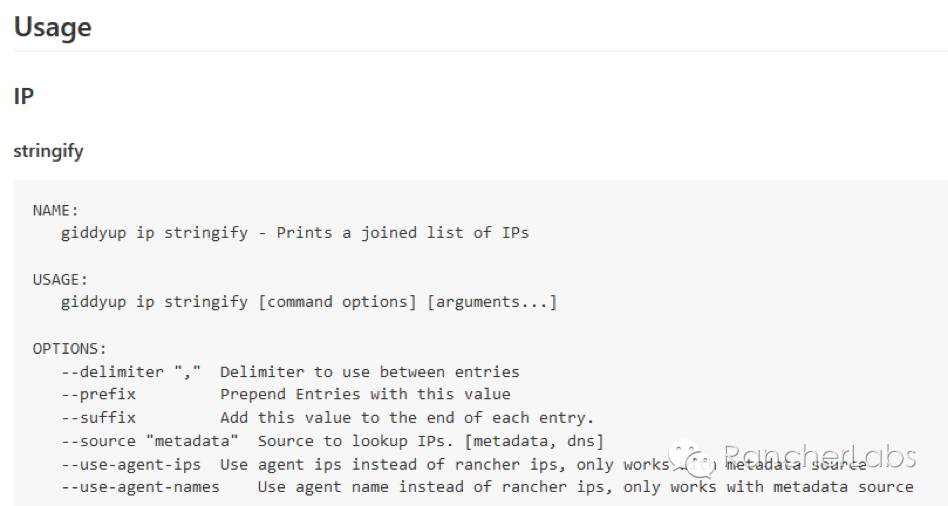
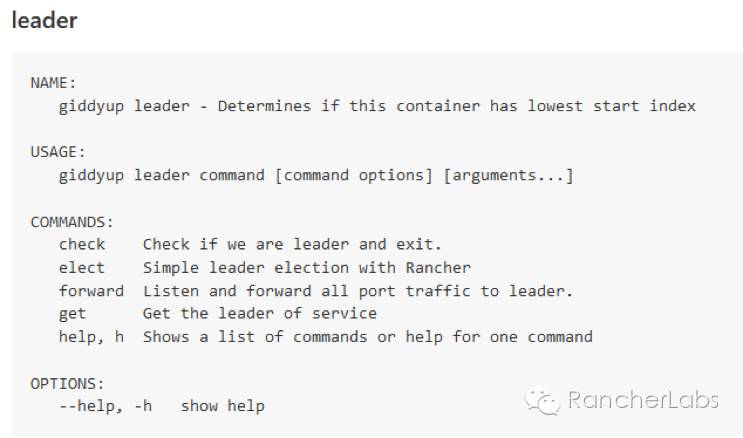
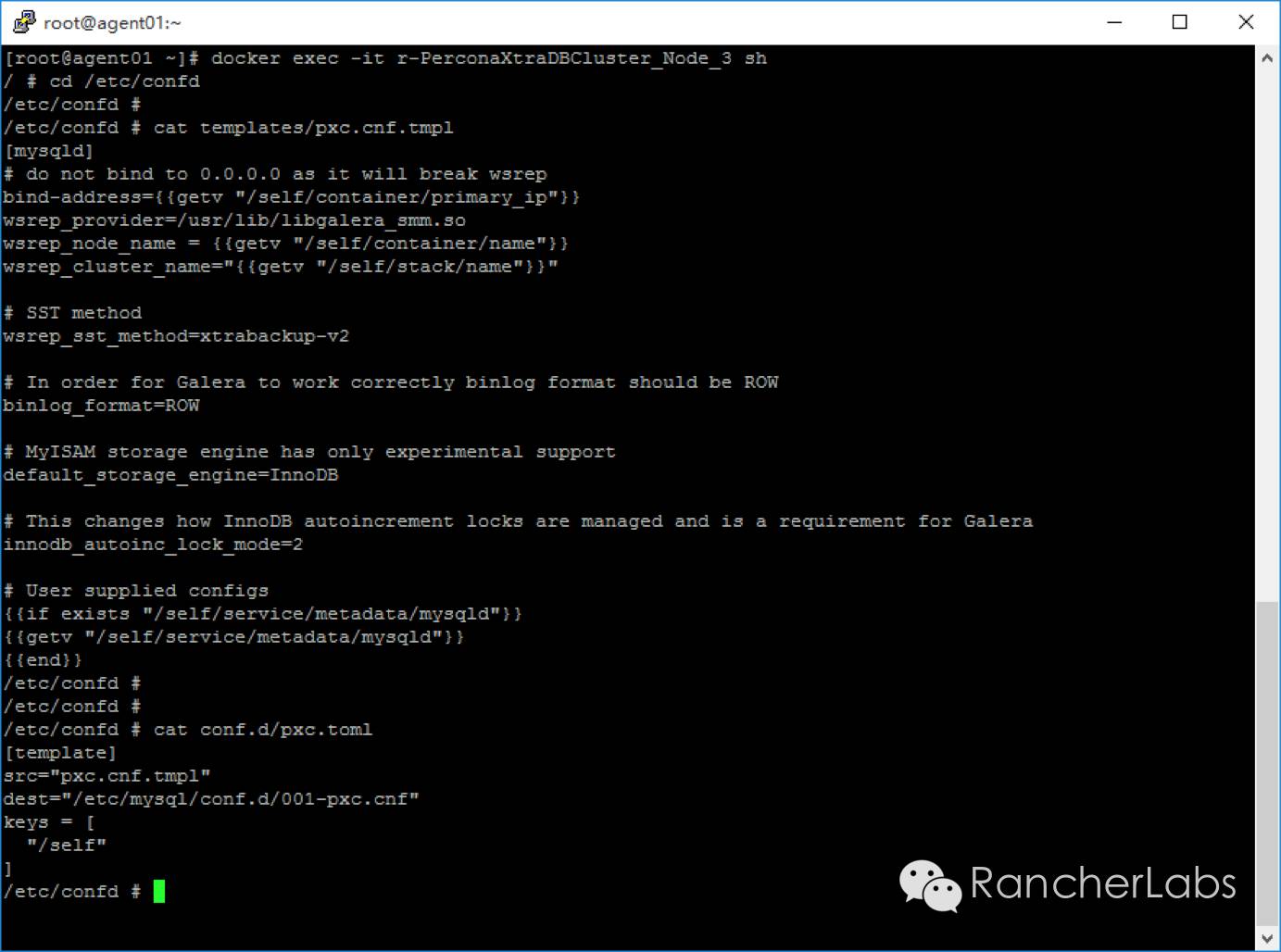
https://github.com/Flowman/docker-pxc-confdhttps://github.com/Flowman/docker-pxc-clustercheckhttps://github.com/cloudnautique/giddyup在数据库集群服务的启动脚本https://github.com/Flowman/docker-pxc/blob/master/start_pxc里我们使用了giddyup工具,其中比较重要的命令有以下项:获取集群节点成员IP列表,请参照本篇前面章节中my.cnf文件中提及的wsrep_cluster_address=gcomm:// …探测当前容器节点是否属于数据库集群的bootstrap角色(leader)https://github.com/kelseyhightower/confd 它对rancher提供了很好的支持,能够与Rancher的metadata元数据服务紧密结合:如何与元数据结合?confd有两个重要文件,一个是模板文件,一个是配置文件,其执行过程就是从backends对象例如Rancher的metadata获取数据,然后将其更新至真正被服务调用的配置文件中去:
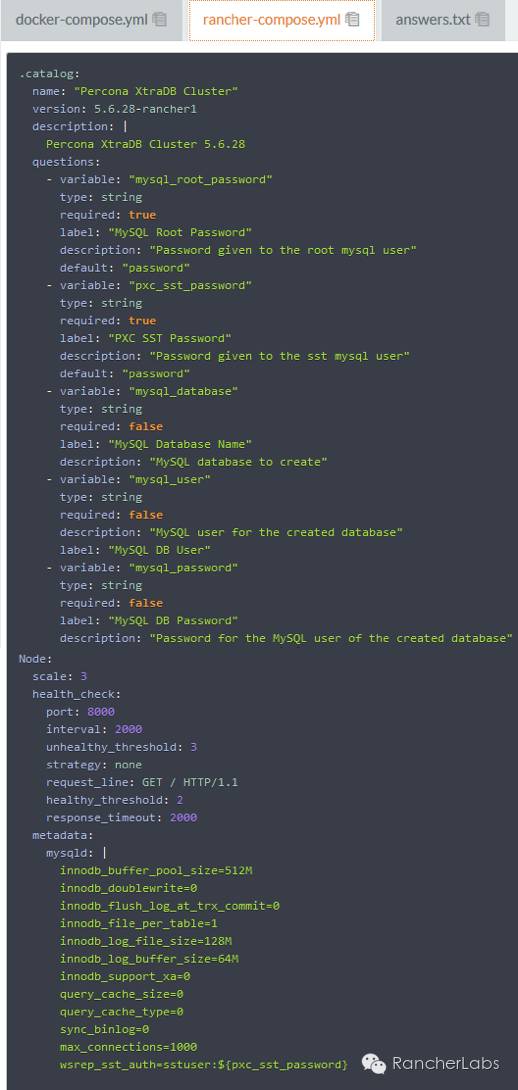
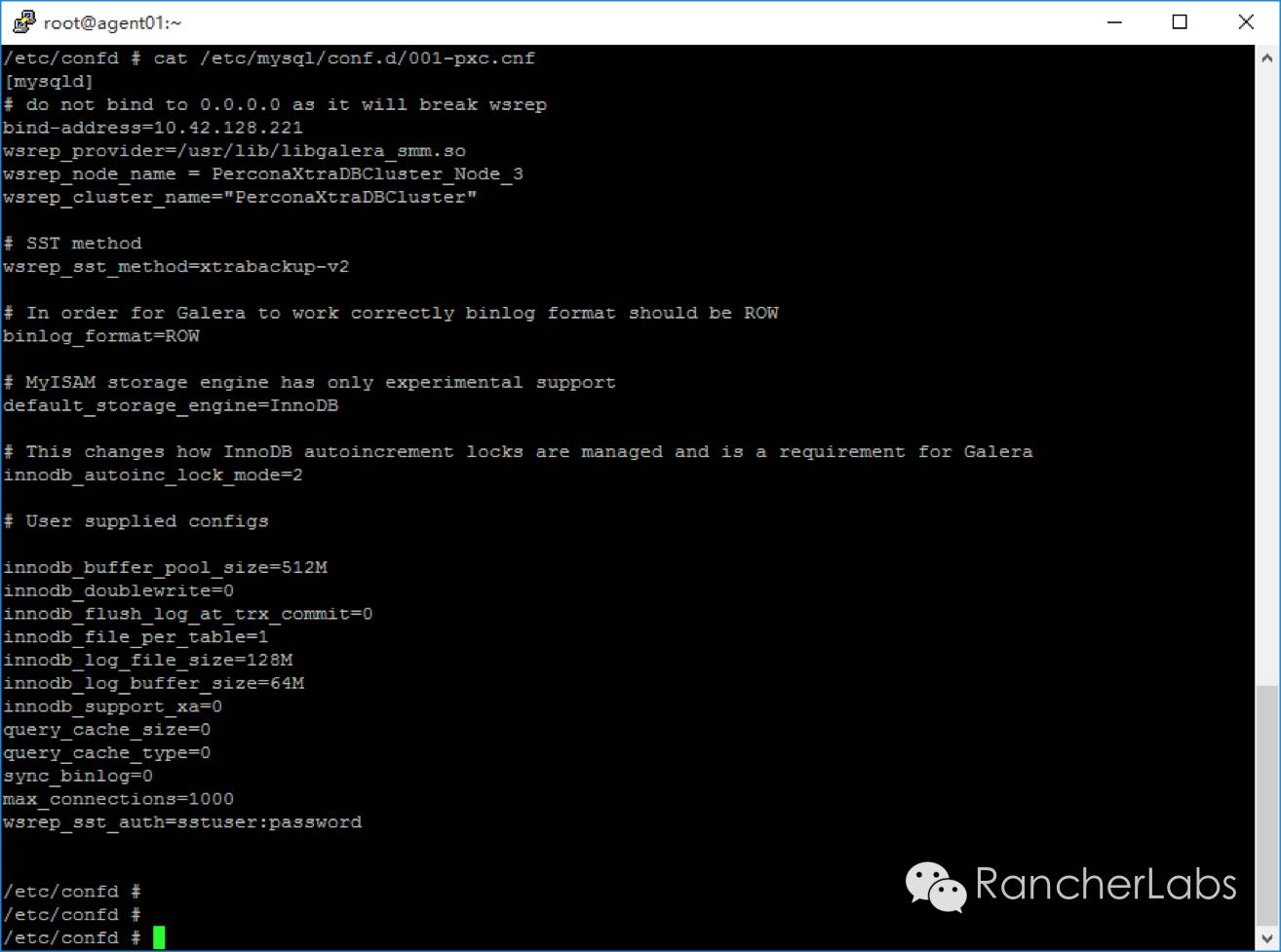
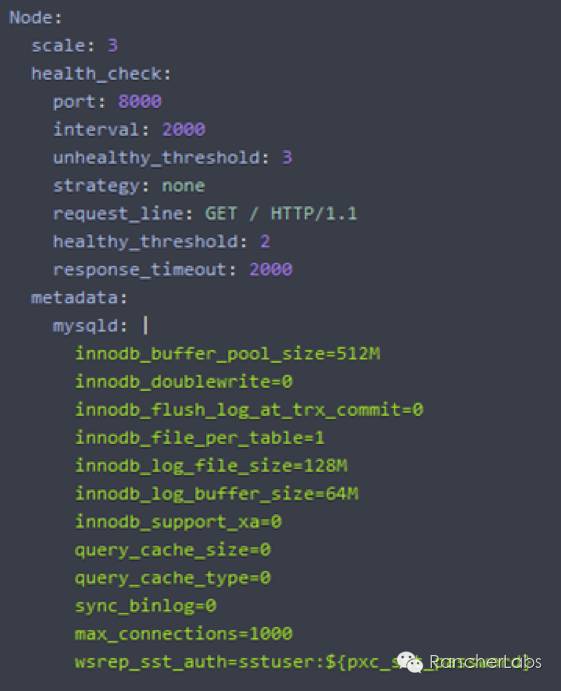
这里的pxc.cnf.tmpl文件是模板文件,而pxc.toml文件则是配置文件。confd的配置文件是建立一个服务,监控特定的backends对象(例如etcd、rancher元数据等等)的键值以及当值发生变化时执行某些操作。其文件格式是TOML,易于使用,其规则跟人的直觉也相近。我们可以看到容器执行期间,Rancher预先在rancher-compose.yml中定义的metadata元数据通过confd将一些重要参数传递给了数据库集群服务的配置文件my.cnf:
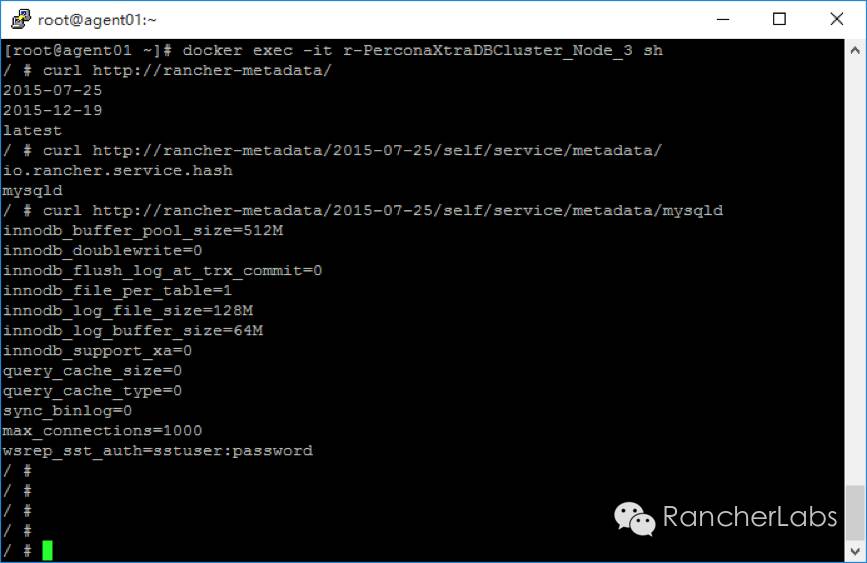
我们知道Rancher的metadata元数据是有版本差异的,那么如何知道在这个PXC数据库集群里它调用的元数据从何而来呢?
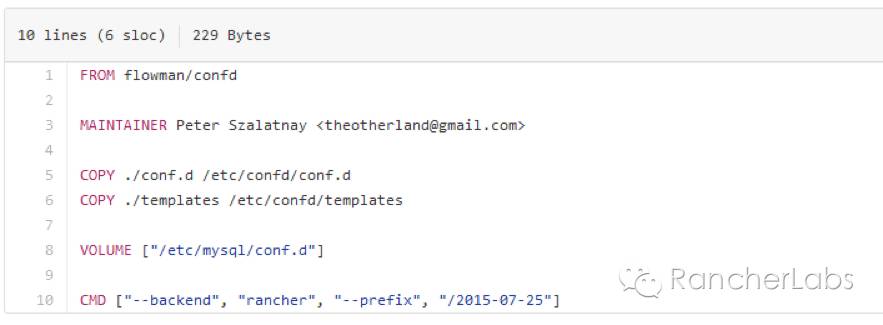
https://github.com/Flowman/docker-pxc-confd/blob/master/Dockerfile
这里从mysql元数据服务项返回的值正是我们在rancher-compose.yml文件中预先定义好了的:
从Percona XtraDB Cluster这个Rancher的Catalog项目,我们可以较为全面的理解confd配置服务是如何与Rancher的元数据服务进行结合的,这样就能实现较为复杂的数据库集群应用完全自动化的实现弹性伸缩功能。