




一、引言




本号在文章《用Python写简单的机器翻译程序(1)》中给出了一个调用谷歌翻译网页版接口的程序,可以实现一个简单的机器翻译功能。
当时就想能否模仿这个思路写一个调用百度翻译的Python程序呢?结果发现构造网址没有问题,构造的网址在浏览器中打开就能在浏览器中看到翻译的结果 。
例如,在谷歌浏览器输入如下网址(网址中可以直接带中文),然后敲回车键:
https://fanyi.baidu.com/translate?#zh/en/你好。
我们会看到如下的网页:
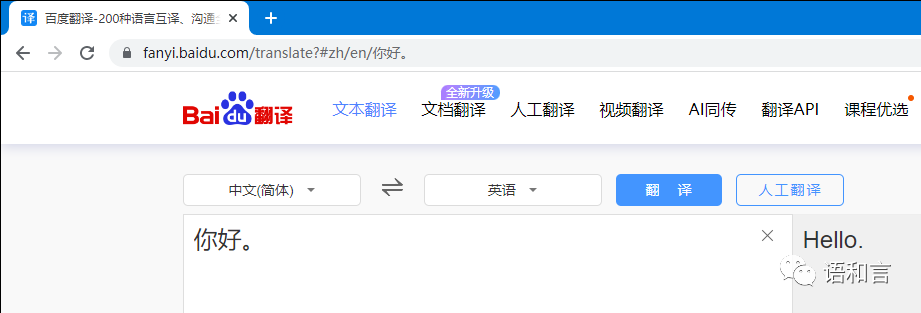
不过,令人遗憾的是,我们查看网页的源代码却找不到原文和译文,这也就意味着即便我们用get方法构造网址获取了百度翻译的网页源代码,也无从得到译文。
我们需要向它提交如下数据:
posData = {"query": txt, # 要翻译的原文本"from": "zh", # 原文本的语言代码,这里是汉语"to": "en", # 目标语代码,这里是英语"sign": "***.***","token": "***",}
我喜欢小猫咪。小猫咪非常可爱。
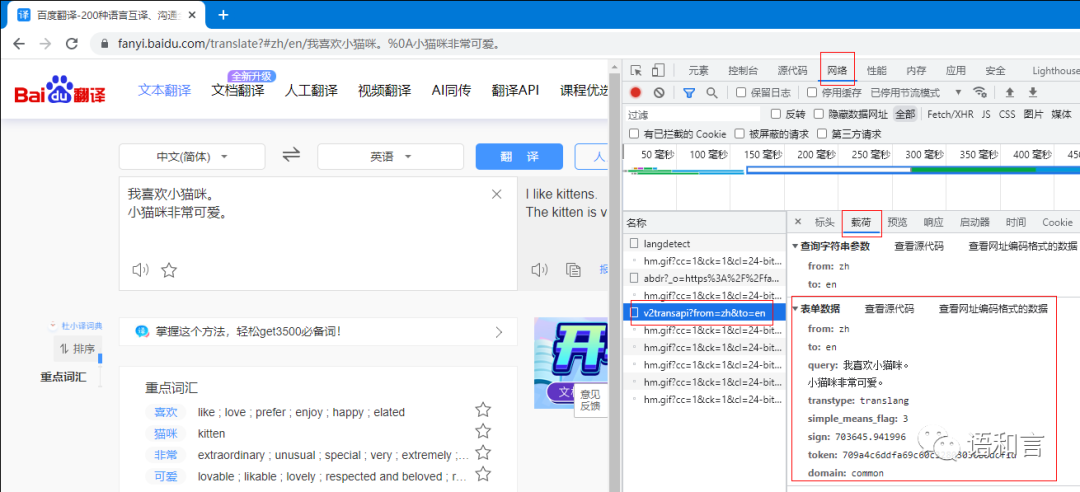

上述程序的运行结果如下:
原文本:我喜欢小猫咪。小猫咪非常可爱。目标文本:I like kittens.The kitten is very cute.
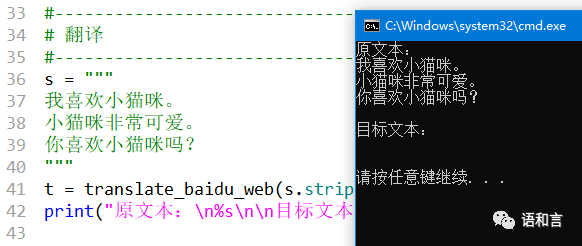
赶紧在源代码的第25行和第26行中间插入一个print语句,看看调用百度api的返回值是啥。再次运行程序之后,得到如下结果:
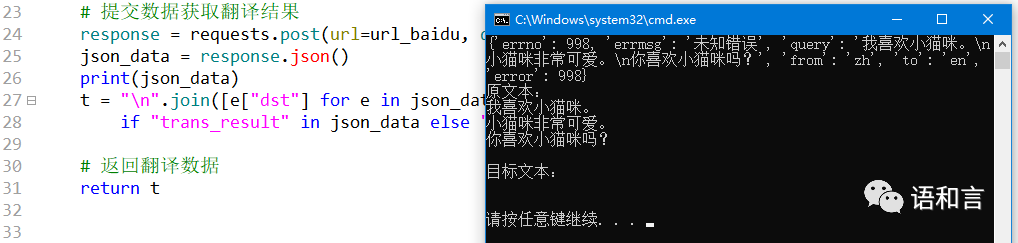
通过查资料知道,向百度提交的的表单数据中的sign值是根据输入文本实时计算的,输入文本变了,sign值也会随之变,我们的程序只变了输入文本,没有改变sign值,所以会报错。百度翻译接口计算sign值的工作是通过JS文件来完成的。
网上有很多资料告诉我们如何通过按F12来一步步找到计算sign值的代码,但我尝试了几天,均以失败而告终,于是从网上下载了几个能生成sign值的JS文件,对比了一下,发现它们生成的结果是一样的,于是随机选了一个,然后修改上面的程序,把sign值从固定值改为JS计算。

原文本:我喜欢小猫咪。小猫咪非常可爱。你喜欢小猫咪吗?目标文本:I like kittens.The kitten is very cute.Do you like kittens?
网上下载的JS文件生成的sign值也不对,估计是百度的sign值生成算法有变化。
我们欣喜地发现居然可以翻译三行文字了,赶紧再加一行试试,结果发现翻译失败了。
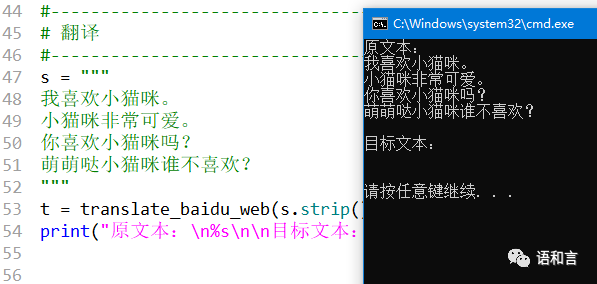
我们把上述程序的第30绗修改一下,不用JS计算sign值,而是用手工办法把四行文本输入到百度翻译网页中,按F12获取sign值,这下子,程序就能获取正确的翻译结果了。
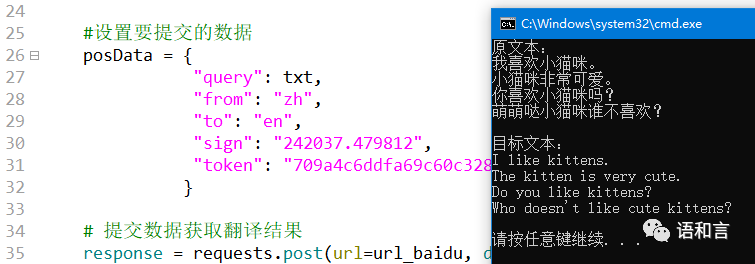
这说明网上下载的计算sign值的JS文件都不对,也可能是百度更改了sign值的计算方法,所以以前正确的JS文件现在不正确的。
我们期待以后能亲自找到计算sign值的JavaScript代码,或者能下载到正确的JS文件。
在下载到正确的JS文件文件之前,我们想用百度的翻译,难道就没有办法了吗?手动打开网页当然是可以的,但我们Pythoner可不能满足于这种非必要的低效手工劳动。

原文本:春天来了!春天来了!我们几个孩子,脱掉棉袄,冲出家门,奔向田野,去寻觅春天。春天像个害羞的小姑娘,遮遮掩掩,躲躲藏藏。我们细心地找啊,找啊。小草从地下探出头来,那是春天的眉毛吧?早开的野花一朵两朵,那是春天的眼睛吧?树木吐出点点嫩芽,那是春天的音符吧?解冻的小溪叮叮咚咚,那是春天的琴声吧?春天来了!我们看到了她,我们听到了她,我们闻到了她,我们触到了她。她在柳枝上荡秋千,在风筝尾巴上摇啊摇;她在喜鹊、杜鹃嘴里叫,在桃花、杏花枝头笑……目标文本:Spring is coming! Spring is coming!Our children took off their cotton padded jackets and rushed out of the house to the fields in search of spring.Spring is like a shy girl, hiding. We searched carefully.The grass sticks its head out from the ground. Is that the eyebrow of spring?One or two early wild flowers are the eyes of spring, aren't they?The trees are spitting out tender buds. Is that the note of spring?The thawing brook is tinkling, isn't it the music of spring?Spring is coming! We saw her, we heard her, we smelled her, we touched her. She swings on willow branches and shakes on kite tails; She cries in the mouth of magpies and cuckoos, and laughs in the branches of peach and apricot flowers
运行过程录成视频如下。
通过上面的视频,我们看到,程序运行之后,自动打开了百度翻译的网页,自动输入翻译内容并点击翻译按钮,然后模拟键盘操作将翻译页面另存为d:\ftp\tmp,html,然后程序自动从中提取翻译结果。
虽然在操作过程中,输入文字的内容被广告遮挡,但整个过程还是全自动的。另外,由于等待保存需要一定的时间,我们不知道这个时间究竟有多长,这里用了一个小技巧:设置了一个循环,在try...except...结构中用修改文件名的办法来判断本地文件是不是保存完毕。
