




一、引言
二、新书推广
《Python程序设计(基于计算思维和新文科建设)》,ISBN:9787121435577,胡凤国,电子工业出版社,2022年6月。

本书是电子工业出版社在国内较早采用纸质版+电子版的创新图书发行模式的第一次尝试。本书是这套创新图书的纸质版部分,与之内容互补的电子版图书将稍后出版。
本书的内容包含基础篇和排错篇两部分:
基础篇介绍Python程序设计的入门知识,共12章,包括:
⑴ Python简介
⑵ Python软件的安装和Python程序运行;
⑶ Python的基本概念(对象、数据类型、表达式、内置函数);
⑷ 输入和输出;
⑸ 程序设计的三种基本结构;
⑹ 函数和类;
⑺ 序列操作(列表、元组、集合、字典);
⑻ 字符串;
⑼ 正则表达式;
⑽ 文件读写;
⑾ 目录与文件操作;
⑿ 常用标准库介绍。
排错篇总结初学者常遇到的错误并介绍程序调试方法,包含2章:
⒀ Python错误类型;
⒁ Python代码调试。
与本书内容互补的电子版图书包含文本篇和应用篇两部分:
文本篇:介绍字符集、编码和文本文件读写的知识,包含了对国家规范《通用规范汉字表》8105个汉字当中难以输入和难以显示的汉字的处理。
应用篇:介绍Word、Excel、PPT、PDF、图片等常用办公文件的处理,是大家提高办公和科研效率的好帮手。
本书配套有详细的PPT和教学大纲,还有全部例题的程序代码和绝大部分思考题的程序代码。
本书配套PPT里面还加入了配套电子版图书中的部分内容,比如字符集和编码,不同编码的文本文件的读写,Word、Excel、PPT、PDF等一些常用办公文件的读写。
本书的配套资源可以在电子工业出版社官网下载。
本书的读者对象:
可拿本书当工具书,本书的配套程序会为您节省效率,在当前大数据和新文科的背景下,本书可以为相关领域的量化研究提供技术支持。
本书配套的电子版图书中的编码和文本处理知识也可以作为理工科教师和科研人员处理文本数据的参考资料之一,毕竟专门开辟章节介绍国家标准《通用规范汉字表》汉字处理的程序设计图书并不多见。
本书有专门的海龟画图章节,有大量的有趣数学题目,可以培养学生的计算思维,适合对编程感兴趣的中小学生阅读,也适合打算让娃参加编程辅导班的家长朋友参考。
本书在各大实体书店和网店均有销售。尤其在电子工业出版社天猫旗舰店销售火爆,月销量100+。京东、天猫、当当的购买渠道如下(可扫码直达购买页面)。



三、题目
【题目描述】
假设语料目录test及其子目录下有一批英文文本文件,请写一个Python程序来统计该目录下所有文本文件中每个英文字母的出现次数,大小写英文字母分别统计。统计结果按英文字母频次的降序排列,如果频次相同,再按英文字母的升序排列。统计结果正确排序之后,请将排名前10位的英文字母及其频次输出到屏幕。
【输出要求】
每个英文字母及其频次的输出信息占一行;
每行信息先输出英文字母,再输出一个制表符,再输出该英文字母的频次;
除了10行应该输出的信息之外,不得额外输出其它任何信息。
【其它要求】
目录test放在Python程序放在同一个目录下;
Python程序的运行结果以在IDLE中的运行输出结果为准;
不得有任何输入操作;
可以使用标准库,不得使用任何扩展库和自定义库。
我们先来分析一下整个任务。我们需要先获取test目录及所有子目录下的所有文本文件,用循环获取每一个文件名,然后在循环体中对单个文本文件进行字符频次统计,所有文件都统计完之后,再对统计结果进行排序,最后输出排序结果的前10个字符及其频次。
这个思路可以用伪代码描述如下:
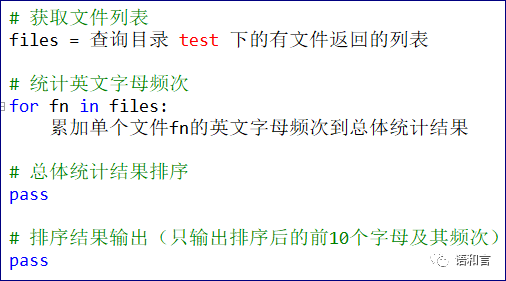
这里的总体统计结果是一个字典,具体我们进一步细化:

这里的排序原则是一个函数或一个lambda表达式。列表对象的sort方法或者内置函数sorted都有key参数和reverse参数,两者的key参数和reverse参数在用法完全一致。这两个参数为序列类对象的排序带来了很大方便。拙著《Python程序设计(基于计算思维和新文科建设)》第193和194页有对列表对象的sort方法的详细介绍。

书里讲了对列表对象的元素进行排序,这里补充一下对字典的排序,假设字典对象d存储的是某文本的字符频次统计结果。
直接对字典进行排序相当于对键进行排序。
>>> d = {'p':20, 'y':10, 't':35, 'h':20, 'o':10, 'n':60}>>> sorted(d) # 对字典的键进行排序,默认是升序排列['h', 'n', 'o', 'p', 't', 'y']>>> sorted(d, reverse=True) # 对字典的键进行排序,指定要降序排列['y', 't', 'p', 'o', 'n', 'h']>>> sorted(d.keys()) # 等同于 sorted(d)['h', 'n', 'o', 'p', 't', 'y']
如果要对字典中键值对的值进行排序,需要对 d.values() 进行排序。
>>> d = {'p':20, 'y':10, 't':35, 'h':20, 'o':10, 'n':60}>>> sorted(d.values()) # 对字典的值进行排序,默认升序[10, 10, 20, 20, 35, 60]>>> sorted(d.values(), reverse=True) # 对字典的值进行排序,指明降序[60, 35, 20, 20, 10, 10]>>> sorted(d.values(), key=lambda x:-x) # 对字典的值进行排序,达到了降序效果[60, 35, 20, 20, 10, 10]
注意上面代码中的最后一个例子,没有用参数reverse=True指明降序排列,但也达到了降序排列的效果,因为我们的排序原则是用 d.values() 当中的每个元素的相反数的升序顺序对 d.values() 当中的元素进行排序,就达到了对 d.values() 当中的元素进行降序排列的目的。这个例子很有用,这对于存储字符频次的字典对象按频次排序键值对有启发意义。
对字典对象的键值对进行排序需要对 d.items() 返回的对象进行排序,示例如下:
>>> d = {'p':20, 'y':10, 't':35, 'h':20, 'o':10, 'n':60}>>> sorted(d.items())[('h', 20), ('n', 60), ('o', 10), ('p', 20), ('t', 35), ('y', 10)]
d.items() 当中的元素都是二元组,而且这些二元组的第一个元素都是字符,第二个元素都是整数,字符都可以比较大小,整数也都可以比较大小,所以这些二元组是可以比较大小的。上面的代码是对d.items() 当中的二元组进行升序排序。
如果想按频次对二元组进行排列(也就是按二元组的最后一个元素进行排序),就得用lambda表达式:
>>> d = {'p':20, 'y':10, 't':35, 'h':20, 'o':10, 'n':60}>>> sorted(d.items(), key=lambda e:e[1])[('y', 10), ('o', 10), ('p', 20), ('h', 20), ('t', 35), ('n', 60)]
上面代码是按频次的升序排列的,如果希望按频次的降序排列,可以加个参数reverse=True。
>>> d = {'p':20, 'y':10, 't':35, 'h':20, 'o':10, 'n':60}>>> sorted(d.items(), key=lambda e:e[1], reverse=True)[('n', 60), ('t', 35), ('p', 20), ('h', 20), ('y', 10), ('o', 10)]
如果不想加参数reverse=True,也可以这样来达到目的:
>>> d = {'p':20, 'y':10, 't':35, 'h':20, 'o':10, 'n':60}>>> sorted(d.items(), key=lambda e:-e[1])[('n', 60), ('t', 35), ('p', 20), ('h', 20), ('y', 10), ('o', 10)]
我们发现,上面两种方法得到的排序结果都有一个特点:频次相同的情况下,这些二元组的排序并不是字符小的排在前面。
如果我们希望先按频次的降序排列,频次相同的再按字符的升序排列,一个要求升序一个要求降序,所以用reverse参数就不好解决问题,我们可以这样考虑:
用lambda表达式把d.items() 当中的的元组(char, freq)变成(-freq,char),我们就指定这个lambda表达式作为排序原则。
>>> d = {'p':20, 'y':10, 't':35, 'h':20, 'o':10, 'n':60}>>> sorted(d.items(), key=lambda e:(-e[1], e[0]))[('n', 60), ('t', 35), ('h', 20), ('p', 20), ('o', 10), ('y', 10)]
这个结果我们很满意,这解决了字符频次之后的排序问题,现在修改我们上面提出来的思路框架。

至于排序结果输出,这个太简单了吧,for循环顺次访问前10个元素就行。
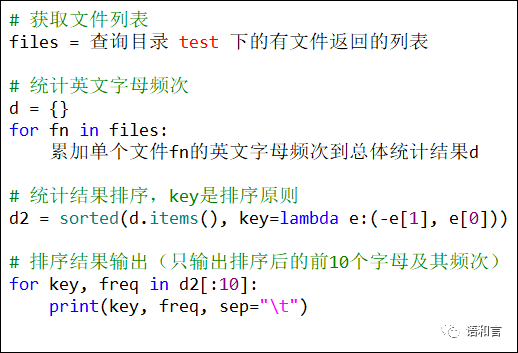
上面的思路越来越像程序了,下面继续细化这个思路。先来看单个文本的字符频次统计,一个文本文件,读取到内容之后就变成个字符串了,所以,我们还是归结到一个英文句子如何字符频次统计。这不就是本号前面发布的文章《Python字符频次统计程序详解》做过的事情嘛,点击题目可以跳转到该文章,扫下面的二维码也能跳转过去。

有了这个基础,我们直接给出单个字符字符频次统计的代码:

当然,本文的作业任务要求只统计大小写英文字母,所以,我们改进一下上面的程序。

如果是文件的话,我们只需要把变量s赋值为字符串的那一行改为从文件中读取内容就行了。关于如何读取文本文件的内容,拙著《Python程序设计(基于计算思维和新文科建设)》第290和291页给出了五种读取文本文件的方式。

因为英文文本不涉及到编码的问题,所以读取英文文本比较简单,我们这里用最简单的一种读取方式修改上面的字符频次统计代码。

于是,单个文本文件的英文字母频次问题解决了,可以整合到我们的作业思路里面去了。

剩下的问题就是如何获取目录及子目录下的所有文件了。关于这个问题,我在中国传媒大学的课堂上给同学们分享了一个自定义的Python函数get_all_files_in_path_and_sub,在今年7底淮北举办的 外语教育技术与专项科研技能培训班 上给老师们分享的是自定义函数find_files_walk,前者是用os.listdir实现的(需配合递归函数),后者是用os.walk实现的。
拙著《Python程序设计(基于计算思维和新文科建设)》第310到313页详细介绍了os.listdir和os.walk的用法,感兴趣的读者可以去买一本来看。这里给出两个自定义函数。
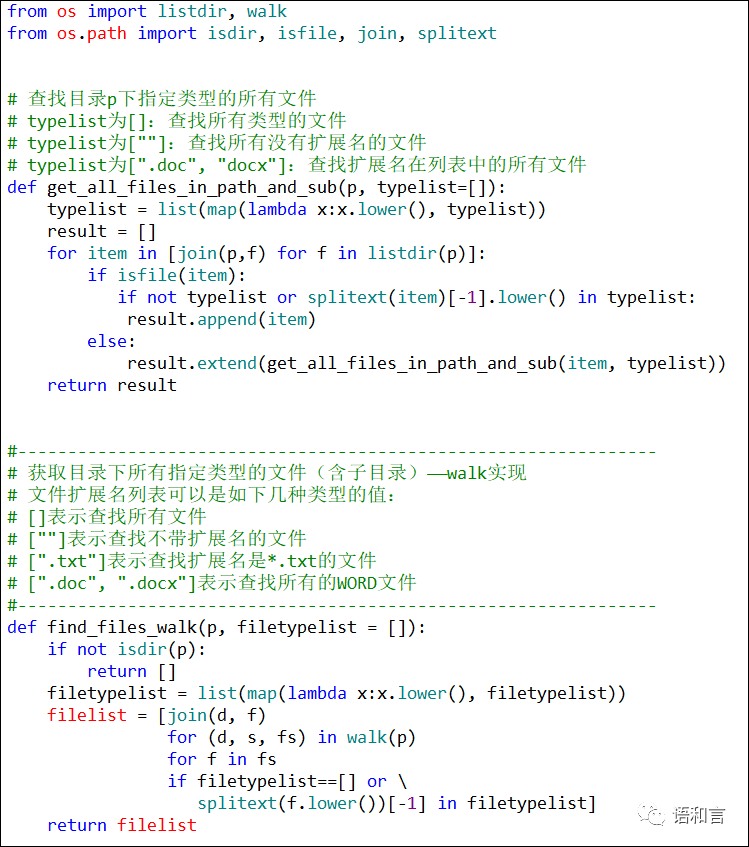
我们使用其中的一个函数就够了,比如选用find_files_walk,把它整合到我们的作业思路里面,整个作业的程序就出来了。不算空白行和注释行,一共23行代码。
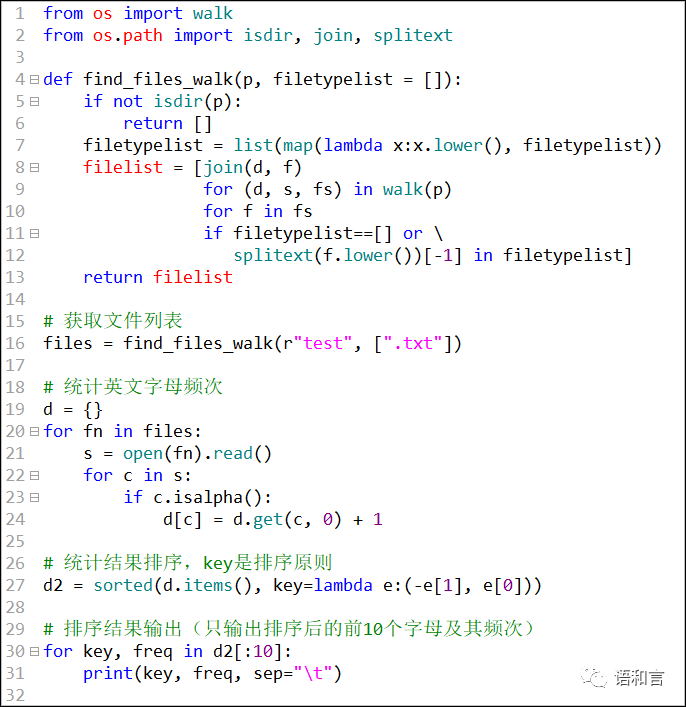
其实,如果不是要交作业的话(作业一般会要求不能调用扩展库或自定义库),引文函数 find_files_walk 在语言文字工作中是常用的,我们完全可以放在自定义函数库中。假定我们把函数 find_files_walk 连同它所需要的 import语句一起放到自定义函数库 E:\hfgpy\hfgfunc.py 当中,整个完成作业的代码可以缩短到 13 行。
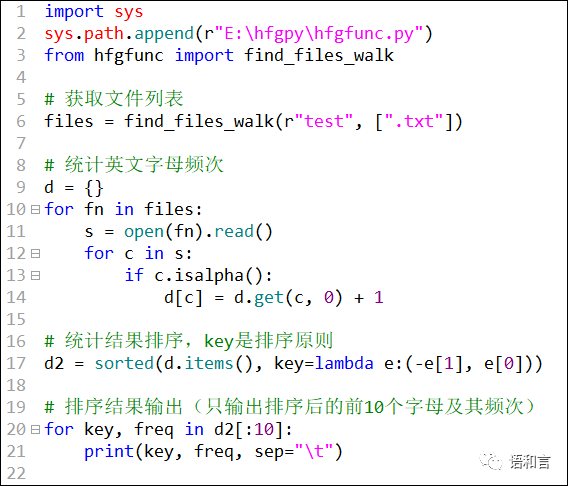
关于如何建立自定义库并从自定义库中导入函数,本号之前也发过几篇文章,感兴趣的读者朋友可以参考一下,直接点击题目或扫二维码。


拙著《Python程序设计(基于计算思维和新文科建设)》第6.7节详细介绍了自定义函数库的建立和调用问题,感兴趣的朋友可以到书的第170到172页去了解详情。
如果不用通过 os.listdir 或者 os.walk 建立的自定义函数的话,我们还可以用 glob标准库的 glob 函数来查找目录及子目录下的指定类型的文件,相应地,本文提出的作业题可以写出如下的程序。

关于 glob 标准库的 glob 函数的用法,本号之前也有文章,具体请参见《对目录下所有文本文件进行分词的最短代码2》,点击题目或扫码前去了解。

题外话,本号真是个小宝库,有心的读者不经意间说不定就能翻出一些宝贝来。欢迎关注!
本号的文章一般不贴能够运行的程序的源代码,前几天发的几篇文章贴了源代码是为了方便小编在淮北的 外语教育技术与专项科研技能培训班 上跟老师们交流,现在培训班顺利结束,本号的主要读者对象不再是培训班的老师们,而是恢复为上Python课的学生或者喜欢学习Python语言编程的读者朋友。
对于Python学习者来说,笔者不主张复制粘贴代码简单运行了事,强烈建议Python学习者自己敲代码,在不断的敲错纠错中才能提高自己的编程技能。如果有人文社科领域的教师或科研人员需要代码,可以私下联系。
如果需要跟图书《Python程序设计(基于计算思维和新文科建设)》的作者胡凤国老师进行交流,请发电邮:cuchufengguo@163.com ,也可以给公众号留言进行交流。
欢迎关注微信公众号“语和言”,本书未来及展开或不曾收录的Python知识将不定期在本公众号进行补充。
语和言公众号还有读者交流群,经常跟作者交流的读者朋友可以入群一起讨论问题。
