




一、任务
现有若干个PDF文件,需要提取其中的文本内容。目前,单机版和网页版的PDF转TXT软件有很多,用那些软件对PDF文件进行处理之后就能得到TXT文件,再用Python去批量读取就可以了。
但是,这样的话,多多少少会有不方便之处。比如,我们做爬虫从网上爬取到一些PDF文件,需要从中提取一些信息。如果借助于现有的单击版或者网页版PDF转TXT软件的话,那我们得手动进行,效率肯定会慢很多。因此,我们希望用Python自动获取PDF文件的内容。
目前用pdfminer扩展包的比较多,该扩展包对应Python 3.x版本是pdfminer3k。
二、环境
Win7中文旗舰版64位 + Python 3.64 64位 + pdfminer3k
三、安装
命令行pip安装即可。安装成功之后,Python的安装目录的scripts目录下会出现pdf2txt.py这个文件,我们调用它来做pdf转txt的工作。
为了测试是否安装成功,我们将一个小点的PDF文件(大的PDF文件浪费时间)复制到pdf2txt.py所在的目录下。然后在命令行窗口中将当前目录切换为pdf2txt.py所在的目录。在我的电脑上,这个目录是:
C:\Python\Python364\Scripts
假定我们复制过来的PDF文件是test.pdf,我们可以用如下的命令把它转换为txt文件:
python pdf2txt.py -o test.txt test.pdf
大家应该都是老司机了,命令参数不再解释。如果出现了test.txt,就说明转换成功。
如果PDF文件带了密码,比如有一个a.pdf的PDF文件,需要用密码abc打开它,那么,我们将a.pdf转为TXT文件的命令将会是如下的样子:
python pdf2txt.py -P abc -o a.txt a.pdf
我们在Python代码中,只需要构造出这样的DOS命令即可,剩下的事情交给pdf2txt.py就行了。
四、代码
本代码的思想来自董付国老师公众号“Python小屋”的推文,原贴地址是: https://mp.weixin.qq.com/s?__biz=MzI4MzM2MDgyMQ==&mid=2247483970&idx=1&sn=8ce7dc363999760061ed921834d37067&chksm=eb8aa918dcfd200ebe4b747953c6695c9b6cb3aa0312bf74520a28b8aa51c3a474936fded5c7&scene=21#wechat_redirect
这里感谢董付国老师。
本代码比董付国老师的代码多了处理PDF密码的功能。如果PDF文件是加密的,则代码对PDF文件名有个要求:需要在主文件名的后半部分给出密码,文件名格式要求如下:
其他字符串+密码+冒号+密码值.pdf
例如:
test密码:12345.pdf
英语词典密码:abc.pdf
全唐诗密码:a123.pdf
代码在运行过程中会自动判断PDF文件有没有密码。
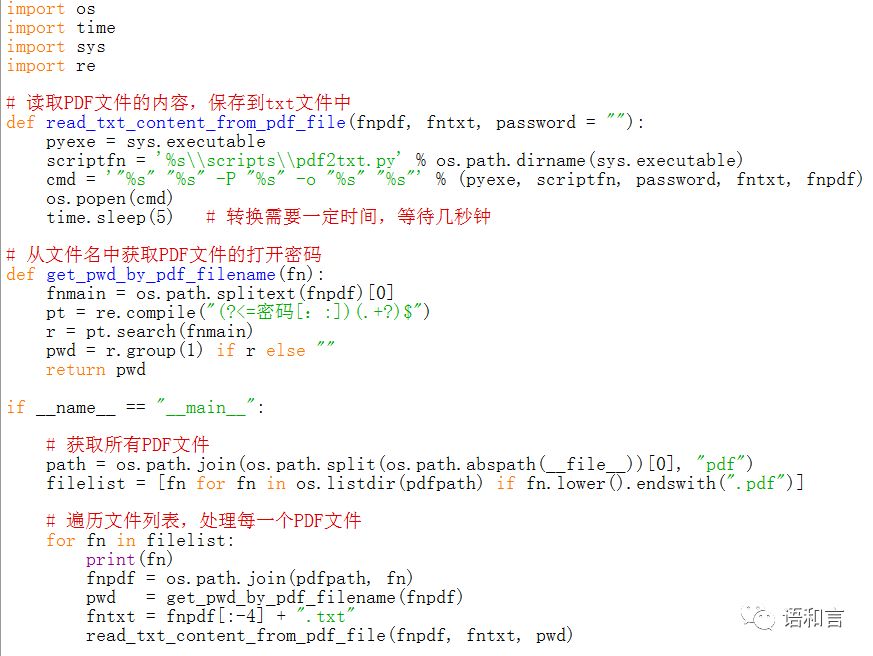
五、测试
对于一般的没有密码的PDF文件,比如WORD和WPS导出的PDF文件,这个程序能正确转为TXT。
但是,对于一些加了密码的PDF文件,效果不太理想,一些文件读出一半,另外一些文件一点都读不出来。
个别的无密码文件,也读不出来内容来,但是用Acrobat另存为文本文件就能得到文本内容。
这真是很奇怪的事情。不过,也没什么好奇怪的,毕竟pdfminer3k很多年没有更新了,有点bug是正常的。
六、结语
感谢pdfminer3k的开发者!
希望pdfminer3k改正bug,或者出现更优秀的PDF转TXT扩展包。
