




一、引言
前面写了两篇短文介绍如何用Python判断文本文件的编码方式。
现在发现判断方法仍会有一些瑕疵。再改进一下。这次改进,只是耍了一个小聪明,依然没有胆量去碰触语言层面的统计方法。
二、环境
Win 7中文专业版 32位 + Python 3.64 + MinGW GCC4.5.2
三、准备
我们的思路是用C语言程序生成10个各种编码的文本文件,然后用Python去判断这些文本文件的编码并读取文件。
C语言代码如下:
#include <stdio.h>
int main(int argc, char *argv[])
{
FILE *fp;
char *s_gb18030 = "\x97\x31\xA4\x35";
char *fn_gb18030 = "米查gb18030.txt";
char *s_unicode = "\xff\xfe\x57\xd8\xd7\xde";
char *fn_unicode = "米查unicode.txt";
char *s_unicode_nobom = "\x57\xd8\xd7\xde";
char *fn_unicode_nobom = "米查unicode_nobom.txt";
char *s_unicode_bigendian = "\xfe\xff\xd8\x57\xde\xd7";
char *fn_unicode_bigendian = "米查unicodebigendian.txt";
char *s_unicode_bigendian_nobom = "\xd8\x57\xde\xd7";
char *fn_unicode_bigendian_nobom = "米查unicodebigendian_nobom.txt";
char *s_utf8 = "\xef\xbb\xbf\xf0\xa5\xbb\x97";
char *fn_utf8 = "米查utf8.txt";
char *s_utf8_nobom = "\xf0\xa5\xbb\x97";
char *fn_utf8_nobom = "米查utf8_nobom.txt";
char *s_gb2312_1000 = "一千";
char *fn_gb2312_1000 = "一千.txt";
char *s_gb2312_xitong = "系统";
char *fn_gb2312_xitong = "系统.txt";
char *s_gb2312_liantong = "联通";
char *fn_gb2312_liantong = "联通.txt";
/* 生成"gb18030"编码的文本文件 */
fp= fopen(fn_gb18030, "wt");
fprintf(fp, "%s", s_gb18030);
fclose(fp);
/* 生成"unicode"编码的文本文件 */
fp= fopen(fn_unicode, "wt");
fprintf(fp, "%s", s_unicode);
fclose(fp);
/* 生成没有BOM的"unicode"编码的文本文件 */
fp= fopen(fn_unicode_nobom, "wt");
fprintf(fp, "%s", s_unicode_nobom);
fclose(fp);
/* 生成"unicode big endian"编码的文本文件 */
fp= fopen(fn_unicode_bigendian, "wt");
fprintf(fp, "%s", s_unicode_bigendian);
fclose(fp);
/* 生成没有BOM的"unicode big endian"编码的文本文件 */
fp= fopen(fn_unicode_bigendian_nobom, "wt");
fprintf(fp, "%s", s_unicode_bigendian_nobom);
fclose(fp);
/* 生成"utf8"编码的文本文件 */
fp= fopen(fn_utf8, "wt");
fprintf(fp, "%s", s_utf8);
fclose(fp);
/* 生成没有BOM的"utf8"编码的文本文件 */
fp= fopen(fn_utf8_nobom, "wt");
fprintf(fp, "%s", s_utf8_nobom);
fclose(fp);
/* 生成"gb2312"编码的文本文件“一千.txt” */
fp= fopen(fn_gb2312_1000, "wt");
fprintf(fp, "%s", s_gb2312_1000);
fclose(fp);
/* 生成"gb2312"编码的文本文件“系统.txt” */
fp= fopen(fn_gb2312_xitong, "wt");
fprintf(fp, "%s", s_gb2312_xitong);
fclose(fp);
/* 生成"gb2312"编码的文本文件“联通.txt” */
fp= fopen(fn_gb2312_liantong, "wt");
fprintf(fp, "%s", s_gb2312_liantong);
fclose(fp);
return 0;
}
这段代码生成的10个文件的编码和内容信息如下:
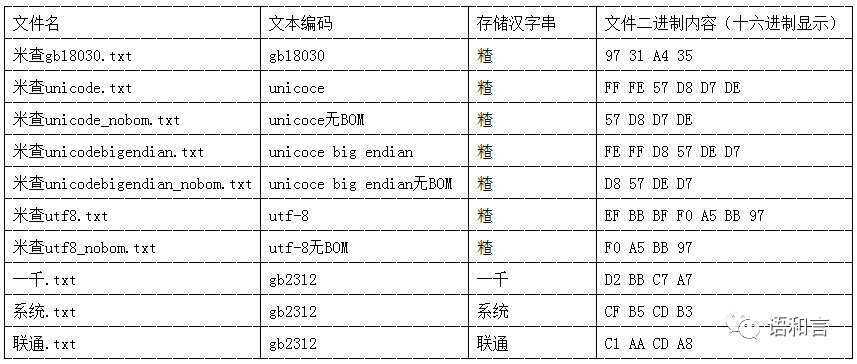
这里的汉字“𥻗”是《通用规范汉字表》第5989号汉字,它不是双字节的GBK字符,而是四字节的GB18030字符。它的Unicode编码和UTF-8编码如上表所示。
目前该汉字用一般的输入法敲不出来,就连Python的IDLE也不能显示这个字符。
上表中的“一千”、“系统”、“联通”是经常被文本编辑软件识别错误的中文字符串,这里把它们分别保存为GB2312编码的文本文件备用。
四、识别
Python识别代码如下:
import os
from mypy_code import get_files_with_special_ext_in_path
from mypy_code import get_the_encoding_of_txt_file_chardet
from mypy_code import get_the_encoding_of_txt_file_myself_guess_final
from mypy_code import get_the_encoding_of_txt_file_myself_guess_final2
from mypy_code import get_content_of_txt_file
if __name__ == "__main__":
# 获取当前脚本所在的目录
scriptfullname = os.path.abspath(__file__)
scriptfullpath = os.path.split(scriptfullname)[0]
# print(scriptfullpath)
# 获取要测试的文件夹的绝对路径
sub = r"."
inpath = os.path.join(scriptfullpath, sub)
# 指明要搜索文件类型
filetypelist = [".txt", ".htm"]
# 在文件夹下查找所有符合文件类型要求的文件
files = get_files_with_special_ext_in_path(inpath, filetypelist)
# 逐个处理所有文件
for fn in files:
print("------------------------------------------------")
print("%s" % os.path.split(fn)[-1])
encoding = get_the_encoding_of_txt_file_chardet(fn)
encoding1 = get_the_encoding_of_txt_file_myself_guess_final(fn)
encoding2 = get_the_encoding_of_txt_file_myself_guess_final2(fn)
print("chardet猜的编码:%s" % encoding)
print("前函数猜的编码:%s" % encoding1)
print("本函数猜的编码:%s" % encoding2)
s = get_content_of_txt_file(fn)
if s:
try:
print(s)
except:
print("Python显示不了文件内容,转成它的十六进制Unicode编码:")
print(s.encode("utf-16-be").hex())
print("------------------------------------------------")
这里用到五个自定义函数:
1、get_files_with_special_ext_in_path(inpath, filetypelist)
功能是从一个文件夹及其子文件夹下查找指定类型的文件,返回文件列表
这个之前的短文里面给出过。
2、get_the_encoding_of_txt_file_chardet(fn)
功能是调用chardet扩展包判断一个文件文件的编码。
这个之前的短文里面给出过。
当然,chardet扩展包需要提前安装好。
3、get_the_encoding_of_txt_file_myself_guess_final(fn)
功能是自己写代码判断一个文件文件的编码。
这个在之前的短文里面给出过。
4、get_the_encoding_of_txt_file_myself_guess_final2(fn)
功能是自己写代码判断一个文件文件的编码,比上面的函数有所改进。
改进思路是在得到第一个判断成功的编码时不返回,而是继续考察其余的编码,所有判断成功的编码组成候选编码集合。如果候选编码集合的第一个编码不是"gbk",则返回第一个编码,否则进一步判断:分别将读取到的内容按不同的候选编码解码成Unicode字符串,哪个编码得到的字符串长度小,就选哪个编码。
5、get_content_of_txt_file(fn)
读取文本内容。读取之前要判断编码,判断编码的方法由上面的函数get_the_encoding_of_txt_file_myself_guess_final2(fn)完成。
读取内容的方法参见《Python如何读写不同编码格式的文本文件》。
运行这段代码,结果如下:
------------------------------------------------
一千.txt
chardet猜的编码:utf-8
前函数猜的编码:gb2312
本函数猜的编码:gb2312
读取文件尝试编码:gb2312
一千
------------------------------------------------
------------------------------------------------
米查gb18030.txt
chardet猜的编码:Windows-1252
前函数猜的编码:gb18030
本函数猜的编码:gb18030
读取文件尝试编码:gb18030
Python显示不了文件内容,转成它的十六进制Unicode编码:
d857ded7
------------------------------------------------
------------------------------------------------
米查unicode.txt
chardet猜的编码:UTF-16
前函数猜的编码:utf-16-le-sig
本函数猜的编码:utf-16-le-sig
读取文件尝试编码:utf-16
Python显示不了文件内容,转成它的十六进制Unicode编码:
d857ded7
------------------------------------------------
------------------------------------------------
米查unicodebigendian.txt
chardet猜的编码:UTF-16
前函数猜的编码:utf-16-be-sig
本函数猜的编码:utf-16-be-sig
读取文件尝试编码:utf-16
Python显示不了文件内容,转成它的十六进制Unicode编码:
d857ded7
------------------------------------------------
------------------------------------------------
米查unicodebigendian_nobom.txt
chardet猜的编码:ISO-8859-5
前函数猜的编码:gbk
本函数猜的编码:utf-16-be
读取文件尝试编码:utf-16-be
Python显示不了文件内容,转成它的十六进制Unicode编码:
d857ded7
------------------------------------------------
------------------------------------------------
米查unicode_nobom.txt
chardet猜的编码:ISO-8859-5
前函数猜的编码:utf-16-le
本函数猜的编码:utf-16-le
读取文件尝试编码:utf-16-le
Python显示不了文件内容,转成它的十六进制Unicode编码:
d857ded7
------------------------------------------------
------------------------------------------------
米查utf8.txt
chardet猜的编码:UTF-8-SIG
前函数猜的编码:utf-8-sig
本函数猜的编码:utf-8-sig
读取文件尝试编码:utf-8-sig
Python显示不了文件内容,转成它的十六进制Unicode编码:
d857ded7
------------------------------------------------
------------------------------------------------
米查utf8_nobom.txt
chardet猜的编码:Windows-1252
前函数猜的编码:gbk
本函数猜的编码:utf-8
读取文件尝试编码:utf-8
Python显示不了文件内容,转成它的十六进制Unicode编码:
d857ded7
------------------------------------------------
------------------------------------------------
系统.txt
chardet猜的编码:utf-8
前函数猜的编码:gb2312
本函数猜的编码:gb2312
读取文件尝试编码:gb2312
系统
------------------------------------------------
------------------------------------------------
联通.txt
chardet猜的编码:ISO-8859-1
前函数猜的编码:gb2312
本函数猜的编码:gb2312
读取文件尝试编码:gb2312
联通
------------------------------------------------
本程序对三种判断函数的判断结果进行了比较,用表格的形式总结如下:

我们发现,chardet的判断结果不太准确,自己编写的旧函数et_the_encoding_of_txt_file_myself_guess_final()判断错了两个,新函数et_the_encoding_of_txt_file_myself_guess_final2()判断的结果跟设定的完全一样。
五、对比
将本文的新函数的判断结果跟Windows的记事本、EditPlus和EmEditor做一下对比,判断对象是本文生成的10个文本文件。这三个软件如果判断错误,打开文本文件的时候就会显示不正确的内容。
软件版本如下:
记事本是Win 7中文专业版 32位操作系统自带的记事本软件。
EditPlus的版本是EditPlus Text Editor v3.80(805) 32bit。
EmEditor的版本是EmEditor Professional (32-bit) Version 16.1.4。
用三个软件分别打开十个文本文件,显示错误即为编码识别错误。具体的编码识别结果如下:
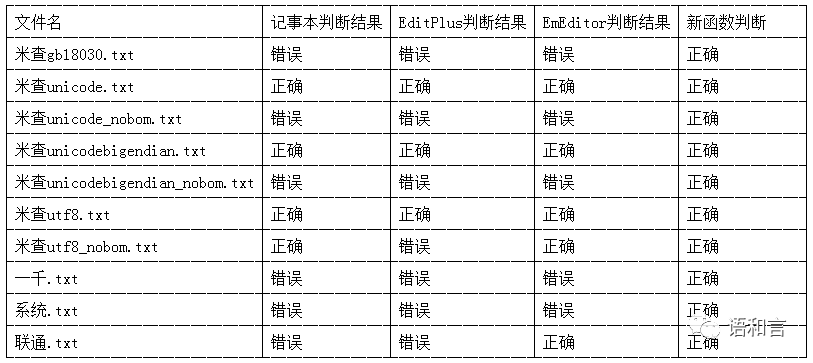
小结一下三个软件的文本编码识别正确率:

1、“米查gb18030.txt”被三个软件全部识别错误,说明这些软件对国家标准GB18030的支持力度不够好。
2、“一千.txt”和“系统.txt”被三个系统全部识别错误,“联通.txt”被两个软件识别错误,说明这些软件在判断普通的短文本的编码方面是有缺陷的。
3、没有BOM的Unicode文本和Unicode big endian文本被三个系统全部识别错误,说明Unicode编码的文本有BOM是多么重要。
4、没有BOM的UTF-8文本被EditPlus识别错误,这有点不应该,说明它还不认识四字节的汉字,归根结底是对国家标准GB18030的支持力度不够好。
六、讨论
这次新函数解决了旧函数判断不了的两个没有BOM的Unicode文本的判定问题,而且只用了一个汉字作为例子,是不是有作弊的嫌疑?对其它文本的的测试效果如何,这里也没时间测试了,以后万一碰到问题,再修改函数吧。
心里隐隐约约对使用统计语言模型判断文本编码有些小期待呢。
七、引申
突然发现,光顾了搞Python测试,居然忽略了C语言的优雅表示,这直接导致本文的C语言程序非常臃肿,居然用了78行代码,实在是是可忍孰不可忍,想到一个大幅精简代码的方法,代码行数可以减少一半以上。以后有时间再说。
