




Python如何读写不同编码格式的文本文件
一、引入
我们用Python处理工作免不了要读写一些文本文件。文本文件的编码,按Windows记事本的编码分类体系,可分为四类:
ANSI
Unicode
Unicode big endian
UTF-8
下面说一下四种类型的文本文件的读写方法。
二、准备
在中文Windows系统中,打开Windows的记事本,选择新建,写上“中国”这俩汉字,分别按四种编码保存为文本文件:
(1)ANSI编码,保存为“中国_ansi.txt”;
(2)Unicode编码,保存为“中国_Unicode.txt”;
(3)Unicode big endian编码,保存为“中国_UnicodeBigEndian.txt”;
(4)UTF-8编码,保存为“中国_utf-8.txt”。
上述四个文件的编码格式、字节数和十六进制内容如下所示。
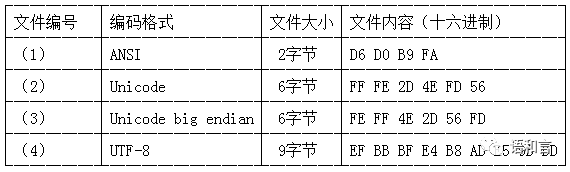
在文件(2)中,开头的“FF FE”是Unicode格式的文件的BOM(Byte Order Mark),BOM通常出现在文件开头,标识字节序(Big Endian还是Little Endian)。“FF FE”表明这是一个以Unicode little endian编码格式保存的文本文件,剩下的四个字节“2D 4E FD 56”是文件的内容。Windows记事本所谓的“Unicode”编码格式,指的是“Unicode little endian”编码格式。
在文件(3)中,开头的“FE FF”是Unicode big endian格式的文件的字节序,表明这是一个以Unicode big endian编码格式保存的文本文件,剩下的四个字节“4E 2D 56 FD”是文件的内容。
在文件(4)中,开头的“EF BB BF”是UTF-8格式的文件的字节序,表明这是一个以UTF-8编码格式保存的文本文件,剩下的六个字节“E4 B8 AD E5 9B BD”是文件的内容。有一些UTF-8编码的文件开头没有字节序,开头直接就是文件内容,但Windows的记事本保存的UTF-8文件开头是有这个字节序的。
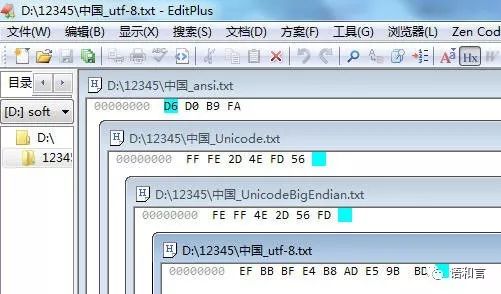
十六进制内容可以这样查看:将它们同时用EditPlus打开,切换到十六进制显示模式,适当调整显示窗口大小和位置,可看到四种类型编码的文本对应的十六进制内容如下:
三、读取文件
不管电脑上的文本文件以何种编码格式存放,Python读取文本文件的内容之后,在内存当中都会得到字符串,Python 3.x的字符串是以Unicode编码存放的。Python读取文件的常用格式如下:
fp = open(fn, "rt", encoding = "***")
s = fp.read()
fp.close()
或者
with open(fn, "rt", encoding = "***") as fp:
s = fp.read()
两段代码功能一样,只不过后者省去了关闭文件的步骤。读取文件还有其他参数,一般也用不到,这里略过。
上述代码里面的fn是存放文件名的变量,代码以指定编码格式读取完文件之后,将读取的内容赋值给变量s。
当然,如果编码格式指定有误的话,可能会导致文件读取失败。为此我们需要首先判断文本文件的编码,之前我们在《用Python判断文本文件的编码方式》里探讨过文本文件编码方式的判定方法,当然,判定编码不一定正确,读取时还有可能出错,我们又探讨了《ython读取文本文件时ansi编码的妙用》,后来又继续对文本文件编码判定方法加以改进《用Python判断文本文件的编码方式(二)》。关于格式判定不再多说。本文在读取文本文件时假定我们已经知道了四个文本的正确编码格式。
下面分别看一下四类格式文本的读取,假设这四个文件都保存在d:\12345目录下。
1、读取ANSI格式的文本文件示例代码
>>> fn = r"d:\12345\中国_ansi.txt"
>>> with open(fn) as fp:
s = fp.read()
>>> s
'中国'
>>> s.encode("gbk")
b'\xd6\xd0\xb9\xfa'
从这里我们能看到“中国”的十六进制GBK编码“d6 d0 b9 fa”,跟我们用文本编辑软件EditPlus看到的是一样的。
因为open()函数的读取方式默认是"rt",所以该参数可以省略,又因为在中文Windows操作系统下,Python3的open()函数的encoding参数默认值是"gbk",而咱们用Windows的记事本保存文件的默认编码格式"ANSI"跟Python里面的"GBK"是一致的,所以这个encoding参数也可以省略。GBK编码是兼容ANSI编码的,GBK编码又被GB18030编码所兼容,这些编码之间的关系可以参考《GB18030字符收录情况介绍》。
2、读取Unicode格式的文本文件示例代码
>>> fn = r"d:\12345\中国_Unicode.txt"
>>> with open(fn, encoding = "utf-16") as fp:
s = fp.read()
>>> s
'中国'
注意:读取Unicode编码的文件,参数要写成
encoding = "utf-16"
而不能写成
encoding = "unicode"
因为Unicode是俗称,正式的名字是“UTF-16”。
3、读取Unicode big endian格式的文本文件示例代码
>>> fn = r"d:\12345\中国_UnicodeBigEndian.txt"
>>> with open(fn, encoding = "utf-16-be") as fp:
s = fp.read()
>>> s
'\ufeff中国'
注意,这里的读取结果就不对了,文件开头的两个字节“FE FF”只是用来标明字节序的,并不是文件内容的一部分。这里的读取结果却把它读取成文件内容的一部分了。换个读取方法试试。
>>> fn = r"d:\12345\中国_UnicodeBigEndian.txt"
>>> with open(fn, encoding = "utf-16") as fp:
s = fp.read()
>>> s
'中国'
这一次就对了。
原因分析:
(1)对于UTF-16编码格式的带BOM文件,不管是Unicode编码格式还是Unicode big endian编码格式, 如果将打开文件的参数encoding设置为"utf-16",那么,Python读取时总会将BOM解码为空字串,读取的内容没有多余的字符,就正确了。如果指定更细的分类,比如"utf-16-le"、"utf-16-be",Python会忽略BOM,会将BOM解读为一个特定的字符'\ufeff'。
(2)据说,还有一些Unicode和Unicode big endian编码的文件开头没有字节序标志,对于这类不带BOM的UTF-16编码格式文件,读取文件时需要将参数encoding设置为"utf-16-le"、"utf-16-be",这样Python就不检查BOM直接读取内容。但是,如果指定了笼统的编码格式"utf-16",程序的运行就会报错。
4、读取UTF-8格式的文本文件示例代码
>>> fn = r"d:\12345\中国_utf-8.txt"
>>> with open(fn, encoding ="utf-8") as fp:
s = fp.read()
>>> s
'\ufeff中国'
这里的读取结果有些不太对,Python将UTF-8编码格式的文本文件的BOM解读成了字符'\ufeff'。
怎么样才能正确读取呢?原来,UTF-8文件的编码是需要细分的。分成"utf-8"和"utf-8-sig",前者是无BOM的UTF-8文件的编码方式,后者是有BOM的UTF-8文件的编码方式。我们这个显然是有BOM的,所以换个方式读取一下:
>>> fn = r"d:\12345\中国_utf-8.txt"
>>> with open(fn, encoding ="utf-8-sig") as fp:
s = fp.read()
>>> s
'中国'
这就对了,一切OK。如果真的碰上无BOM的文件,就得用参数encoding ="utf-8"来读取。
四、写入
1、写入ANSI编码的文本文件
>>> fn = r"d:\中国_ansi.txt"
>>> open(fn, "wt").write("中国")
2
查看生成的文件d:\中国_ansi.txt,发现其内容的十六进制结果跟d:\12345目录下的同名文件一样。
2、写入Unicode编码的文本文件
>>> fn = r"d:\中国_unicode.txt"
>>> open(fn, "wt", encoding = "utf-16").write("中国")
2
查看生成的文件d:\中国_unicode.txt,发现其内容的十六进制结果跟d:\12345目录下的同名文件一样。
注意,Python生成UTF-16编码格式的文本文件,直接生成了Unicode little endian格式的文件。
3、写入Unicode big endian编码的文本文件
>>> fn = r"d:\中国_unicodebigendian.txt"
>>> with open(fn, "wt", encoding = "utf-16-be") as fp:
fp.write("\ufeff")
fp.write("中国")
1
2
查看生成的文件d:\中国_unicodebigendian.txt,发现其内容的十六进制结果跟d:\12345目录下的同名文件一样。
注意,要想让Python生成Unicode big endian编码格式的文本文件,指定了参数encoding = "utf-16-be"之后,直接输出"中国"的话只能生成无BOM的Unicode big endian编码格式的文本文件,为了生成BOM,只好用fp.write("\ufeff")来达到目的。
另外,指定参数encoding = "utf-16-le"也一样,生成的Unicode little endian格式的文件也没有BOM。
总结规律,生成Unicode格式的文件时,直接使用参数encoding = "utf-16"可以生成带BOM的Unicode big endian编码格式的文本文件;如果使用细分的参数,无论是"utf-16-be"还是"utf-16-le",得到的相应编码格式的文本文件均没有BOM,要想生带BOM的文件,需要在输出内容之前将字符'\ufeff'输出到文件。
4、写入UTF-8编码的文本文件(有BOM)
>>> fn = r"d:\中国_utf-8.txt"
>>> open(fn, "wt", encoding = "utf-8-sig").write('中国')
2
查看生成的文件d:\中国_utf-8.txt,发现其内容的十六进制结果跟d:\12345目录下的同名文件一样。
如果要生成无BOM的UTF-8编码的文本文件,用参数encoding = "utf-8"即可。
附录:big endian和little endian
通常,一个基本多语言平面内的Unicode字符用两个字节表示一个字符。两个字节分为高字节和低字节。我们说的时候,显然是先说高字节再说,低字节。但是在内存中存储的时候的时候,有一个先存高字节还是先存低字节的问题。
如果低字节所在的内存单元地址比高字节所在的内存单元地址大,则称为“big endian”,俗称“大端”。因为从高字节往低字节看过去,单元地址号是逐渐变大的。
如果低字节所在的内存单元地址比高字节所在的内存单元地址小,则称为“little endian”,俗称“小端”。因为从高字节往低字节看过去,单元地址号是逐渐变小的。
“大端”和“小端”,也有说成“大尾”和“小尾”的,也有说成“大头”和“小头”的。
在Unicode编码的文本文件中,大端的存储格式高字节在前,低字节在后,从高字节往低字节看过去,相对文件开头的地址偏移量是逐渐变大的。
所以,在big endian的Unicode文本文件中,字符的高低字节排列顺序序跟在内存中得到的十六进制编码的高低字节顺序是一致的。例如:“中国”俩字的十六进制Unicode编码组合是“4e 2d 56 fd”,在big endian的Unicode文本文件“中国_UnicodeBigEndian.txt”中用十六进制查看,也是这个顺序。
参考资料
https://blog.csdn.net/m0_37890477/article/details/80278527,《python读取文件BOM字符处理》
https://blog.csdn.net/pkrobbie/article/details/1451437,《Python读写Unicode文件》
