




一、任务
给定一篇英文文本,要求统计其中的ASCII字符(半角字符)的出现频次,按频次降序和字符升序输出。主要是练习Python代码,同时拿出C语言代码作为对比,算是陪太子读书吧。
二、思路与比较
C语言代码用散列表统计,Python用内置字典和collections模块的defaultdict类和Counter类。排序都采用各自语言的现成函数。C语言程序写了1个,Python程序共写了三个。程序没有可以压缩空行,在保持可读性的前提下,对比一下四个程序的行数及特点。
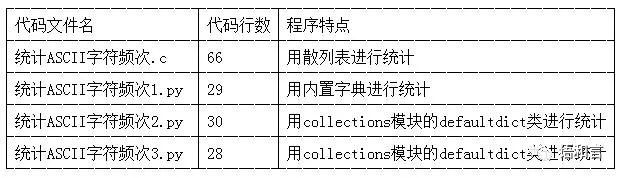
从代码行数上看,Python代码比C语言代码简洁很多。
C语言的qsort函数对初学者来说掌握起来有些难度,如果C语言代码不用系统函数qsort,自己写排序函数的话,代码还要增加很多行。
上述所有四个程序,都将ASCII值小于32的字符忽略不计,因为它们是控制字符,不可显示。下面贴出C语言代码留作纪念,贴出Python代码备查。
三、C语言代码
/* 统计ASCII字符频次.c */
#include <stdio.h>
#include <ctype.h>
/* 自定义结构体,存放字符及其频次 */
typedef struct
{
char ch;
int freq;
} CHARFREQ;
/* 被qsort调用的排序函数,先频次降序,再字符升序 */
int mycmp(const void *p1, const void *p2)
{
if ( ((CHARFREQ *)p1)->freq != ((CHARFREQ *)p2)->freq )
return ((CHARFREQ *)p2)->freq - ((CHARFREQ *)p1)->freq;
else
return (((CHARFREQ *)p1)->ch - ((CHARFREQ *)p2)->ch);
}
int main(int argc, char *argv[])
{
int len;
char ch;
int i;
CHARFREQ x[128];
FILE * fp;
char *fn = "en.txt";
* 初始化 */
for (i=0; i<128; i++)
{
x[i].ch = i;
x[i].freq = 0;
}
* 打开文件 */
if (!(fp=fopen(fn, "rt")))
{
printf("不能打开文件 %s ,程序将退出。", fn);
getch();
return -1;
}
* 统计 */
while((ch=fgetc(fp))!=EOF)
{
if (ch>0)
x[ch].freq++;
}
* 关闭文件 */
fclose(fp);
* 排序,调用C语言自带的qsort函数 */
qsort(x, 128, sizeof(CHARFREQ), mycmp);
* 输出 */
for (i=0; i<128; i++)
{
if (x[i].ch>31 && x[i].freq)
printf("%c\t%d\n", x[i].ch, x[i].freq);
}
return 0;
}
四、Python代码
1、统计ASCII字符频次1.py
代码主要的关键点有两个:
d.get(ch, 0)这个函数超赞,若ch是字典d的键,则返回其值,否则返回0。
内置函数sorted()返回排序后的可迭代对象,并不影响原字典。
sorted排序默认是升序排列,可以用reverse=True参数来降序排列。
排序的关键字默认是一个,如果需要多个关键字顺次进行排序, 则需要用lanbda表达式构造一个元组出来,构造出来的元组的第一关键字优先,其它关键字优先级依次降低。

2、统计ASCII字符频次2.py
这个没什么好说的,除了个别语句,代码基本上跟 统计ASCII字符频次1.py 一样。

3、统计ASCII字符频次3.py
这段代码使用了collections模块的Counter类,该类可以很方便地统计字符频次,它的函数most_common(n)可以提取频次最高的前n个字符,如果是most_common(len(c)),那就是按频次从高到低排序了。但它只能按频次从高到低排序,对于频次相同的字符,并不能按一定的规则排序。所以我们还得用跟前两个程序一样的字典排序方法进行两关键字排序。

五、测试
1、准备文本文件en.txt
这个文件就是Python的IDLE命令行下import this命令出来的结果,据说叫“Python之禅”,全文如下:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
2、测试结果
以上四个程序,输出到屏幕的内容完全一致,结果如下(第1名频次124的看不见字符是空格):
124
e 90
t 76
a 50
i 50
o 43
s 43
n 40
l 33
r 32
h 31
b 20
p 20
u 20
. 18
y 17
c 16
d 16
m 16
f 11
g 11
- 6
x 6
v 5
' 4
, 4
w 4
A 3
I 3
S 3
T 3
* 2
E 2
N 2
P 2
k 2
! 1
B 1
C 1
D 1
F 1
R 1
U 1
Z 1
