




一、任务
前段时间在自动批改C语言作业的时候,用了函数get_the_encoding_of_txt_file_chardet来判断C语言的编码方式,以便决定用UTF-8编码来编译还是用GBK编码来编译。
那个任务告一段落之后,回测函数get_the_encoding_of_txt_file_chardet,发现有不少文件的编码方式判断有误。究其原因,是直接采用了chardet扩展包的返回值,可见,chardet扩展包判断文本文件编码的功能是不太好用的。
今天重新整理思路,写一个能正确判断文本文件编码的函数。
二、环境
Win7 中文版,专业版,32位 + Python3.64
三、编码方式界定
打开Windows的记事本,使用另存为菜单,我们发现“编码”的下拉列表框里有四种选项:
ANSI
Unicode
Unicode big endian
UTF8
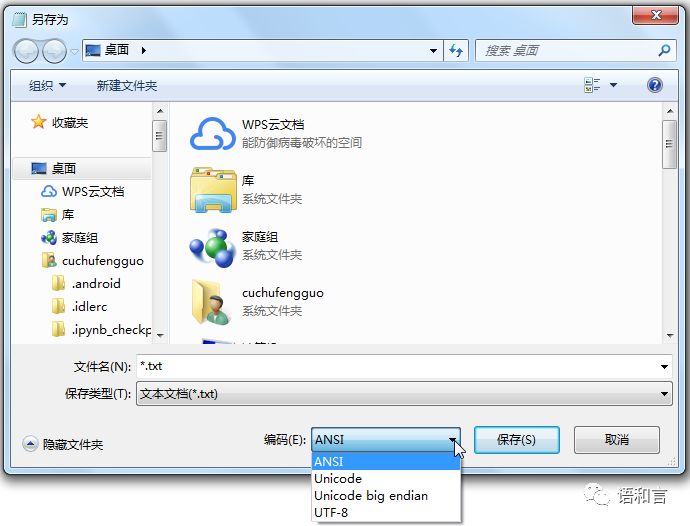
其中ANSI是ASCII编码系列,在中文Windows操作系统中,咱们中文的GB18030字符集、GBK字符集、GB2312字符集中的字符跟老美的ASCII码字符集都是兼容的,它们属于同一个系列,在这种系列下,字符在文件中存的代码跟它在字符集中的编码是一致的。咱们用记事本保存文件的时候默认的就是ANSI编码。由于国标GB18030目前还不如GBK用得广泛,而且GBK跟GB2312和ASCII都是兼容的,所以我们以“GBK”编码作为Windows记事本的“ANSI”系列编码的统一称谓。
另外,UTF-8编码分为无BOM的UTF-8编码和有BOM的UTF-8编码,我们的文本编码判定函数也将对此进行区分。函数的返回值分如下几种类型,它们的含义列表如下:
┌─────┬────────────┬─────────────┐
│返回值 │含义 │对应的Windows记事本的编码 │
├─────┼────────────┼─────────────┤
│"" │空字符串,表示文件不存在│ │
├─────┼────────────┼─────────────┤
│gbk │GBK编码 │ANSI │
├─────┼────────────┼─────────────┤
│utf-8 │UTF-8编码 │UTF-8 │
├─────┼────────────┼─────────────┤
│utf-8-sig │UTF8+BOM │ │
├─────┼────────────┼─────────────┤
│utf-16 │Unicode │Unicode │
├─────┼────────────┼─────────────┤
│utf-16-be │Unicode big endian │ │
├─────┼────────────┼─────────────┤
│unknown │未知编码 │ │
└─────┴────────────┴─────────────┘
四、代码
今日的主角——函数get_the_encoding_of_txt_file_myself_guess()的定义如下:

另外两个辅助函数在用Python自动批改C语言作业(三)当中已经给出过,这里不再浪费版面。
除了三个被调用的函数外,Python脚本的全部代码如下:

五、测试
准备了几个C程序文件和文本文件,还有一个编译出来的exe文件。除了exe文件之外,这些文件的的编码方式都在文件名上面体现出来。用上面给出的Python脚本进行测试,结果如下:
调用chardet扩展包判断结果:
D:\ftp\判断文本编码\test\a.exe:Windows-1254
D:\ftp\判断文本编码\test\test0-ansi.c:GB2312
D:\ftp\判断文本编码\test\test0-utf-16-be.c:UTF-16
D:\ftp\判断文本编码\test\test0-utf-16.c:UTF-16
D:\ftp\判断文本编码\test\test0-utf8.c:utf-8
D:\ftp\判断文本编码\test\test1-ansi.c:ISO-8859-9
D:\ftp\判断文本编码\test\test2-utf8.c:utf-8
D:\ftp\判断文本编码\test\test3-ansi.c:ISO-8859-1
D:\ftp\判断文本编码\test\盘古-ansi.txt:KOI8-R
D:\ftp\判断文本编码\test\联通-ansi.txt:ISO-8859-1
D:\ftp\判断文本编码\test\联通-unicode.txt:UTF-16
D:\ftp\判断文本编码\test\联通-unicodebigendian.txt:UTF-16
D:\ftp\判断文本编码\test\联通-utf8+bom.txt:UTF-8-SIG
D:\ftp\判断文本编码\test\联通-utf8.txt:utf-8
调用自定义扩展包判断结果:
D:\ftp\判断文本编码\test\a.exe:unknown
D:\ftp\判断文本编码\test\test0-ansi.c:gbk
D:\ftp\判断文本编码\test\test0-utf-16-be.c:utf-16-be
D:\ftp\判断文本编码\test\test0-utf-16.c:utf-16
D:\ftp\判断文本编码\test\test0-utf8.c:utf-8
D:\ftp\判断文本编码\test\test1-ansi.c:gbk
D:\ftp\判断文本编码\test\test2-utf8.c:utf-8
D:\ftp\判断文本编码\test\test3-ansi.c:gbk
D:\ftp\判断文本编码\test\盘古-ansi.txt:gbk
D:\ftp\判断文本编码\test\联通-ansi.txt:gbk
D:\ftp\判断文本编码\test\联通-unicode.txt:utf-16
D:\ftp\判断文本编码\test\联通-unicodebigendian.txt:utf-16-be
D:\ftp\判断文本编码\test\联通-utf8+bom.txt:utf-8-sig
D:\ftp\判断文本编码\test\联通-utf8.txt:utf-8
可见,自定义函数比使用chaedet扩展包的函数的判别效果要好上很多。
六、讨论
自定义函数get_the_encoding_of_txt_file_myself_guess()太冗长,可以化简,大幅减少代码量。暂时懒得改了,先解决革命工作能不能干的问题,以后再考虑多快好省建设社会主义。
