




了解了innodb的底层存储格式后,我们再来了解下其索引的构建与查询算法,以及索引相关的特性。
索引结构
B+树
前面我们了解到,在页内,可以通过页目录,二分法快速的查询到一条数据,那么有很多页的时候,该如何快速定位到某个页呢?这就涉及到了innodb的索引。
innodb采用的是b+树的索引结构,通过索引页+记录页的方式,记录页为双向链表相连。
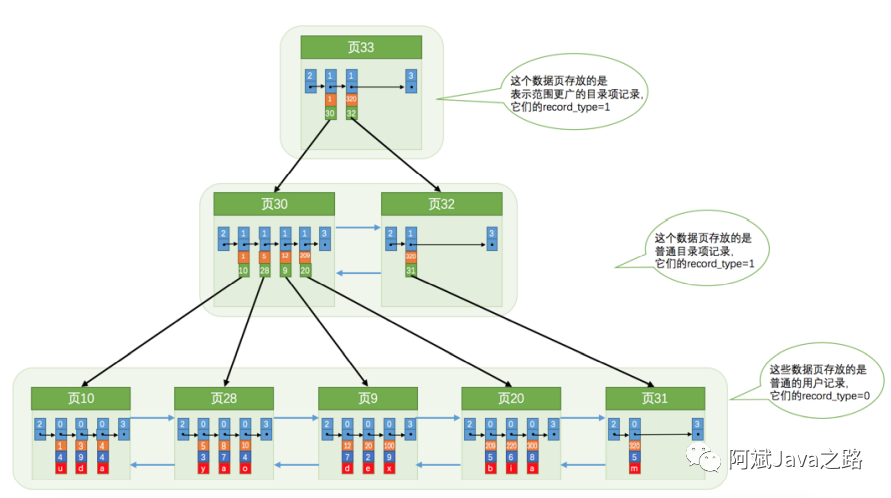
查找的时候先从根节点确认页的位置,不断向下查询,定位到具体的记录页,再通过页中的页目录,来查询到想要的数据。
为什么采用B+树?
对比hash:hash不支持范围查询
对比二叉树:二叉树有可能退化成单向链表,b+树能自平衡
对比b树:b树非叶子节点也能存放数据,会导致每条记录的查询复杂度不一致,且非叶子节点放了数据,就会导致相同高度的层级,存放的总数据少了,造成更好的树深度。
索引的种类
innodb的索引主要分为聚簇索引(clustered inex )和辅助索引(sencondary index)。也称为主键索引和二级索引。
聚簇索引
聚簇索引叶子节点存放的是具体的记录行。
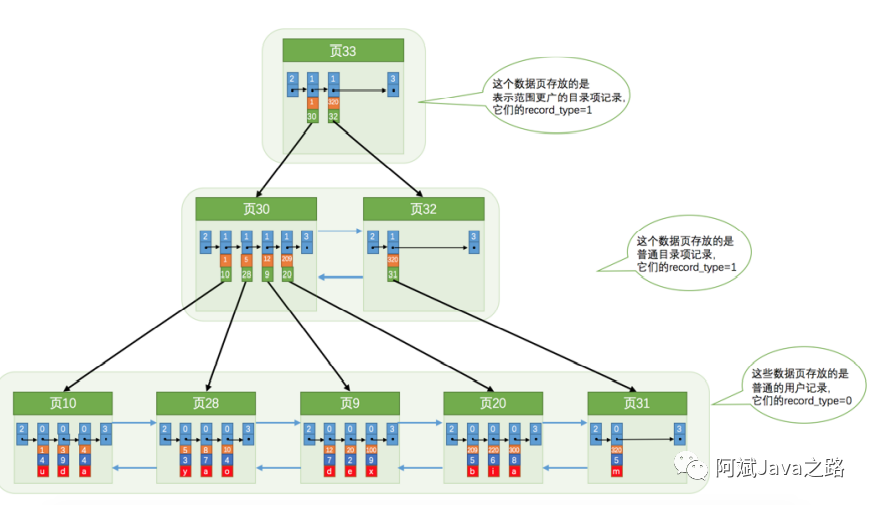
辅助索引
辅助索引叶子节点存放的是聚簇索引的索引键。
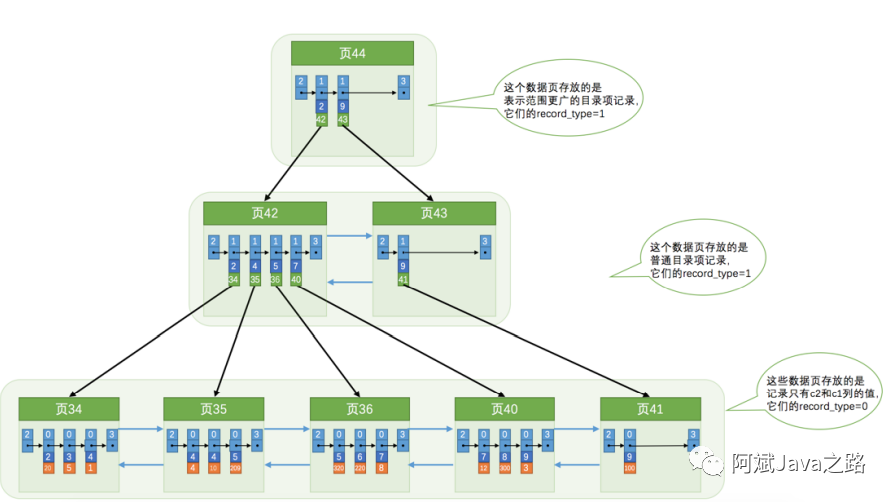
所以辅助索引的空间占用一般比较小。
联合索引
两个字段一起组成联合索引,这样我们会先去匹配第一个索引列,在第一个索引列相同的情况下去匹配第二个索引列。
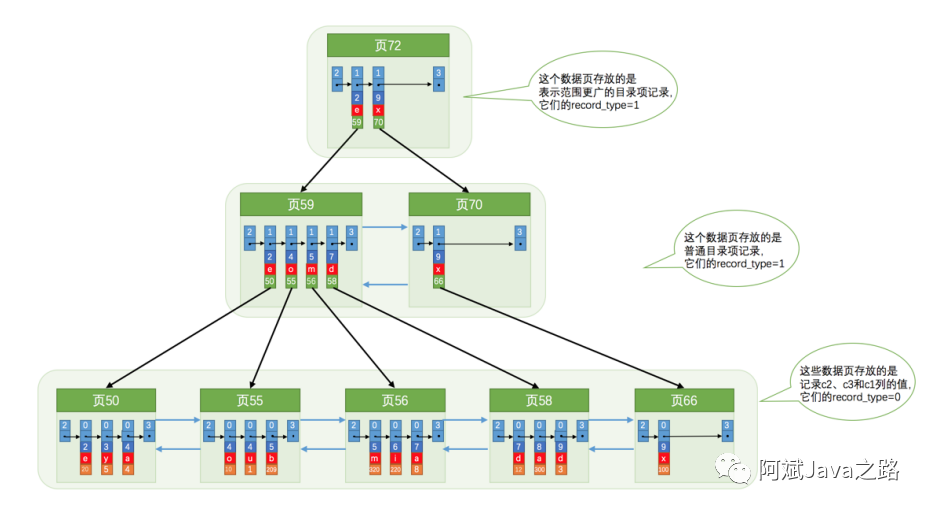
特性
由于innodb的索引结构,带来了一系列耳熟能详的索引特性,接下来我们就一起看看有哪些。
回表查询
select * from T where c1=5;
像这样一条语句,二级索引c1只存了聚簇索引的索引键的值,如果我们是根据二级索引查到的数据,还需要拿着聚簇索引的索引键到聚簇索引中去查到对应的真实数据,称为回表查询。
覆盖索引
回表是有代价的,为了避免回表的代价。我们需要指定我们想要查询的列,就有机会达到覆盖索引。
select id,c1 from T where c1=5;
像这样一条查询语句,我们想要的主键id和二级索引c1在二级索引中都覆盖到了,就不需要去回表了,就称为覆盖索引,有效的解决了回表的问题。
索引查询原理
主键索引:id
二级索引:c1,c2
普通字段commmon
#插入语句
insert into t(id,c1,c2,common) values (1,1,1,'小红');
insert into t(id,c1,c2,common) values (2,1,2,'小名');
insert into t(id,c1,c2,common) values (3,2,1,'小黑');
insert into t(id,c1,c2,common) values (4,2,2,'小花');
#执行语句
select * from t where c1=1 and c2=1;
假设执行上面的语句,会出现什么样的结果?
c1和c2都是索引列的情况下,优化器只会选中其中一个作为查询条件,比如在二级索引通过c1=1过滤出两条数据的主键1和2,然后再回表查出这这两行记录,最后在server层中过滤掉c2=1的记录。也就是,这个过程涉及到了回表,同时还设计到了内存过滤。有没有可能这些都在二级索引中就解决呢?当然有。
在大部分情况下,mysql只会使用一个索引列,除了某些场景,优化器认为同时使用两个索引列的代价更低,就把c1=1和c2=1的数据全部查出来,然后在内存中做交集的运算。
最左匹配原则
要善于运用组合索引,组合索引更容易达到索引覆盖的效果,并且在合适的时候更容易命中索引。比如上面提到的查询。
主键索引:id
联合索引:(c1,c2)
普通字段commmon
#插入语句
insert into t(id,c1,c2,common) values (1,1,1,'小红');
insert into t(id,c1,c2,common) values (2,1,2,'小名');
insert into t(id,c1,c2,common) values (3,2,1,'小黑');
insert into t(id,c1,c2,common) values (4,2,2,'小花');
#执行语句
select * from t where c1=1 and c2=1;
由于组合索引中同时有c1也有c2,就可以在二级索引中完全过滤出想要的数据了,避免了内存的过滤。使用联合索引要注意一个最左匹配原则
联合索引:(c1,c2)
select * from t where c1=1 and c2=1;#走
select * from t where c1=1 and c2>1;#走
select * from t where c1>1 and c2>1;#不走索引
select * from t where c1>1 ;#走
select * from t where c2=1;#不走索引
#模糊匹配
select * from t where c1 like 'ab%';#走
select * from t where c1 like '%ab%';#不走
#排序
select * from t order by c1,c2;#走
select * from t order by c2,c1;#不走
注意以上的例子,大概就能明白最左前缀原则了,实际上明白了b+树的查询原理,也能很好的明白最左前缀原则。
索引下推
索引下推(ICP index condition pushdown)是索引下推是 MySQL 5.6 及以上版本上推出的,用于对查询进行优化。
索引下推是把本应该在 server 层进行筛选的条件,下推到存储引擎层来进行筛选判断,这样能有效减少回表。
比如刚刚的索引结构
联合索引:(c1,c2)
select * from t where c1>1 and c2=1;
如果没有索引下推,只会走c1的索引,筛选出两条数据,然后在server层对c2字段过滤。
有了索引下推,在二级索引中,引擎发现有c2字段的值,就会直接对c2字段做一个过滤,避免无效的会标和server过滤操作了。

END
后台回复关键词 mysql 获取今日推荐资料
微信8.0新增了一万的好友数,之前没加上好友的可以加一下我的个人微信,再晚又满了,一起抱团取暖,结伴内卷。

扫码拉群,学习打卡,交流经验
每周一读
