




作者:镜舟科技CEO 孙文现(本文为作者在StarRocks Summit Asia 2022的分享)
非常荣幸能借着峰会的契机跟大家做分享和交流。在我至今的职业生涯里,创立过两家公司,一个做 IoT PaaS,另一个做 OLAP 数仓。两个都是比较难啃的骨头,解决的都是企业数字化转型最后一公里的难题。
大家都知道物流的最后一公里是什么。那么数据分析的最后一公里是什么呢?回归到本质,就是让客户可以随时随地、随心所欲地使用数据,不用再担心数据源不统一、维度多了速度慢、一线分析师无法做复杂查询、各种数据、相关产品之间不能兼容等问题。
镜舟是一家商业化公司,是做整个 OLAP 数仓技术兜底的。我们在过去建设了生态、各种技术产品栈等,就是要把最后一公里的难题给解决掉。我今天的分享主题主要分为三个方面:
第三,借助以客户为中心的标准化服务模式,实现与客户产品共创的客户成功。
#01
随着 5G、云计算、大数据、 AI 等技术的发展,全球数据量呈现爆发式增长:
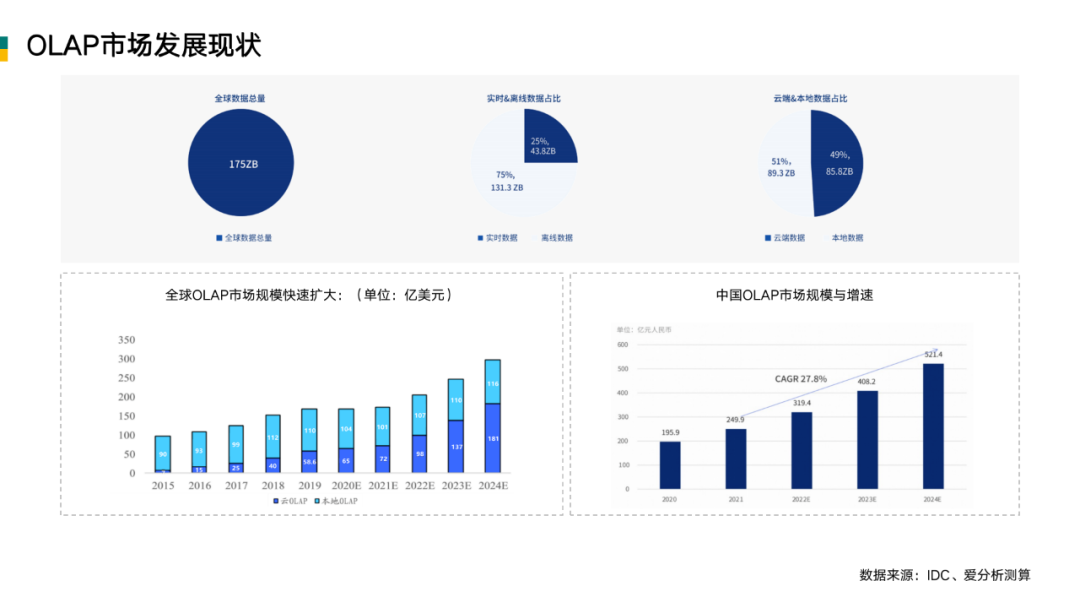
到 2025 年,全球的数据量能达到 175ZB(Zettabyte),其中近 30% 的数据需要被实时处理。2019 年到 2025 年,CAGR(平均年复合增长率)都达到了近 30%。
据 IDC 统计和预测, 2024 年全球数仓的市场规模将达到 297 亿美元,2019-2024 年的年复合增长率将达到 12%,其中云上的数仓市场规模将达到 181 亿美元,2019-2024 年的 CAGR 将达到 25.3%。预计 2024 年,中国数仓市场的规模是 168.5 亿元,中国大数据平台软件市场规模总体为 352.9 亿元,中国分析型数据库的整体市场将达到 521.4 亿元,复合增长率为 27.7%。
分析型数仓包括数据仓库、数据湖以及智能湖仓,因此分析型数据库的市场规模也是这三者之和,这是 IDC 的定义,我认为有一定道理。OLAP 数仓的适应面和适应度是最广的,所以把三者加起来等于这个市场规模之和是有一定道理的。
根据 IDC 的数据,2021年中国数仓数据库的规模是 87.1 亿人民币,大数据平台的是 162.8 亿人民币。因此我们认为 2021 年中国分析型数据库的市场规模为 250 亿左右。
数仓的技术架构演进经历了一些过程,这些过程的产生不仅是历史的原因,现在各个企业也在同时经历整个过程,他们或多或少处在某一个阶段,而每个阶段都有一些痛点需要去解决。
第一个阶段,就是传统的离线架构。第一代是以 Apache Hive(以下简称 Hive)、MapReduce、HDFS 为代表的纯离线数仓。这个阶段下,很多公司刚开始搭自己的大数据技术,数据体量和数据规模都不是特别大,通常在 TB 级,维度也不是很多。业务团队的需求通常是 T+1 型的固定报表任务,它的架构痛点非常明显,就是离线大数据架构不能处理实时业务,固定报表反馈出的数据价值是很低的。
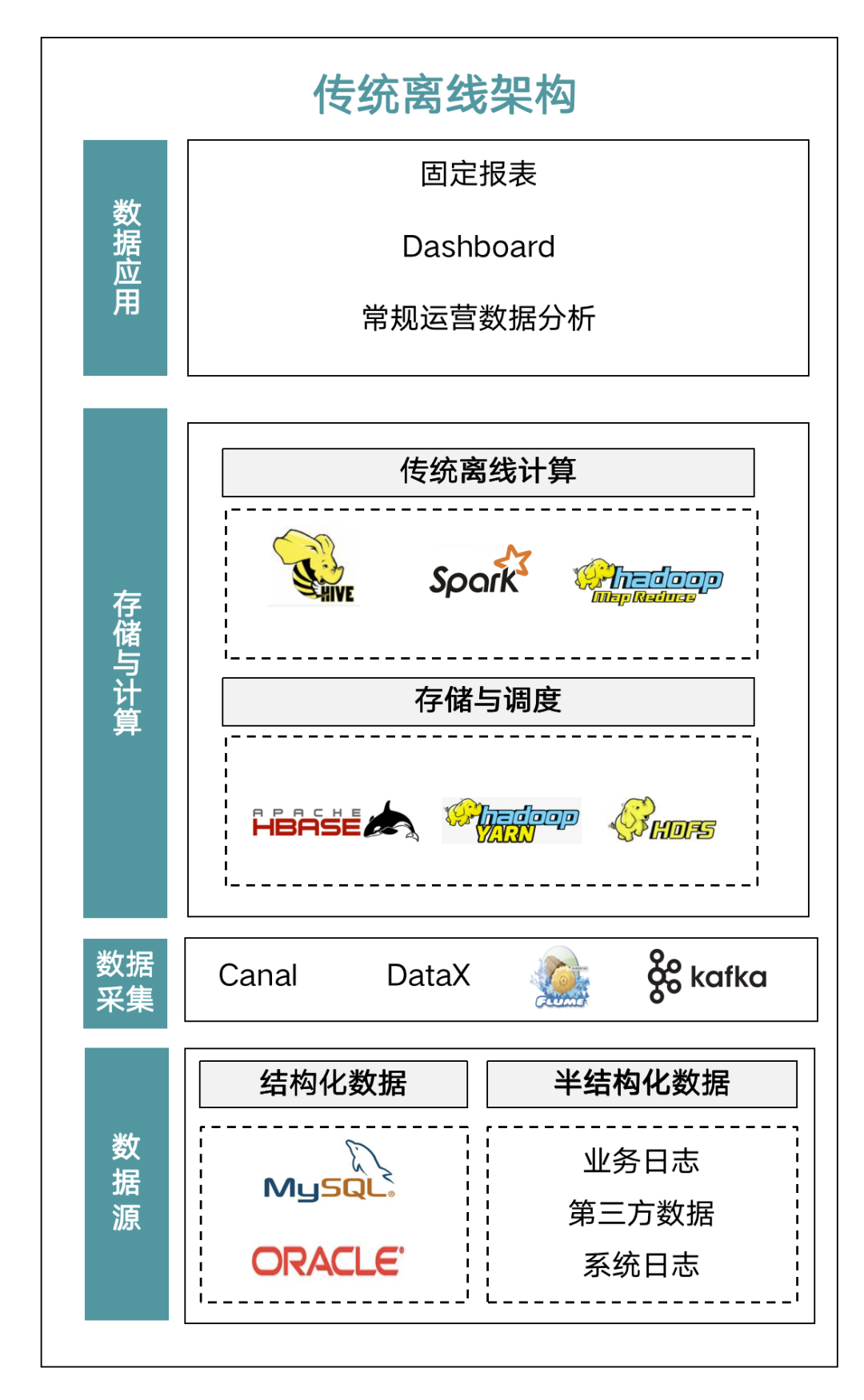
第二阶段,从传统离线架构到 Lambda 架构的演进。这个阶段特征是随着业务和企业数据体量的快速发展,从 TB 级到 PB 级,企业内部对于数仓提出了实时分析的要求,且维度也变得更加多元化和复杂化。传统离线 T+1 的架构已无法满足业务需求了。
Lambda 架构是在原来的离线数仓基础上增加了一个实时计算链路。在业务数据采集后分成两条线进行计算:一条是走“流”,做指标分析,实时的;一条是走“批量”,做离线的 T+1 的业务指标,是近几年比较广泛应用的架构。
但是 Lambda 架构有比较明显的缺点,一个是在业务开发过程中都是相对独立的烟囱式开发设计,在各业务间的数据规范统一、处理数据流程统一和数据复用等方面都做得不理想。Lambda 架构最大的问题是针对同一个需求要开发两套代码,同时去跑“批”和跑“流”,写好代码之后还需要构造数据测试,保证两者结果一致。两套代码对后期的维护也非常麻烦。一旦需求变更,两套代码都需要修改,两套代码也需要同时上线,运维成本很高。同样的逻辑需要计算两次,整体占用资源会增多。由于“批”、“流”两个过程都需要将数据存储在集群中,并且过程中会产生大量临时数据,就会导致数据急速膨胀,加大服务器存储的压力。
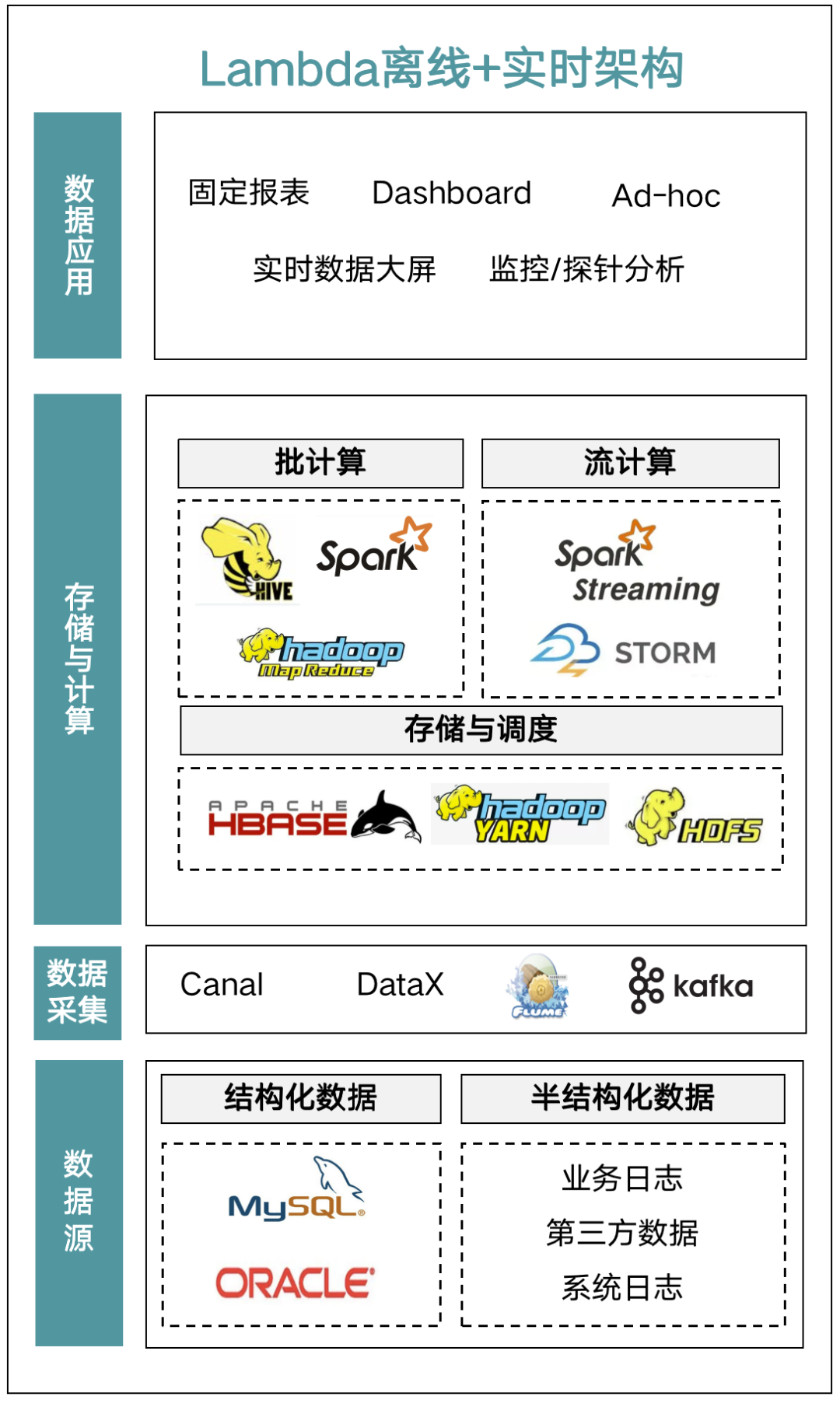
后来就衍生出了 Kappa 架构。Kappa 架构通过改进流式计算架构中的计算和存储处理过程,使实时计算和批处理能够共用一套代码,解决了 Lambda 架构中“流批分离”的复杂处理链路和维护两套代码的问题,从而实现了我们通常所说的“流批一体”。但是 Kappa 架构也存在一定缺点,无法支持海量数据存储,也无法支持高效的 OLAP 查询。
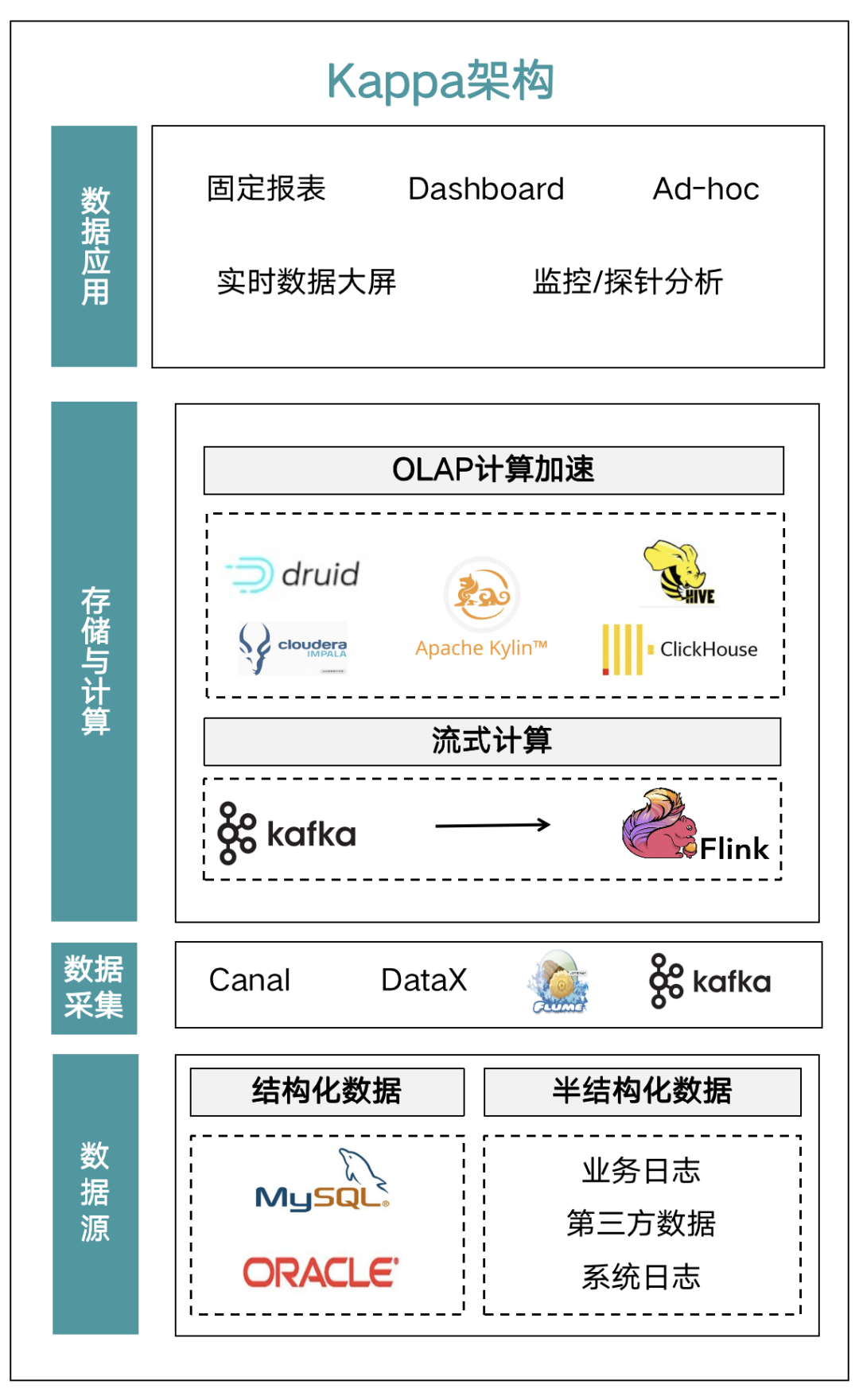
所以基于此前很多企业的 Kappa+Apache Flink(以下简称 Flink) 的实时数仓架构之上,结合了 Apache Druid(以下简称 Druid)、ClickHouse 等 OLAP 引擎做混合架构,使用 Apache Iceberg(以下简称 Iceberg) 或 Apache Hudi(以下简称 Hudi)构建 Lakehouse ,即现在常见的湖仓一体架构。但带来的一个问题就是随业务线复杂化,同时需要维护多套 AP 组件,运维成本非常高。
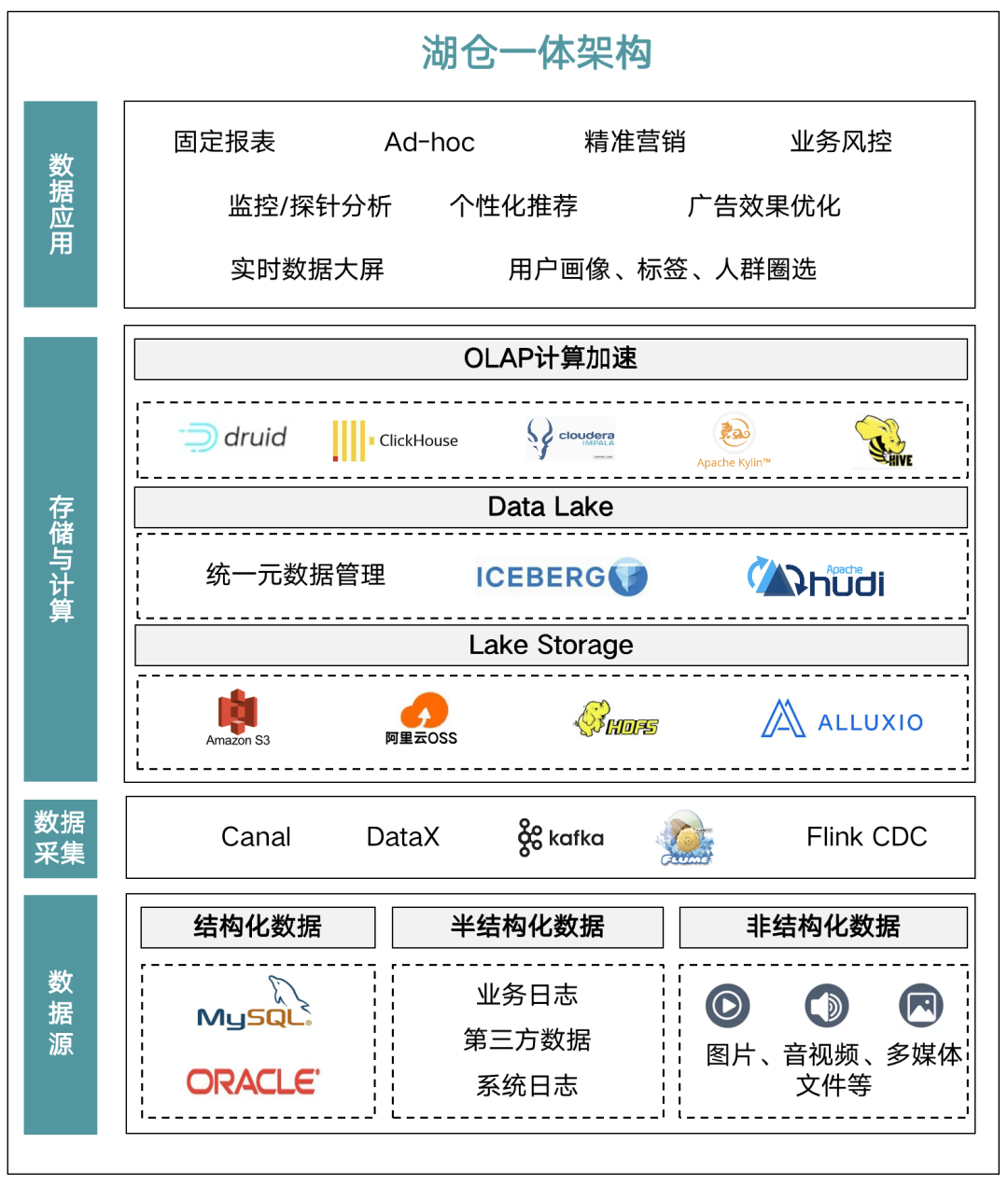
大数据技术的演进过程和行业发展趋势、数据量增长等密切相关。从最早的 BIG DATA 大数据,到后面追求高效和实时的 FAST DATA,到当下的 DATA INTELLIGENCE 数据智能。企业数字化转型历程实现了:原来数据是成本,但是现在转化成了资产,同时资产可以做到证券化,以至最终货币化的过程。换句话说,就是所有企业在生产过程中积累的、接触的所有数据都可以标准化地去衡量和创造价值,而这些价值通常是以货币来计量的。
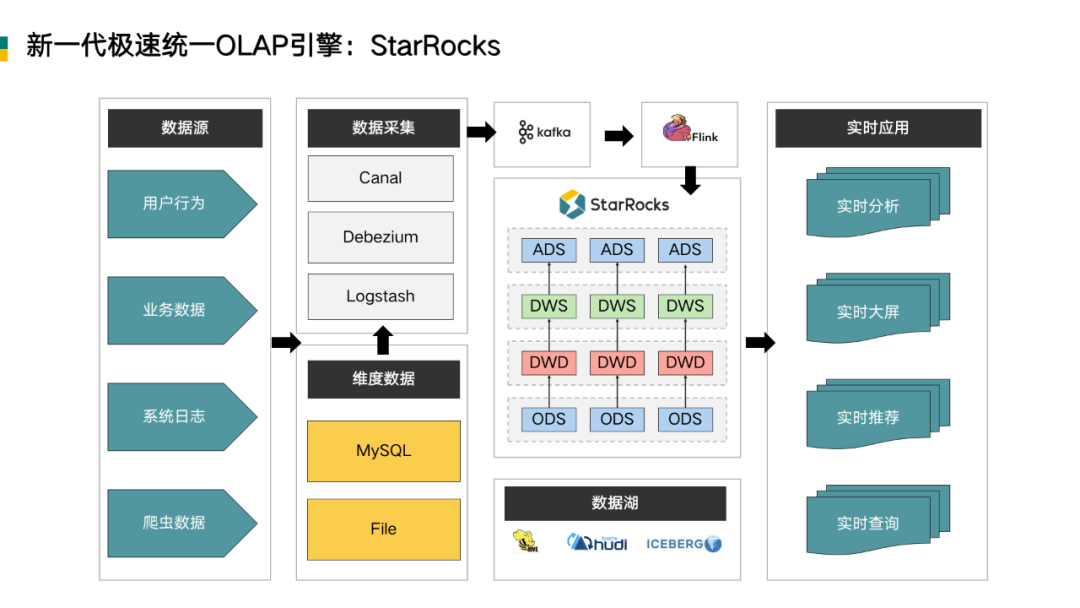
基于上述的痛点,镜舟引入 StarRocks 的理念,实现 OLAP 分层引擎的统一,与原有架构大致相同,数据通过上游的多种数据源和采集工具写入 Kafka 中,在 Flink 中进行 ETL 的转换,再实时写入到 StarRocks 中。在 StarRocks 中,我们可以使用宽星型(宽表及星型)或者预聚合模型灵活的做业务建模。
StarRocks 在大数据生态中的定位非常清晰,是一款 MPP 架构的分析型数据库。StarRocks 能够支撑 PB 级别的数据量,拥有灵活的建模方式,可以通过向量化引擎、物化视图、位图索引、稀疏索引等优化手段,去建立极速统一的分析层数据存储系统。
StarRocks 也可以支持数据变更和高并发的业务查询,同时借助 Iceberg、 Hive 外表等功能,打造出新一代的湖仓一体的架构。Iceberg 或者 Hive 中有价值的数据可以流入 StarRocks 进行关联查询,StarRocks 里的隐藏价值数据或者价值不太高的数据,也可以流向 Iceberg 或者 Hive 中 ,以低成本的方式长久保存,供未来数据挖掘使用。
#02
从 StarRocks 到镜舟,持续迭代升级的产品力
接下来我会分享基于 StarRocks 社区开发出企业级产品的过程,包括镜舟如何做持续迭代的产品升级以及服务升级。“镜舟”这个名字,来源于这样一个期待:以人为镜,以梦为舟,不负韶华,未来可期。
首先看我们所引入的 StarRocks 社区产品的一些表现。从社区来看,StarRocks 产品在近一两年之内还是取得了不少成就的。GitHub 的星数达到了 3500 多, PR数达到了 7500 多,社区的参与者超过了 7000 人,社区的贡献者超过了 200 人。到目前为止,通过企业客户或者用户在使用过程中的一些推荐,获得了 170 家以上 10 亿美金级大企业的应用。
StarRocks 是全球性的开源社区,2020 年 5 月建立,于 2021 年 9 月开源。社区月平均 PR 数高居 Open Source Database 的第二名,大幅领先 ClickHouse、Apache Doris(以下简称 Doris)、TiDB、Elasticsearch 等一系列世界知名的开源项目。
接下来说镜舟。镜舟是基于 StarRocks 开发的闭源商业化产品,产品成立在 2022 年 9 月,这次是第一次同大家见面,运营的主体是北京镜舟科技有限公司。我们的产品是基于 StarRocks 开发的商业化产品,研发过程中用到 StarRocks 开源代码,也有自身闭源的部分,在技术支持、解决方案、生态建设、售后保障等方面达到了企业级客户的要求。
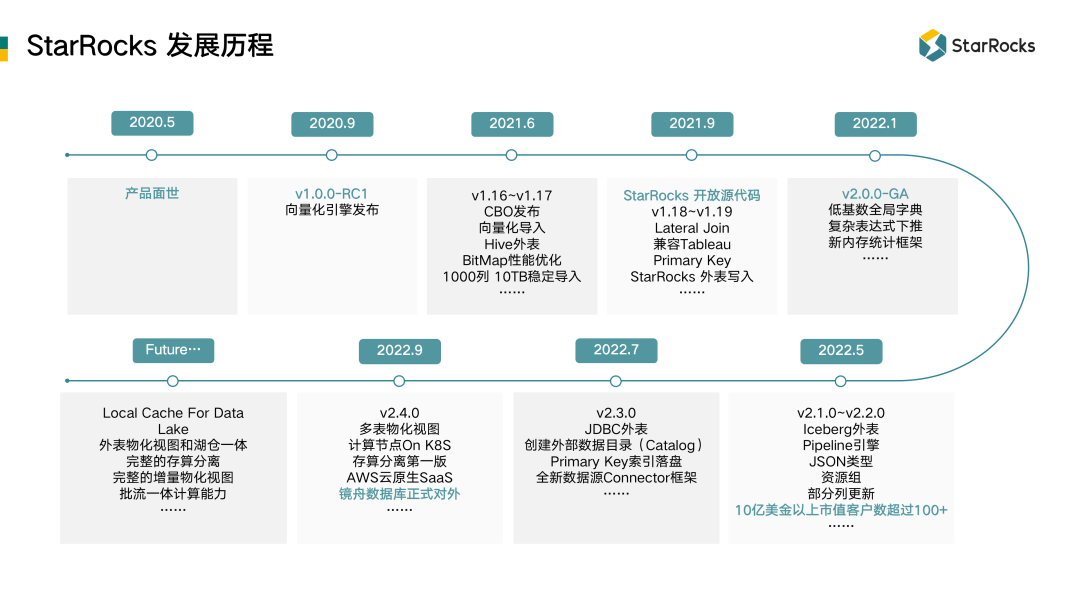
从 2020 年 5 月产品面世,到 2020 年 9 月 V1.0 正式发布。之后的一年,StarRocks 不断完善技术和产品,在 2021 年 9 月份开放源代码,之后不到 4 个月升级到 V2.0。2022 年 5 月,10 亿美金级以上的企业已经达到了 100 家。在此期间,产品又经历了多个迭代和升级,产品的功能和性能稳定性以及生态能力都有大幅度的提升。
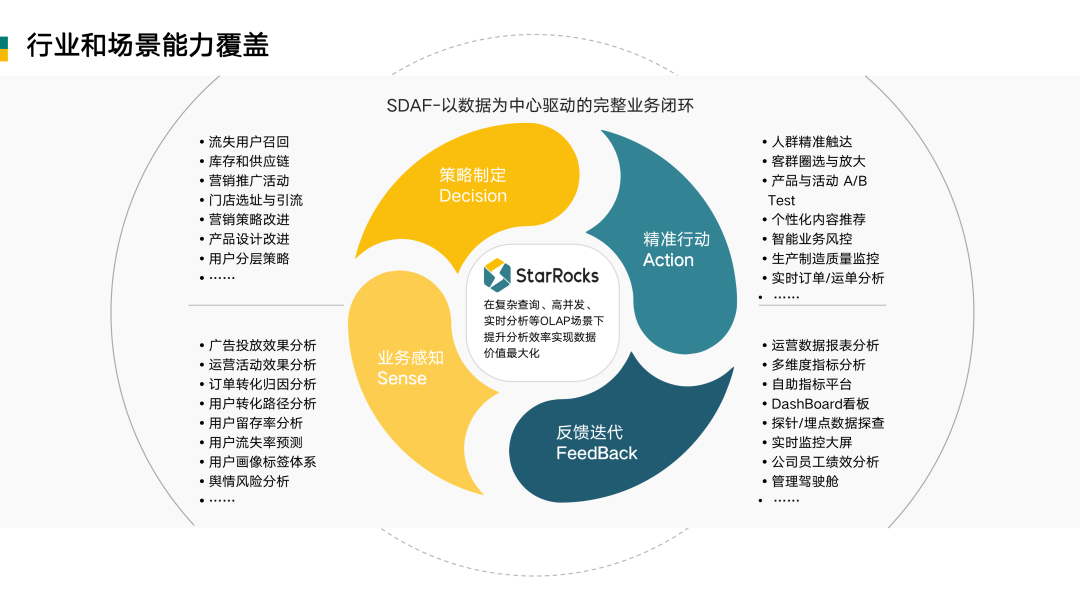
我们以怎样的视角来面向行业并提出解决方案呢?上图是最近几年神策提出的比较经典的数据分析 SDAF 方法论,我们可以用来阐述以数据为中心来驱动业务发展的场景覆盖能力。分成四个阶段:
最后是反馈迭代(Feedback):根据测试结果去做一些反馈和迭代,从而建立完整的商业和业务闭环。
金融行业:我们的很多金融客户使用 StarRocks,已经应用到很丰富的金融业务场景里,包括实时风控、实时存贷款、反欺诈、反洗钱、 CDP 用户标签体系、金融理财、保险精准营销,以及绩效分析、 HR 审计等各个系统。
零售行业:数据驱动下的“人-货-场”业务价值的升级、客户甄选和放大、实时订单分析、门店选址、供应链进销存分析、商品个性化推荐和精准营销等等。
制造行业:这个行业对于开源的接受程度目前来看是比较高的。主要聚焦于:生产质量监控和质量溯源的全过程,生产成本的分析、原材料采购预测、智能建仓,以及物流等。目前很多制造企业在尝试使用 StarRocks 去解决他们业务场景的痛点和需求。

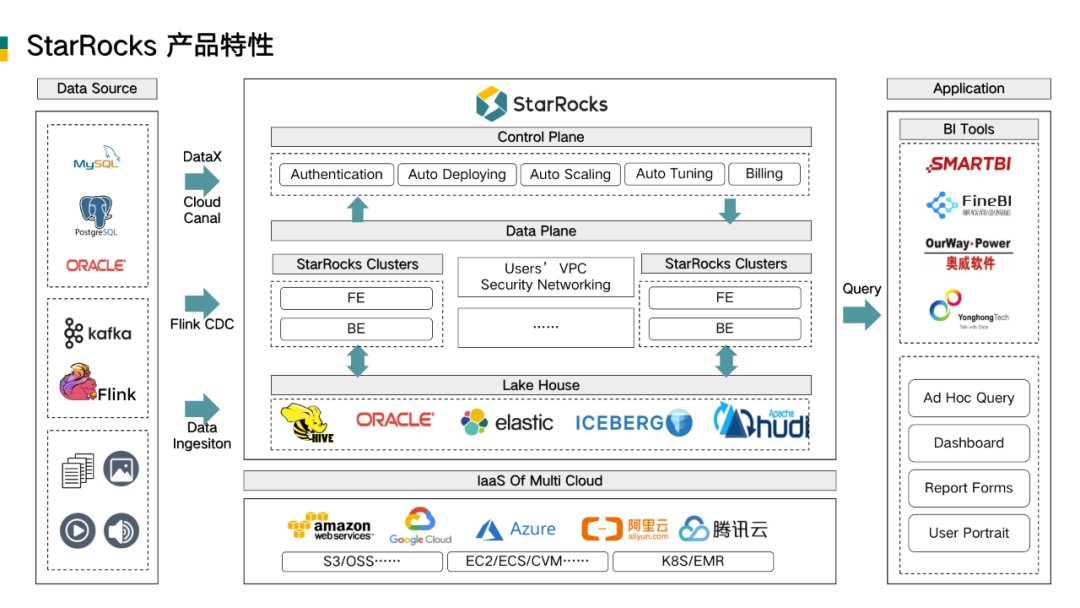
回过头来再从架构上看 StarRocks 的产品特性。在大数据生态下,StarRocks 具备比较强大的能力:
一是全面的数据摄入能力。既可以通过 DataX、Kettle、Canal 等工具支持,摄入传统的TP 类的业务数据,也可以通过 Flink Connector、Spark Connector 将流式数据导入,而对日志、图片、音视频等非结构化数据可将数据写入到湖中。
二是对湖和仓的支持。除了能够提供高性能本地化分析查询能力外, StarRocks 还可以对 MySQL、Elasticsearch、Hive 、Iceberg、Hudi 等系统通过外表方式进行联邦查询。
三是完善的云原生能力。StarRocks 不仅仅支持在不同的云平台基于云主机做私有化部署,还支持在阿里云和腾讯云的 EMR 上做半托管集群部署,以及目前在 AWS 上已上线的、未来可能在其他云厂商平台上线的全托管 SaaS 版。这样可以充分发挥云本身的优势,比如弹性伸缩、高可用,此外未来也可以结合更多的云原生能力,如数据治理(DataWorks) 。
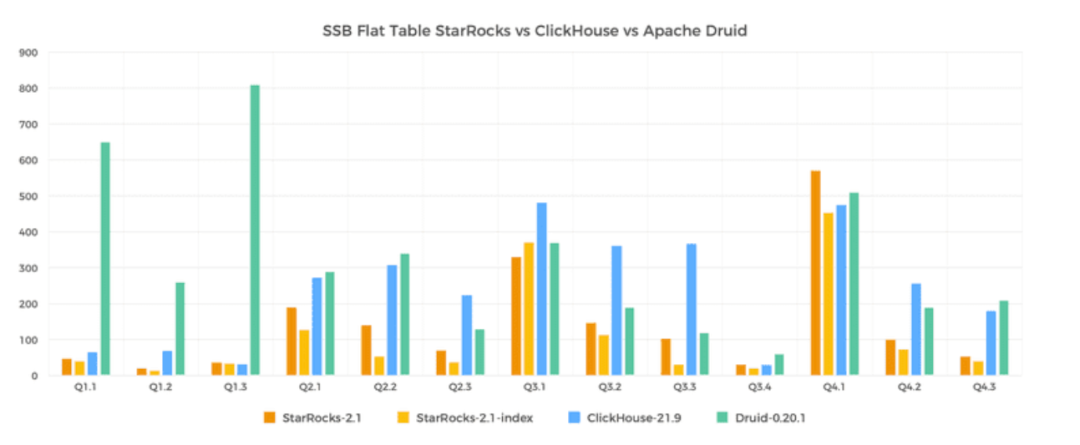
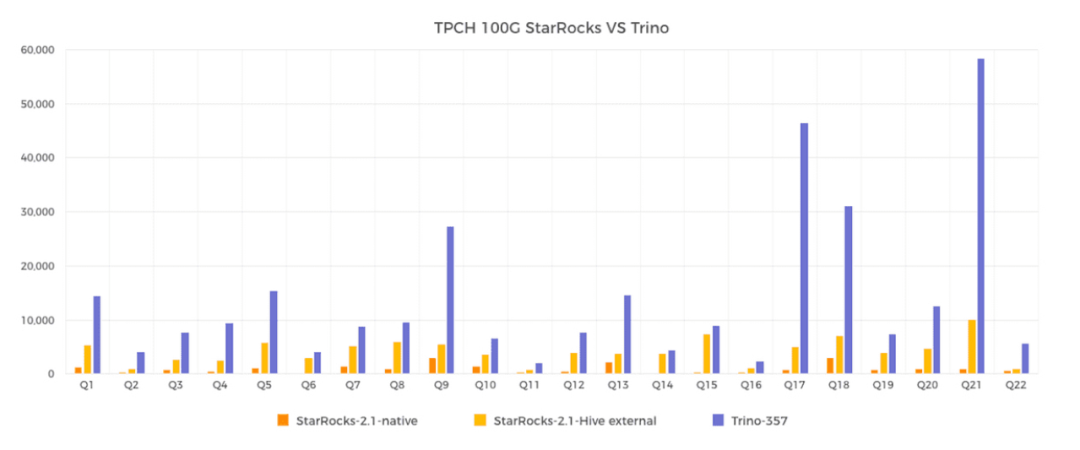
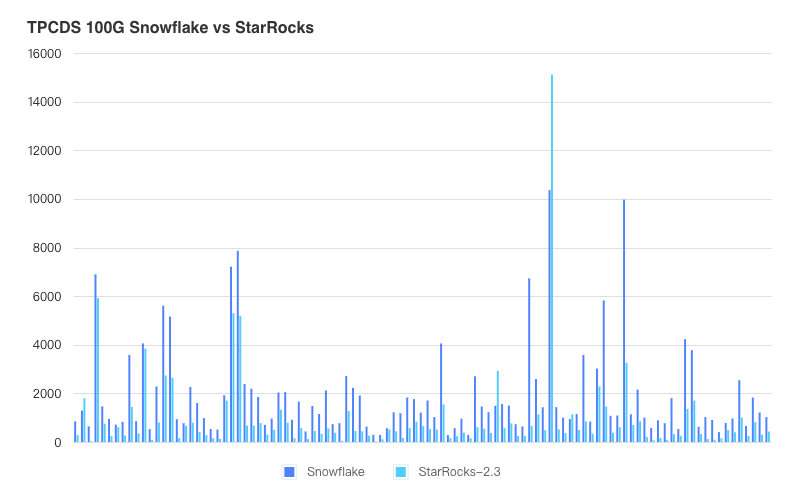
一个是 SSB 的,另外一个是 TPC-DS 的,还有 TPC-H 的。StarRocks 的性能是同类型产品的 3 倍到 8 倍,也正是因为有这样的极致性能,收获了比较好的市场口碑、比较多的用户认可。
这是前段时间 ClickBench 的一个测试:
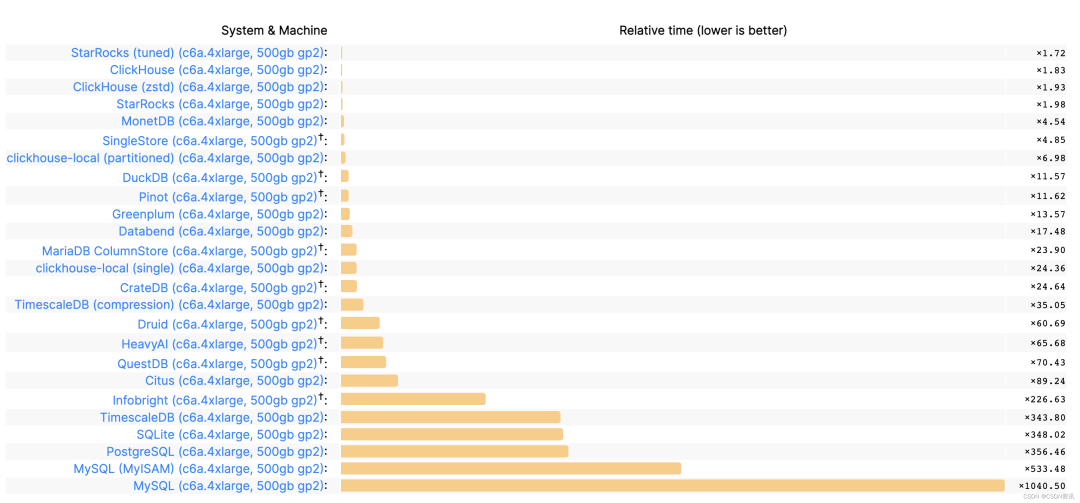
其他特性:第一是安全稳定。第二是生态相对来说比较完善,因为 StarRocks 两年多的积累,再加上各个生态合作伙伴的鼎力支持,融合了非常多上下游的产品和技术,从而能够给企业提供相对完善的解决方案。第三是完全自研自主可控,原厂有丰富的基础知识和培训,因此我们可以做到 7x24小时,全天候应急响应,节假日不休。全国在六地有研发中心和知识中心,特殊需求可以派专家去现场保驾护航。
使用 StarRocks 可以给客户带来的价值,镜舟希望始终体现在业务的最终目标上。因此,镜舟希望能够实现的产品价值是:全新的业务洞察速度,全新的业务洞察实时性,赋能更多人员进行业务洞察,构建灵活、快速响应业务变化。
以下是 StarRocks 过去一年获得的一些市场认证。在 2022 年 6 月,StarRocks 入选了 Gartner《 Market Guide for DBMS,China 》这样一个相对来说影响力比较大的报告。

上图列举了一部分代表客户,当下我们总共有 170 多家十亿美金级以上的客户,覆盖了主流的互联公司,阿里、腾讯的全系、京东、小米、美团、小红书等等,也包含垂类的游戏、电商、物流、教育、金融、制造、零售等行业头部企业。在这次年度峰会上,这些客户也会同大家去分享一下具体的技术研究思路和业务场景覆盖思路。
#03
镜舟生态战略布局与客户成功体系

我们的客户成功体系叫四位一体的客户成功体系。其目标是:通过专业的服务,让客户更好地基于我们的技术和产品持续创造业务价值,成就客户,实现共赢。我们客户成功团队分成售后 DBA 团队、解决方案中心和客户成功经理团队,同产研团队形成非常好的双轮驱动和配合。
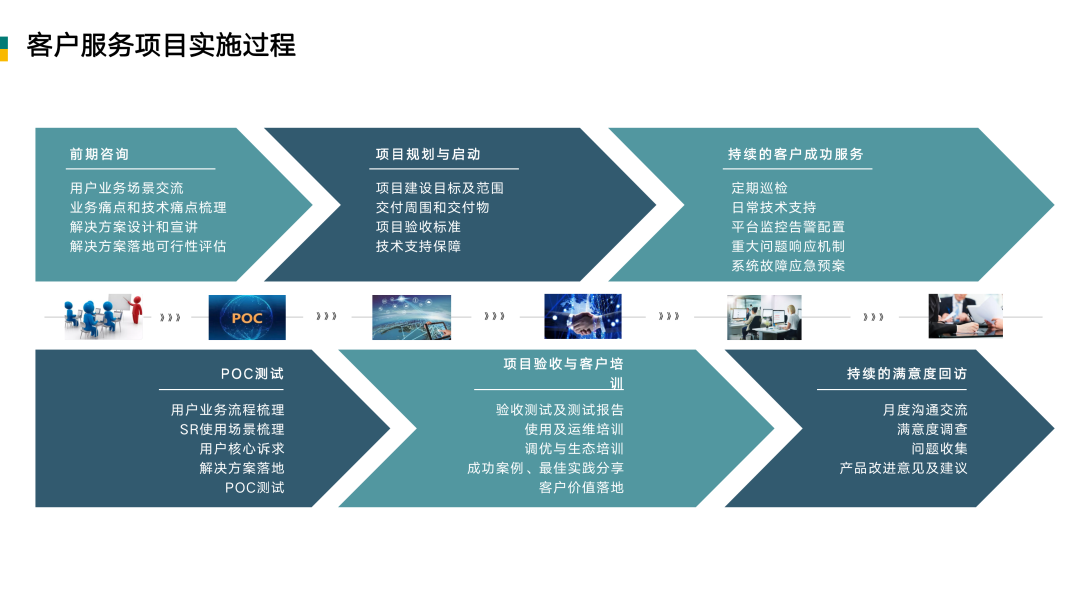
从前期咨询,到 POC 测试,到项目规划与启动,到项目验收与客户培训,到持续的客户成功服务,到持续的满意度回访,再回过头来,去找新的业务来去做前期咨询……不断重复这个过程。
在这过程中,一方面同客户一起成功,另一方面还可以从客户的具体应用场景中分析新的需求,解决新的问题,从而形成我们社区和商业版的新 feature。
所以毫不夸张地讲,就 StarRocks 面世到现在,以及镜舟做企业版这么长时间以来,所有产品功能的 feature 没有一个是闭门造车出来的,全都是由同客户的互动、同客户的交流,同客户的业务场景,不断尝试最后创造出来的。我们认为这样才叫做真正的“客户成功”。
这里列了一下我们的客户成功体系,做企业级服务的标准化内容和流程:
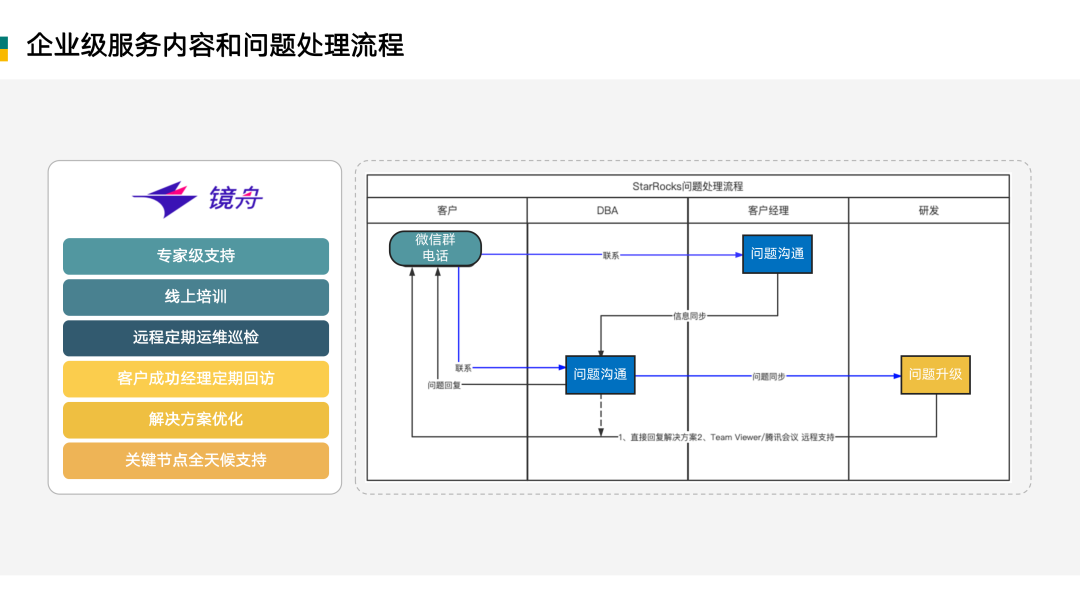
无论 StarRocks 还是镜舟,能走到现在,都与用户和客户的共创分不开。本次分享中讲到的各行业典型场景,StarRocks Summit Asia 2022 都请到了相关企业做分享,讲述了他们在这些场景里面运用 StarRocks 的一些方法和经验,相关内容会陆续发布,欢迎关注!
回看 StarRocks Summit Asia 2022
关于 StarRocks
StarRocks 创立两年多来,一直专注打造世界顶级的新一代极速全场景 MPP 数据库,帮助企业建立“极速统一”的数据分析新范式,助力企业全面数字化经营。
当前已经帮助腾讯、携程、顺丰、Airbnb 、滴滴、京东、众安保险等超过 170 家大型用户构建了全新的数据分析能力,生产环境中稳定运行的 StarRocks 服务器数目达数千台。


StarRocks 技术内幕:
👇 阅读原文回看 StarRocks Summit Asia 2022
