




各位新朋友~记得先点蓝字关注我哦~
情景再现

为了确定是不是真的宕机了,随后看了一下pg进程,发现确实不存在postgres相关数据库进程。

$ tail -50f $PGDATA/log/postgresql-2021-03-30_104942.csv
错误日志显示,NO space left on divice,pg_wal目录下没有空余的设备空间了

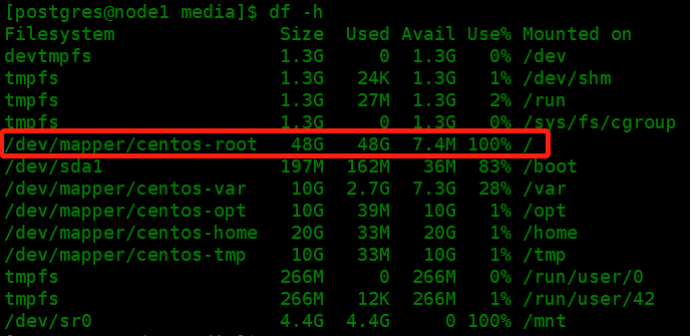
查看系统磁盘空间确认磁盘空间信息,证实磁盘空间已经撑满了
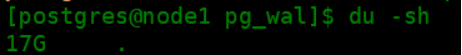
1、查看wal日志配置
$ cat $PGDATA/postgresql.conf | grep max_wal_size或者$ cat $PGDATA/postgresql.auto.conf | grep max_wal_size

2、查看归档配置
$ cat $PGDATA/postgresql.conf | grep archive

$ ls -l pgdata/archivedir/

操作步骤
$ mkdir -p pgdata/archivedir$ pg_ctl start
$ psqlpostgres# select pg_switch_wal();
$ du -sh289M .
实践总结
查看是否是主备断连导致的主库日志堆积(包括复制槽的使用) 如果主备关系没有问题或者只是单点的实例,那就检查归档是否失败,查看归档目录的文件时间及连续性,或者通过视图pg_stat_archiver判断归档状态
postgres=# select last_archived_wal,last_archived_time,failed_count,last_failed_time from pg_stat_archiver;-[ RECORD 1 ]------+--last_archived_wal | 000000010000000000000024last_archived_time | 2021-03-30 16:59:33.788265+08failed_count | 0last_failed_time |
美创是国内领先的数据库服务提供商。服务团队拥有PG ACED 1名、Oracle&PG ACE 3人、DSI智库专家5名、DSMM测评师7名、OCM 20余人、数十名Oracle OCP、MySQL OCP、TDSQL TCP、OceanBase OBCP、TiDB PTCP、达梦 DCP、人大金仓、红帽RHCA、中间件weblogic、tuxedo、CISP-DSG、CISSP、CDGA、CDPSE、CZTP、CDSP等认证人员,著有《DBA攻坚指南:左手Oracle,右手MySQL》,《Oracle数据库性能优化方法和最佳实践》,《Oracle内核技术揭秘》,《Oracle DBA实战攻略》等多本数据库书籍。运维各类数据库合计5000余套,精通Oracle、MySQL、SQLServer、DB2、PostgreSQL、MongoDB、Redis、TDSQL、OceanBase、达梦、人大金仓等主流商业和开源数据库。美创拥有完善的运维体系和人员培养体系,并同时提供超融合、私有云整体服务解决方案、数据安全咨询及运营服务方案等,已为金融、政府、企业、能源等多个行业的客户提供量身定制的各类服务,赢得了客户的高度赞誉和广泛认可。

文章转载自新运维新数据,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
