




MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。这与Oracle的索引结构相似,比较好理解。那么,常用的Innodb聚集索引结构是怎样的呢?
InnoDB的数据文件本身(.ibd文件)就是索引文件。在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
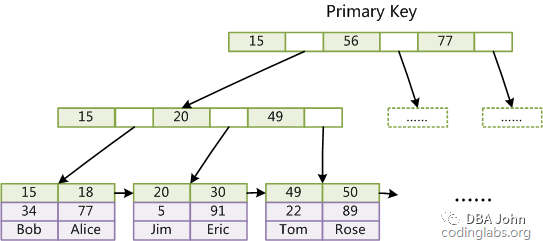
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
可能上面的描述还不够直观,我又翻阅了《MySQL技术内幕:Innodb存储引擎》一书,在其第172页找到了如下图片。
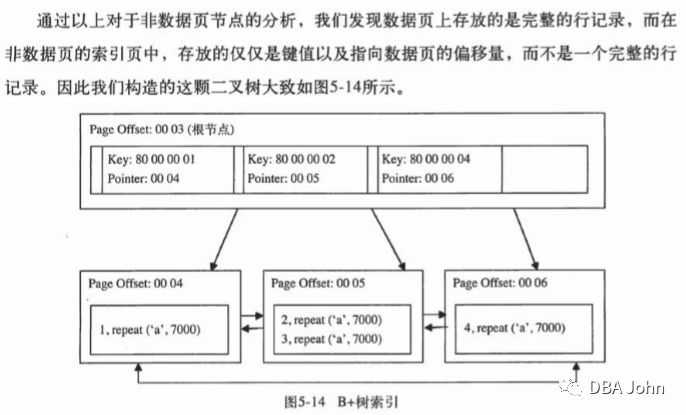
可以看出,聚集索引非叶子节点中,Pointer(索引键值)指向的是ibd文件的Page Offset(File Header中的FIL_PAGE_OFFSET),这样就定位到数据块在ibd文件中的偏移量了。
接下来,首先确定该块是否在Innodb buffer pool中,我在这里仅分析不在Innodb buffer pool的情况:
每个page的头部,有Fil Header,从Fil Header中的FIL_PAGE_SPACE可以知道space id,然后通过函数调用buf_read_page(在D:\source_code\mysql-5.7.12\storage\innobase\include\buf0rea.cc中)-->buf_read_page_low-->fil_io(在D:\source_code\mysql-5.7.12\storage\innobase\fil\fil0fil.cc中)-->fil_node_prepare_for_io-->fil_node_open_file-->os_file_read(在D:\source_code\mysql-5.7.12\storage\innobase\os\os0file.cc中),
找到数据块,将它读入Innodb buffer pool,然后通过Page Directory(页目录)进行二分查找,来定位到行记录,这个过程中需要使用Record Header中的next_record。
参考链接:
http://blog.codinglabs.org/articles/theory-of-mysql-index.html
https://www.cnblogs.com/wade-luffy/p/6289917.html
